Dual-Weighted Reinforcement Learning for Generative Preference Modeling
-
ArXiv URL: http://arxiv.org/abs/2510.15242v1
-
Author: Han Fang; Licheng Yu; Julian Katz-Samuels; Shuang Ma; Manaal Faruqui; Karishma Mandyam; Karthik Abinav Sankararaman; Yuanhao Xiong; Hejia Zhang; Vincent Li; and 14 others
-
Publisher: Carnegie Mellon University; Meta Superintelligence Labs
TL;DR
This paper proposes a new framework called Dual-Weighted Reinforcement Learning (DWRL), which combines Chain-of-Thought (CoT) reasoning with the Bradley-Terry (BT) model through a dual-weighted reinforcement learning objective that preserves the inductive bias of preference modeling, thereby effectively improving the performance of generative preference models on general tasks without relying on verifiable rewards.
Key Definitions
The core of this paper is to design a better training framework for generative preference models (GPMs), and it introduces the following key concepts:
- Generative Preference Models (GPMs): An extension of traditional scalar preference models. GPMs do not directly output preference scores; instead, they first generate a piece of “thought” or “judgment” (i.e., Chain-of-Thought), and then make a final preference decision based on that thought (such as a score or a choice).
- Dialog-based GPM: A GPM implementation proposed in this paper. It reformulates preference modeling as a two-turn dialogue: the model is first asked to generate a judgment about the candidate response (thought), and then asked to score that response. This design decouples the thinking process from the scoring process, making them easier to optimize separately.
- Dual-Weighted Reinforcement Learning (DWRL): The core algorithm proposed in this paper. It introduces two complementary weights into GPM training by approximating the maximum-likelihood objective of the BT model, aiming to combine reinforcement learning with the inductive bias of preference modeling.
- Instance-wise Misalignment Weight: The first weight in DWRL. This weight is computed at the instance level (i.e., for each preference pair) and is used to emphasize undertrained sample pairs whose model predictions are inconsistent with human preferences; its value equals the probability that the model predicts the wrong preference.
- Group-wise (Self-normalized) Conditional Preference Score: The second weight in DWRL. This weight serves as the reward signal in reinforcement learning and is used to encourage the model to generate “thoughts” that lead to the correct preference judgment. It is obtained by self-normalizing the conditional preference scores of a group of sampled thoughts.
Related Work
At present, for tasks with verifiable answers (such as math and programming), researchers have successfully scaled Chain-of-Thought (CoT) training for large language models through Reinforcement Learning from Verifiable Rewards (RLVR). However, extending this approach to general tasks where answers cannot be automatically verified (and whose data are usually paired human preferences) remains a challenge.
Such tasks typically use the Bradley-Terry (BT) model to learn a preference model that assigns higher scores to responses with stronger preferences. Inspired by CoT, recent work has proposed Generative Preference Models (GPMs), allowing the model to generate a judgmental thought before scoring. Early GPMs relied on supervised training with high-quality thought data distilled from stronger models, which limited their applicability. Later work attempted to treat GPMs as purely generative tasks and optimize them with RLVR, but this approach often discards the valuable preference-modeling inductive bias in the BT model, resulting in performance that can even be worse than a simple BT model.
The central question this paper aims to address is: how can we design a training framework that does not rely on external supervised thought data, yet effectively combines the advantages of CoT reasoning with the intrinsic structure (inductive bias) of preference modeling, so as to train a more powerful GPM on general preference data?
Method
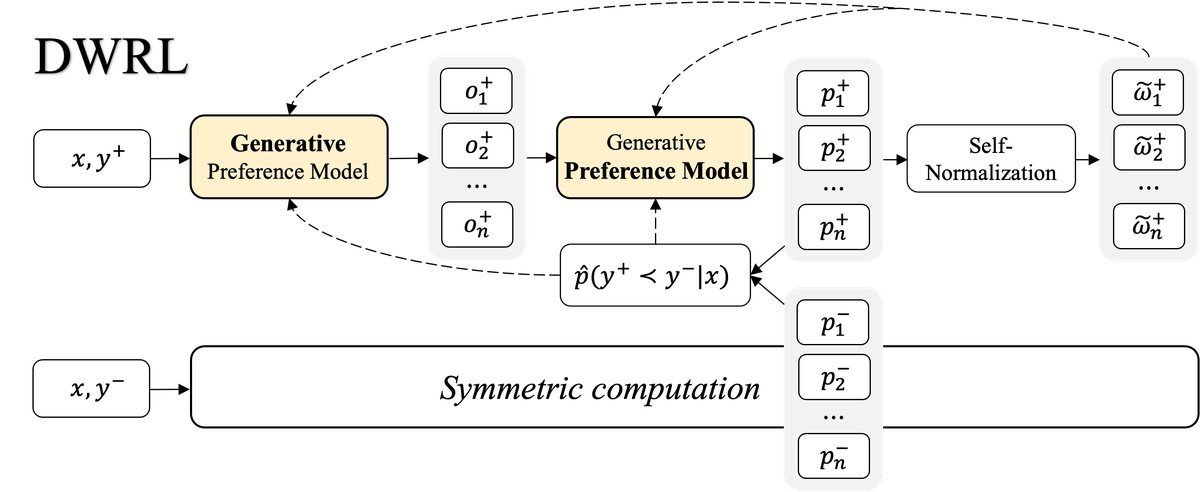
The core method of this paper is Dual-Weighted Reinforcement Learning (DWRL), built on a novel dialog-based GPM structure, with the goal of combining the exploration capability of reinforcement learning with the structural advantages of traditional preference modeling.
