Dynamic Affective Memory Management for Personalized LLM Agents
-
ArXiv URL: http://arxiv.org/abs/2510.27418v1
-
Author: Yueyan Li
-
Publishing Institution: Beijing University of Posts and Telecommunications
TL;DR
This paper proposes a dynamic emotional memory management system called DAM-LLM. By introducing a Bayesian-inspired update mechanism and the concept of memory entropy, it enables an intelligent agent to autonomously maintain a dynamically updated memory database, addressing the problems of redundancy, obsolescence, and poor consistency in traditional static memory, thereby providing more personalized emotional interactions.
Key Definitions
This paper proposes or adopts the following core concepts:
-
Confidence-Weighted Memory Units: The core data structure proposed in this paper, used to encapsulate a user’s sentiment toward a specific aspect of a specific entity. It does not record isolated facts; instead, it represents user sentiment as a dynamically updated probability distribution (or confidence distribution), integrating new observed evidence through a Bayesian update mechanism.
-
Bayesian-Inspired Update Mechanism: An algorithm for integrating new observed data. It treats the existing sentiment confidence in a memory unit as a “prior belief” and new user input as “observed evidence,” then computes a “posterior belief” through a weighted average to smoothly update memory. Its core formula is: $C_{\text{new}}=(C\times W+S\times P)/(W+S)$, where $C$ is the old confidence, $W$ is the old weight, $S$ is the strength of the new evidence, and $P$ is the confidence of the new evidence.
-
Belief Entropy: An indicator used to quantify the uncertainty of a single memory unit. It is defined as $H(m)=-\sum_{k\in{\text{pos,neg,neu}}}p_{k}\log_{2}p_{k}$, where $p_k$ is the normalized confidence score for sentiment polarity $k$. Low entropy indicates high certainty, while high entropy indicates high uncertainty or “confusion.” Belief entropy is the core signal driving memory compression and optimization.
-
Entropy-Driven Compression: An algorithm designed to combat memory bloat. During retrieval, it maximizes the information density of the memory bank by pruning and merging low-value or outdated observations. This process is driven by the goal of minimizing global belief entropy, including merging similar memories and deleting high-entropy, low-weight “noise” memories.
Related Work
At present, mainstream research in the field of emotional dialogue focuses on using methods such as reinforcement learning to enable agents to dynamically adjust emotional strategies during real-time interaction, thereby achieving better interaction outcomes. However, these works generally overlook how to persistently store, evolve, and effectively utilize users’ long-term emotional history, failing to form a coherent memory system with personalized cognition.
In the field of agent memory management, existing architectures are mostly based on Retrieval-Augmented Generation (RAG). Although some work has improved this by using hybrid retrieval, optimizing the retrieval process (such as Selfmem), or building external memory banks (such as MemoryBank), two major bottlenecks remain:
- Static and incoherent memory: Traditional methods store interactions as a collection of isolated facts and cannot synthesize multiple interactions into an evolving understanding of the user, leading to contradictions when the user’s attitude changes.
- Memory bloat and noise: Storing all interactions indiscriminately causes the memory bank to grow without bound, increasing retrieval latency and computational overhead while also introducinga large amount of noise, making it difficult to retrieve key information—the “needle in a haystack” problem.
This paper aims to address the above issues, especially how to dynamically model and manage long-term emotional memory, in order to overcome the limitations of traditional RAG architectures in handling emotional fluctuations and to maintain memory consistency and efficiency.
Method
This paper proposes an agent framework for emotional dialogue called DAM-LLM, whose core is dynamic emotional memory management. The framework optimizes the memory system by minimizing global belief entropy, transforming memory management from passive storage into an active cognitive process.
System Architecture
DAM-LLM consists of three core components: a central Master Agent, a two-stage hybrid retrieval module, and a distributed memory unit network. Together, these form a closed-loop cognitive architecture. The system drives dynamic memory optimization by minimizing the global belief entropy $\sum_{m\in M}H(m)$, maximizing certainty in modeling user preferences. The Master Agent uses belief entropy as a global perceptual signal to coordinate Bayesian memory updates, semantic retrieval, and entropy-driven compression.
