DR. WELL: Dynamic Reasoning and Learning with Symbolic World Model for Embodied LLM-Based Multi-Agent Collaboration
-
ArXiv URL: http://arxiv.org/abs/2511.04646v1
-
Authors: Narjes Nourzad; Carlee Joe-Wong; Hanqing Yang
-
Publishing Institution: Carnegie Mellon University; University of Southern California
TL;DR
This paper proposes DR. WELL, a decentralized neuro-symbolic framework that enables LLM-based embodied intelligent agents to efficiently perform collaborative planning, learning, and self-optimization through a structured negotiation protocol and a dynamically evolving symbolic world model.
Key Definitions
The paper introduces or adopts the following core concepts:
-
DR. WELL (Dynamic Reasoning and Learning with Symbolic World Model): A decentralized neuro-symbolic planning framework. It enables LLM-based intelligent agents to collaborate on interdependent tasks through a dynamic world model. At its core are structured communication and experience-based symbolic planning.
- Two-phase negotiation protocol: A structured communication mechanism used to assign tasks among decentralized intelligent agents.
- Proposal stage: Idle intelligent agents independently propose a candidate task based on historical experience provided by the world model and state their reasons.
- Commitment stage: Under consensus and environmental constraints, the intelligent agents reach a final agreement on task allocation and make commitments.
- Symbolic World Model (WM): A shared, dynamic symbolic knowledge base that serves as the foundation for collaboration and reasoning among intelligent agents. It organizes knowledge in the form of a hierarchical graph, recording environmental states, intelligent agent actions, and task outcomes, and continuously evolves across episodes to accumulate experience. It plays a role in two key stages:
- Negotiation guidebook: During negotiation, it provides statistics such as historical task success rates and time costs to help intelligent agents make better decisions.
- Plan library: During planning, it provides successful abstract plan prototypes and concrete plan instances from the past to help intelligent agents generate and refine their own plans.
- Symbolic Planning and Execution: Instead of directly generating detailed low-level motion trajectories, intelligent agents generate sequences composed of high-level macro actions such as \(align\) and \(push\). The execution controller checks the preconditions of each action and translates it into low-level actions, while the environment verifies the final effect of the action.
Related Work
At present, achieving generalizable collaborative behavior in multi-agent reinforcement learning (MARL) remains a challenge. Although recent studies have introduced LLMs to improve flexibility, directly using LLM-generated policies in decentralized embodied environments is highly fragile. This is mainly because intelligent agents must coordinate under partial observability, restricted communication, and asynchronous execution, and LLMs are highly sensitive to prompts, making it difficult to generalize to different numbers of intelligent agents or environmental conditions.
Building coordination at the level of low-level trajectories is prone to failure, because small timing or movement deviations can quickly accumulate and lead to conflicts. Therefore, the bottleneck in this line of research is how to achieve stable and efficient multi-agent collaboration without relying on centralized control or fragile low-level alignment.
This paper aims to address this problem: how to raise the level of abstraction so that decentralized embodied LLM intelligent agents can achieve robust, interpretable collaborative planning under limited communication, and continuously improve through experience-based learning.
Method
This paper proposes the DR. WELL framework, a decentralized collaborative framework that combines neural methods (the reasoning ability of LLMs) with symbolic systems (structured representation and planning). Its core design simplifies coordination through symbolic abstraction.