Dialog-based Generative Preference Model
To better decouple the “thought generation” process from the “preference scoring” process, this paper proposes a dialog-based GPM. Its workflow is shown in the figure below:

- Generate thought: Given an input \(x\) and a candidate response \(y\), the model is first prompted to generate a judgment or thought about the quality of \(y\), denoted as \(o\).
-
Score the response: The model is then asked to score \(y\) based on the generated thought \(o\). Specifically, instead of having the model generate a score directly, the output probability $$p(a x,y,o)$$ on a specific answer token (for example, answering “Yes” to the question “Is this response good? A: Yes, B: No”) is computed and used as the final preference score.
| This multi-turn dialogue format ensures that thought comes before scoring, allowing \(o\) to be treated as a latent variable and enabling an independent optimization objective for it. The entire process can obtain both the thought probability $$p(o | x,y)\(and the scoring probability\)p(a | x,y,o)$$ in a single forward pass. |
Dual-Weighted Reinforcement Learning (DWRL)
The goal of DWRL is to directly optimize the maximum log-likelihood of the GPM under the BT model framework. For a preference pair \((y+, y-)\), the preference probability is defined as:
\[p(y^{+}\succ y^{-}\mid x)=\frac{\mathbb{E}_{o^{+}}[p(a\mid x,y^{+},o^{+})]}{\mathbb{E}_{o^{+},o^{-}}[p(a\mid x,y^{+},o^{+})+p(a\mid x,y^{-},o^{-})]}\]Directly optimizing this objective is difficult because it involves a ratio inside an expectation, which cannot be handled simply with Jensen’s inequality. Therefore, this paper uses Monte Carlo methods to directly estimate the gradient of the loss function $l(\phi)=-\log p(y^{+}\succ y^{-}\mid x)$.
The derived gradient is:
\[\nabla_{\phi}l(\phi)=-\left(\frac{p^{-}}{p^{+}+p^{-}}\right)\bigl(\nabla_{\phi}\log p^{+}-\nabla_{\phi}\log p^{-}\bigr)\]where $p^{+} = \mathbb{E}_{o^{+}}[p(a \mid x,y^{+},o^{+})]$ and $p^{-} = \mathbb{E}_{o^{-}}[p(a \mid x,y^{-},o^{-})]$. This gradient can be decomposed into two key parts, thereby forming the “dual-weighted” mechanism of DWRL.
Weight 1: Instance-wise Misalignment Weight
The first term in the gradient formula, $\frac{p^{-}}{p^{+}+p^{-}}$, is exactly the probability that the model predicts $y^-$ to be better than $y^+$, i.e., $p(y^{+}\prec y^{-}\mid x)$. The paper defines this as the instance-wise misalignment weight. Its role is: when the model’s prediction is inconsistent with human preference (i.e., it incorrectly believes $y^-$ is better), this weight becomes larger, thereby amplifying the gradient update for this “hard sample” and prompting the model to correct its mistake.
Weight 2: Group-wise Conditional Preference Score
The second term in the gradient formula, $\nabla_{\phi}\log p^{+}-\nabla_{\phi}\log p^{-}$, involves the gradient of a log expectation and is difficult to compute directly. Through a series of derivations and Monte Carlo approximations, the paper transforms it into a form that separately optimizes thought generation and scoring. Among these, the part used to reward thought generation is a self-normalized weight:
\[\tilde{\omega}_{i}=\frac{\pi_{\phi}(a\mid x,y,o_{i})}{\sum_{j=1}^{n}\pi_{\phi}(a\mid x,y,o_{j})}\]This is called the group-wise (self-normalized) conditional preference score. For a set of thoughts ${o_1, …, o_n}$ generated from a candidate answer \(y\), if a certain thought $o_i$ can lead the model to assign a higher preference score, then its weight $\tilde{\omega}_{i}$ will be larger. This weight serves as a reward signal for thought $o_i$ in reinforcement learning, encouraging the model to generate “good” thoughts.