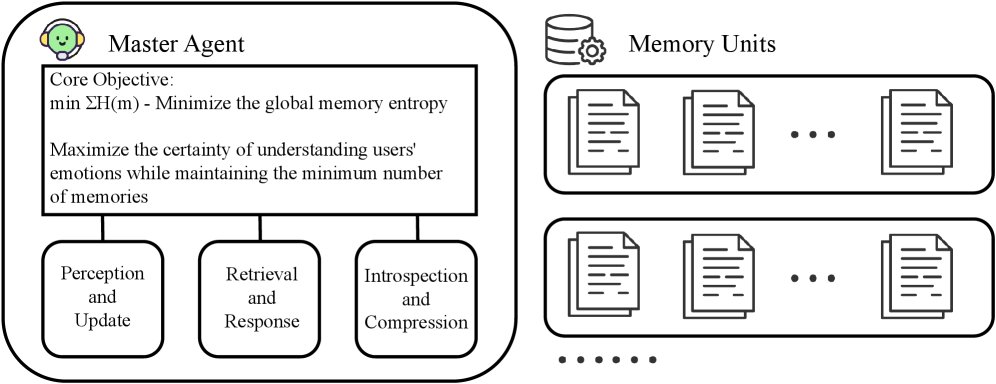
DAM-LLM Agent
The collaborative workflow of the system is completed by multiple agents, forming a complete closed loop from problem understanding to memory operations and response generation.
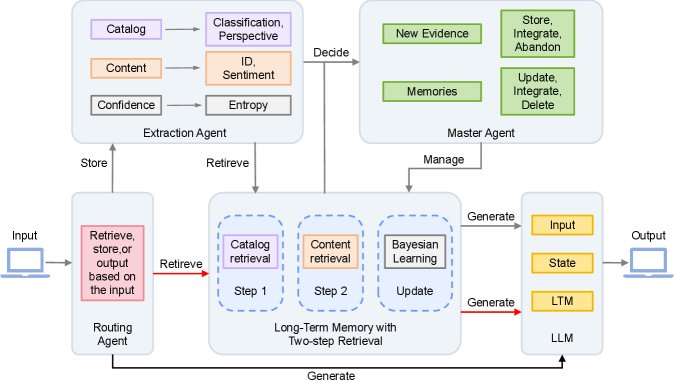
-
Input Routing: The routing agent analyzes user intent and decides whether the current input should trigger Store, Retrieve, or direct Generate response.
-
Evidence Analysis and Processing: When user input $x_t$ needs to be recorded, the Extraction Agent parses it into structured emotional information in the form $\mathrm{\textit{E}\text{-}Agent}(x)\rightarrow E,Q,C,S$, which respectively represent the emotional description, retrieval query, sentiment confidence vector, and evidence strength.
-
Memory Update and Compression: Based on the current state of the memory bank, the Master Agent processes new evidence:
- Update: Integrate new evidence into existing memory units through a Bayesian-inspired mechanism, dynamically adjust sentiment confidence, and refresh the memory unit’s summary description.
- Merge: Identify and merge multiple memory units about the same object but different aspects to form a more comprehensive, lower-entropy memory.
- Delete: For memory units that consistently exhibit high entropy and low weight, the system treats them as “noise” or outdated information and deletes them, achieving active “forgetting.”
Memory Unit
The memory unit is the core of emotional memory, and its innovative design lies in transforming discrete emotional observations into a continuously updated confidence profile.
Data Structure Design
Each memory unit contains multiple fields for structured storage of emotional information.
| Field Name | Description |
|---|---|
| \(object_id\) | Object ID |
| \(object_type\) | Object type |
| \(aspect\) | Aspect |
| \(sentiment_profile\) | Sentiment profile (confidence scores) |
| $H$ | Belief entropy |
| \(summary\) | Summary |
| \(reason\) | Reason |
Bayesian-Inspired Update Mechanism
This is the key to enabling self-learning in the memory unit. The mechanism simulates Bayesian updating through a weighted averaging process, with the formula:
\[C_{\text{new}}=(C\times W+S\times P)/(W+S), \quad W_{\text{new}}=W+S\]Among them, $C$ is the current sentiment confidence (prior), $W$ is its weight; $S$ is the strength of the new observed evidence, and $P$ is its confidence. This mechanism allows high-strength evidence to shape the sentiment profile more effectively while remaining robust to low-strength incidental remarks, thereby enabling smooth memory evolution.