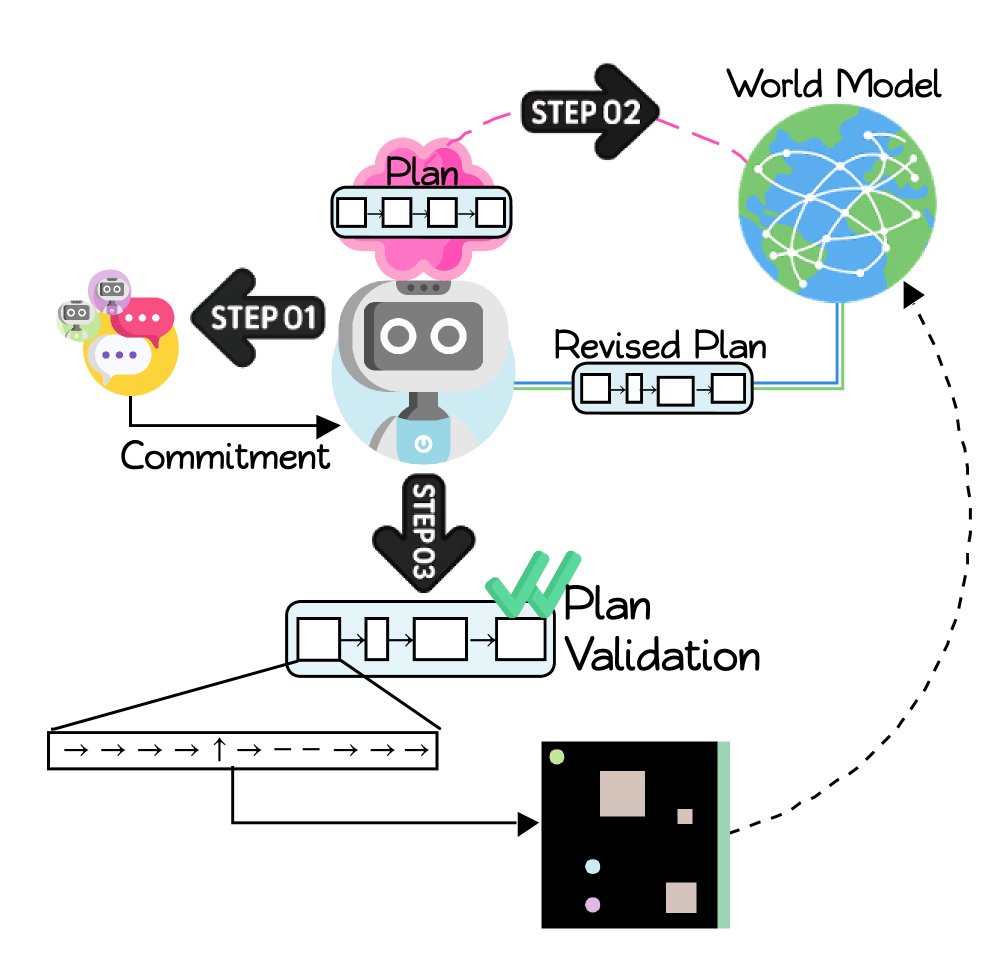
Negotiation Protocol
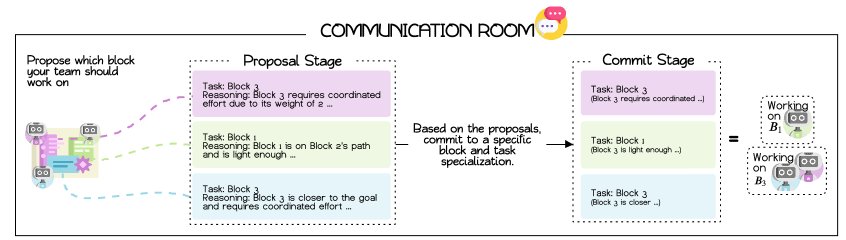
When one or more intelligent agents become idle, they enter a shared “communication room” and trigger a structured two-round negotiation protocol to assign tasks.
- Proposal stage: Each idle intelligent agent, in round-robin order, queries the world model (WM) for historical data such as task success rates and average duration, then proposes the task it considers most suitable (for example, selecting a specific box in a push-block task) and provides a brief rationale.
- Commitment stage: All intelligent agents share one another’s proposals and, based on consensus (such as voting) and environmental constraints (such as the minimum number of intelligent agents required for a task), finalize the task allocation for each intelligent agent.
This design limits communication to necessary synchronization points, avoiding continuous “free-form conversation,” improving communication efficiency, and ensuring that intelligent agents reach agreement on collaborative goals before acting.