In the end, DWRL’s gradient estimator integrates these two weights, optimizing both the preference scoring and thought generation components at the same time.
Alternating Update Strategy
To improve training stability, DWRL adopts an alternating optimization strategy:
- Optimize preference scoring: Fix the sampled thought \(o\), and use the weighted objective function (Equation 14) to update the model parameters so that it can score more accurately.
- Update weights: Recompute the misalignment weights and conditional preference scores using the updated model.
- Optimize thought generation: Treat the updated conditional preference score as the advantage function, and use a PPO-like clipped objective function (Equation 15) to optimize the thought generation policy, encouraging the model to produce thoughts that can earn high rewards.
Experimental Results
This paper conducted extensive experiments on three preference datasets (a subset of HH-RLHF, an internal instruction-following dataset, and a mathematical reasoning dataset) and across multiple model scales (Llama3 and Qwen2.5).
| Dataset | HH-RLHF (subset) | Instruction Following | Mathematical Reasoning |
|---|---|---|---|
| # Training Data | 20,000 | 14,407 | 16,252 |
| # Test Data | 1,000 | 784 | 841 |
Main Results
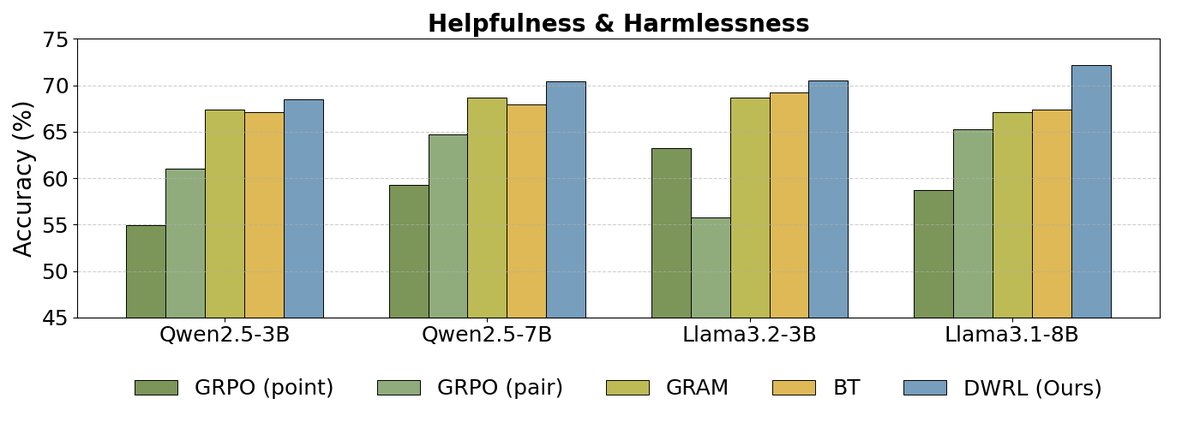
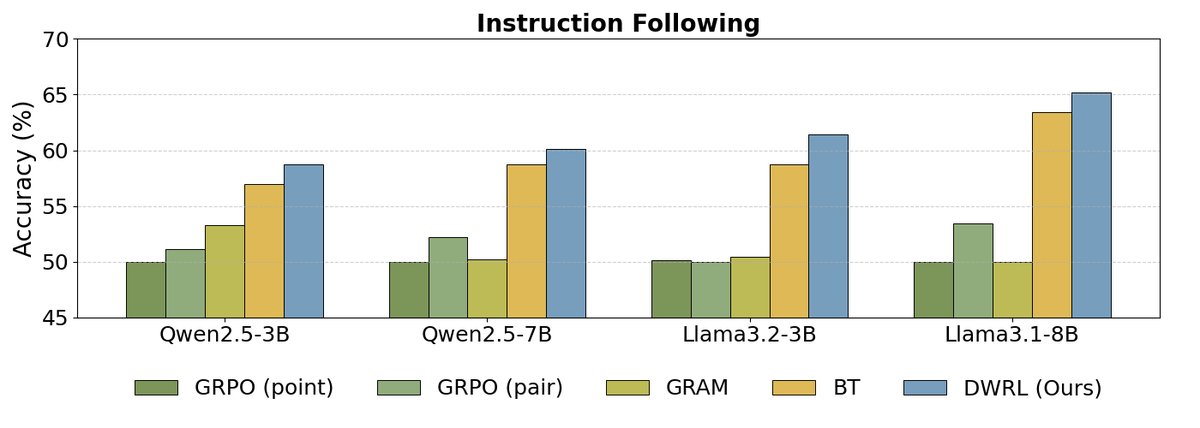
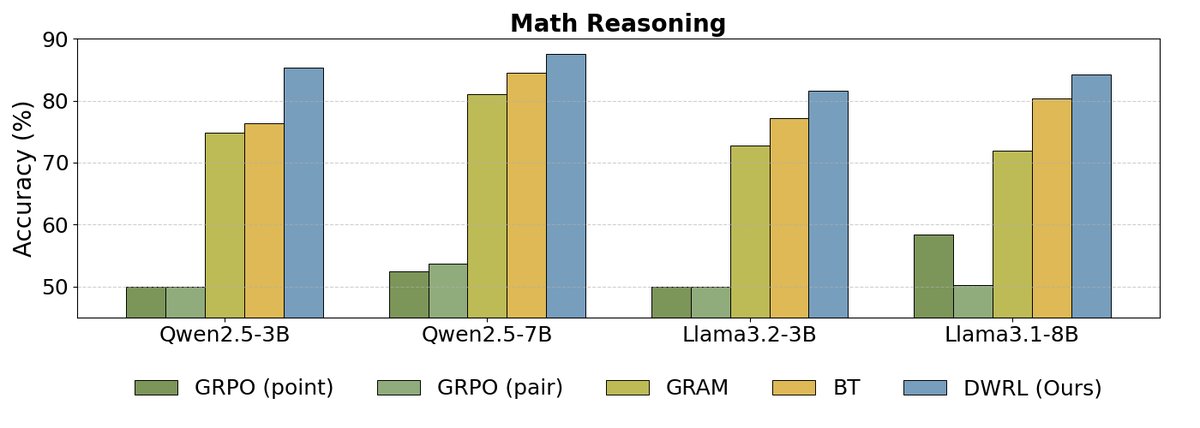 As shown above, the experimental results indicate:
As shown above, the experimental results indicate:
- DWRL achieves the best performance: Across all benchmarks and model scales, DWRL significantly outperforms all baseline methods, including the standard BT model, the pairwise comparison model (GRAM), and the GPM trained with a standard reinforcement learning algorithm (GRPO). On the mathematical reasoning task, the accuracy improvement reaches as high as 9.1%.
- Limitations of standard RL methods: The experiments found that GPMs that directly treat preference modeling as a generation task and apply standard RL algorithms (such as GRPO) perform even worse than the simple BT model. This validates the paper’s core argument: preserving the inductive bias of preference modeling is crucial, and naively applying a generative RL framework is ineffective.