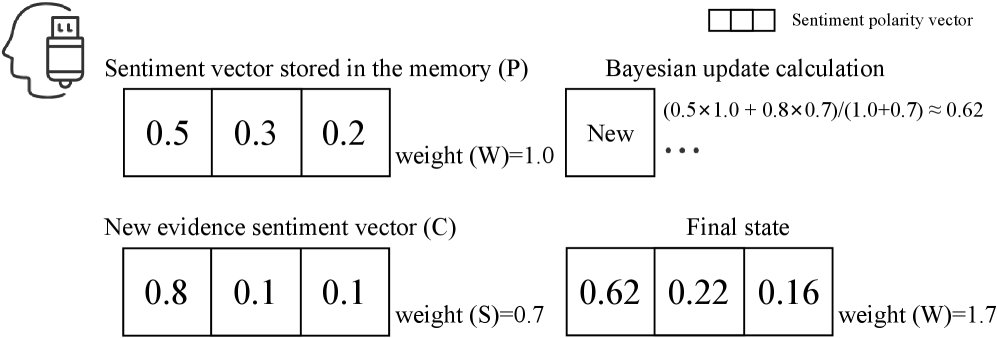
Cognitive Belief Entropy
Belief entropy $H(m) = -\sum_{k\in{\text{pos,neg,neu}}}p_{k}\log_{2}p_{k}$ is a unified metric for measuring the cognitive certainty of a memory unit.
- Low entropy: Indicates that the system is highly certain about a certain emotional state; this is a “healthy” memory.
- High entropy: Indicates that the system is in an uncertain or confused state; this is an “unhealthy” memory that needs optimization.
The Master Agent’s goal is to minimize the total entropy of all memory units.
Two-Stage Hybrid Retrieval
To address the semantic drift problem in traditional vector retrieval, this paper designs a two-stage hybrid retrieval mechanism that is naturally aligned with the structure of memory units.
- Stage 1: Metadata-Based Filtering:
- The LLM parses the user query and extracts standardized retrieval keys, such as \(object_type\) and \(aspect\).
- These metadata are used for exact matching to quickly filter out a smaller candidate memory set, greatly narrowing the search scope.
- Stage 2: Semantic Re-Ranking:
- Within the candidate set, the cosine similarity between the semantic vector of the user query and the summary vector of each candidate memory is computed.
- The candidate memories are re-ranked according to the similarity scores, and the most relevant Top-K results are returned.
This “coarse filtering + fine ranking” process decouples the classification task from content retrieval. It uses lightweight metadata for efficient filtering and performs computation-intensive semantic matching only on a highly relevant subset, thereby ensuring retrieval accuracy and scalability.
Experimental Conclusions
Dataset and Implementation
To evaluate the system’s performance in emotional scenarios, this paper constructed a multi-turn dialogue dataset called DABench, focusing on user emotional expression and emotional changes. The dataset includes 2,500 observation sequences, 100 sessions (1,000 turns in total) of simulated user interactions, and 500 query-memory pairs. The experiments used Qwen-Max as the base LLM and Text-Embedding-V1 as the text embedding model.
Memory Unit Validation
- Functional Validation: The experiments show that the memory unit can:
- Accumulate emotions during continuous interactions and build a coherent emotional profile (Figure a).
- Resolve contradictions through dynamic re-weighting when user viewpoints conflict, enabling smooth emotional transitions (Figure b).
- Provide different levels of confidence scores according to the intensity of emotional expression, enabling fine-grained evaluation (figure below).