Symbolic Planning and Execution
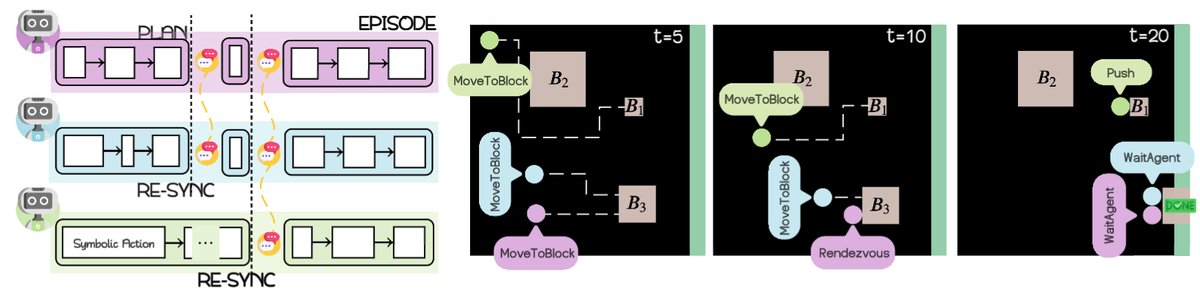
Once task commitments are determined, each intelligent agent independently enters a planning-and-execution loop.
- Plan generation and revision: Each intelligent agent uses its LLM to generate an initial symbolic plan draft based on the committed task. It then queries the shared world model (WM) and uses the successful plan prototypes and instances stored there to revise and refine the draft, making it more effective and better suited to the current context. The final plan is a sequence of symbolic macro actions from a predefined vocabulary, such as \(sync\), \(align\), and \(push\).
- Execution and verification: A symbolic controller executes the actions in the plan one by one.
- Precondition checking: The controller locally checks whether the preconditions of each action are satisfied in the current world state. For example, a \(push\) action that requires two intelligent agents to cooperate can only be executed when both intelligent agents have \(align\)ed to the designated positions.
- Postcondition verification: The actual effect of the action is verified by the environment. The controller translates the symbolic action into low-level movement commands and executes them, and the environment reports whether the action successfully achieved the intended effect.
- Failure handling: If the preconditions are not met (for example, waiting for a collaborator times out), the action fails and the plan either moves to the next step or aborts. If the plan finishes execution or fails, the intelligent agents return to the idle state and prepare for a new round of negotiation.
World Model (WM)
The world model is the innovative core of the framework; it serves both as a shared memory bank and as the engine for learning and optimization.
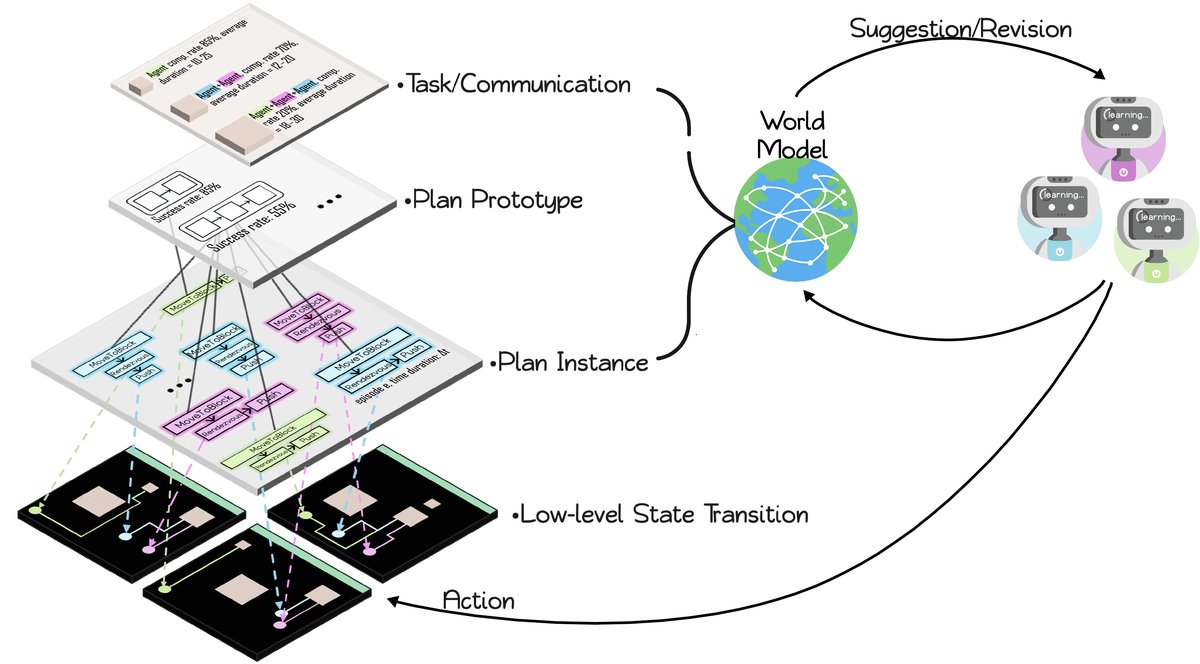
Innovations
-
Dynamically evolving hierarchical graph structure: WM is built as a dynamic symbolic graph of the form:
\[\mathcal{G=(V,E)},\quad\mathcal{V=V_{epi}}\cup V_{task}\cup V_{proto}\cup V_{inst},\quad E=E_{epi\rightarrow task}\cup E_{task\rightarrow proto}\cup E_{proto\rightarrow inst}\]
where the nodes are divided into four levels: episodes, tasks, plan prototypes (abstract action sequences), and plan instances (action sequences with concrete parameters). Each new episode adds new nodes and edges to the graph, and the graph structure becomes increasingly rich as experience accumulates.