- Shortcomings of pairwise models: The experiments also found that pairwise models (GRAM), which concatenate two candidate answers and ask the model to judge which is better, perform poorly on tasks requiring step-by-step reasoning (such as instruction following and math), indicating limited generalization ability.
To further verify this, the paper also compared against other published GPM models using SFT (supervised fine-tuning) (RM-R1). The results show that even after SFT, these models still perform far below DWRL, once again demonstrating the superiority of the DWRL method.
| Model (Qwen2.5-7B) | HH-RLHF | Instruction Following | Mathematical Reasoning |
|---|---|---|---|
| RM-R1 (official) | 62.7 | 52.2 | 55.0 |
| RM-R1 (after fine-tuning) | 62.7 | 52.2 | 55.9 |
| GRPO (pair) | 64.7 | 52.2 | 53.7 |
| DWRL | 69.5 | 54.9 | 64.1 |
Ablation Study
The ablation experiments further reveal the key factors behind DWRL’s success:
- DWRL improves thought quality: Compared with the approach of generating thoughts offline and then retraining the BT model, DWRL’s end-to-end training can generate more informative thoughts, thereby significantly improving the final preference judgment accuracy.
- The importance of misalignment weights: After removing the instance-level misalignment weights, model performance drops sharply across multiple datasets. This shows that the inductive bias of preference modeling represented by this weight is a key component of DWRL’s success.
| Model (Llama3.2-3B) | HH-RLHF | Instruction Following | Mathematical Reasoning |
|---|---|---|---|
| BT (using prefilling thoughts) | 69.1 | 59.6 | 78.1 |
| DWRL (without misalignment weights) | 59.1 | 58.5 | 62.1 |
| BT (without prefilling thoughts) | 69.2 | 58.7 | 77.2 |
| DWRL (full version) | 70.2 | 61.3 | 81.0 |
Summary
The DWRL framework proposed in this paper successfully combines CoT reasoning with the intrinsic structure of preference data, providing an effective path for CoT training on non-verifiable tasks. The experiments demonstrate that preserving the inductive bias of preference modeling is crucial for the success of GPMs, and DWRL elegantly achieves this through its dual-weighting mechanism, thereby attaining SOTA performance on multiple benchmarks.