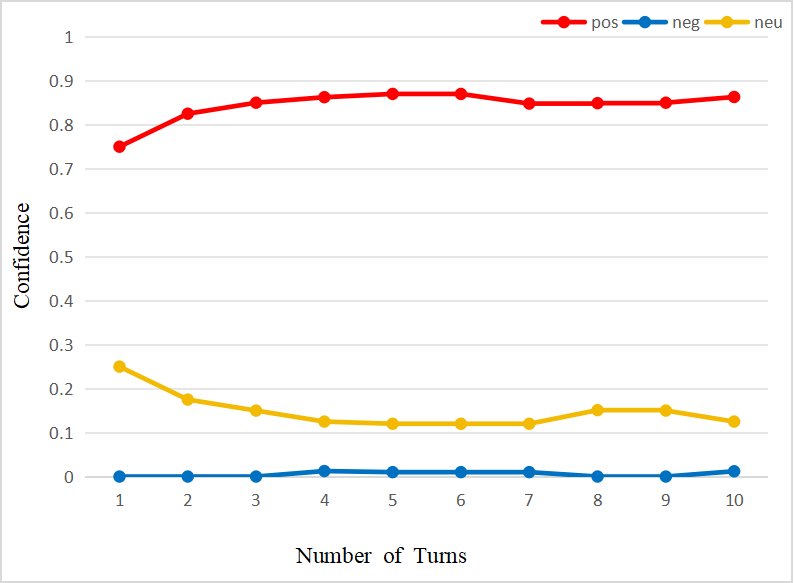
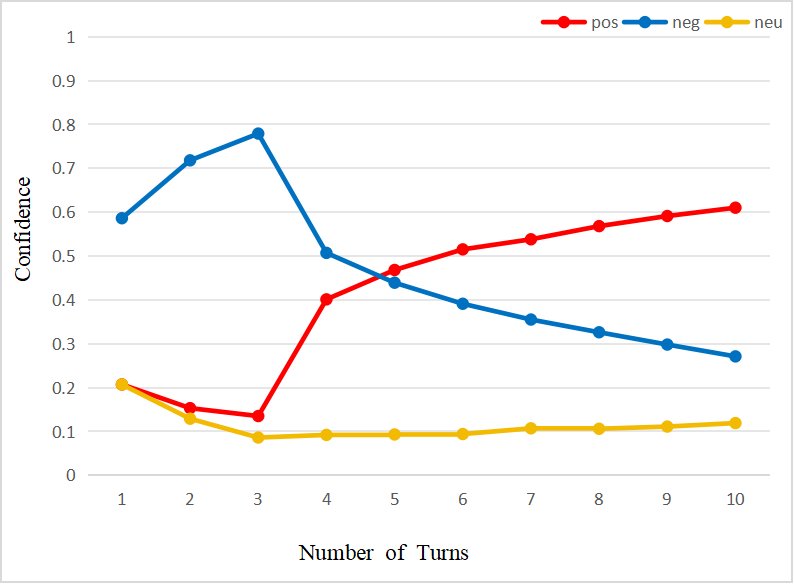
<img src="/images/2510.27418v1/x4.jpg" alt="Figure illustration" style="width:85%; max-width:600px; margin:auto; display:block;">
- Stability Analysis: Thirty observations of “coffee (taste)” show that the system quickly forms an initial confidence level within about 15 interactions, after which the confidence curve gradually converges and stabilizes as evidence accumulates. This process also verifies that the system can effectively distinguish and independently store different aspects of the same object, such as the taste and packaging of coffee.
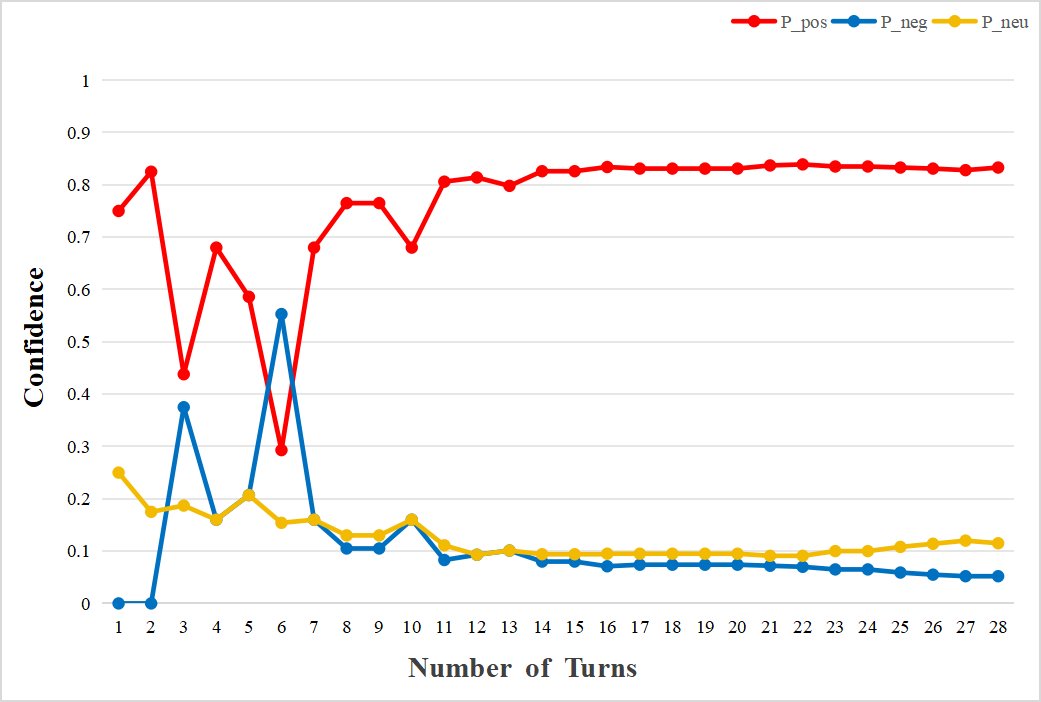
Compression Algorithm Validation
- Memory Growth Control: Through an ablation study comparing systems with and without the Bayesian update mechanism, after processing 500 dialogues, the memory size of the system without the update mechanism grew linearly, while DAM-LLM achieved a memory compression rate of 63.7% to 70.6%, with the number of memory units remaining stable at around 130-140, effectively suppressing memory bloat.
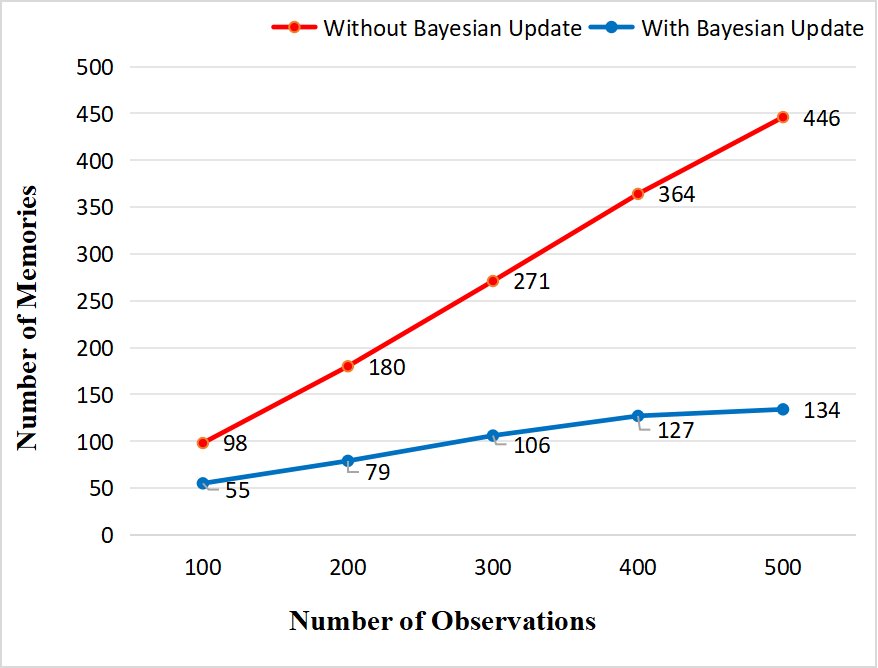
System Performance Evaluation
The system was evaluated from six dimensions using the LLM-as-a-judge (GPT-4) method.
| Dimension | Baseline Model | DAM-LLM (This Paper) |
|---|---|---|
| Accuracy (AC) | 4.31 | 4.35 |
| Logical Coherence (LC) | 4.02 | 4.28 |
| Memory Reference Rationality (RMR) | 3.86 | 4.25 |
| Emotional Resonance (ER) | 3.52 | 4.21 |
| Personalization (Pers.) | 3.56 | 4.33 |
| Language Fluency (LF) | 4.67 | 4.54 |
The experimental results show that, while using only about 40% of the memory, DAM-LLM significantly outperforms the baseline system in the dimensions of emotional resonance and personalization. This advantage is especially pronounced in scenarios involving large amounts of redundant memory or complex emotional evolution.
Summary
The DAM-LLM framework and its dynamic memory system proposed in this paper have been proven efficient and effective in experiments, providing a new direction for the development of memory architectures for emotional dialogue intelligent agents.