$$
\mathcal{G}_{k+1}=\mathcal{G}_{k}\cup\Delta\mathcal{G}_{k}
$$
This structure links high-level abstractions (tasks) with low-level execution outcomes (the success or failure of plan instances), enabling the model to capture reusable collaboration patterns.
- Dual functions:
- Negotiation guidebook: During negotiation, WM provides intelligent agents with statistics on the historical performance of each task, such as the number of attempts, success rate, and average duration, giving data support for task proposals.
- Plan library: During planning, WM provides task-specific plan prototypes and instances ranked by success rate. Intelligent agents can draw on these successful experiences to generate and revise their own plans, achieving self-optimization.
In this way, WM integrates dispersed individual experiences into collective intelligence, guiding the intelligent agent group toward more efficient collaboration strategies.
Experimental Results
This paper evaluates the DR. WELL framework in a customized cooperative push-block environment (Cooperative Push Block, CUBE). In this environment, pushing boxes of different sizes requires different numbers of intelligent agents to cooperate.
Baseline Intelligent Agent Performance
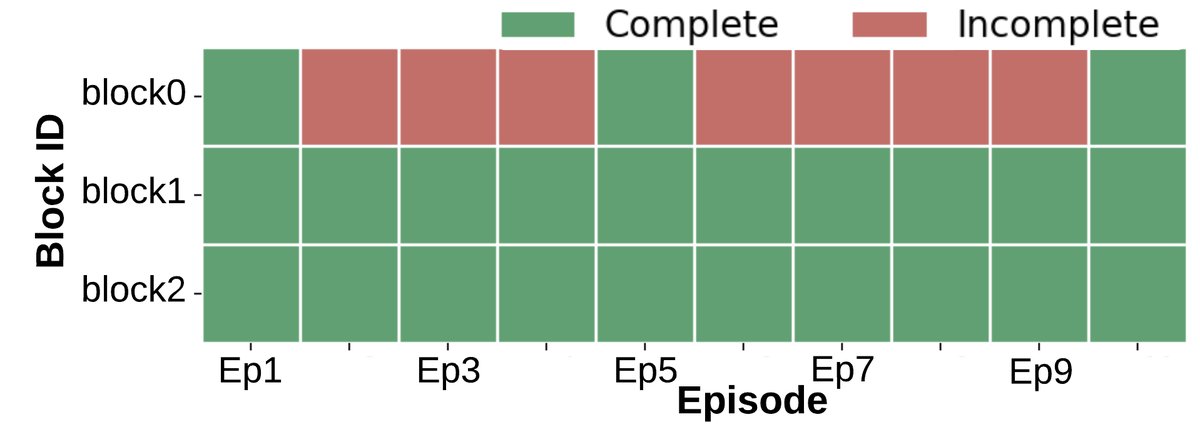
The baseline intelligent agents operate in a zero-shot manner, with no negotiation, shared memory, or communication mechanism, and make independent decisions based only on a fixed prompt (always handling the box closest to the goal).
- No sign of learning: Task completion results (Fig. a) show a binary pattern (completed or not completed) with no improvement as the number of episodes increases. Completion time (Fig. b, c) also remains essentially unchanged.
- Low efficiency: All intelligent agents tend to rush toward the same box, even when the task does not require multi-agent cooperation, resulting in wasted resources.
DR. WELL Framework Performance
Under the DR. WELL framework, the agents coordinate through a shared world model and a negotiation protocol.
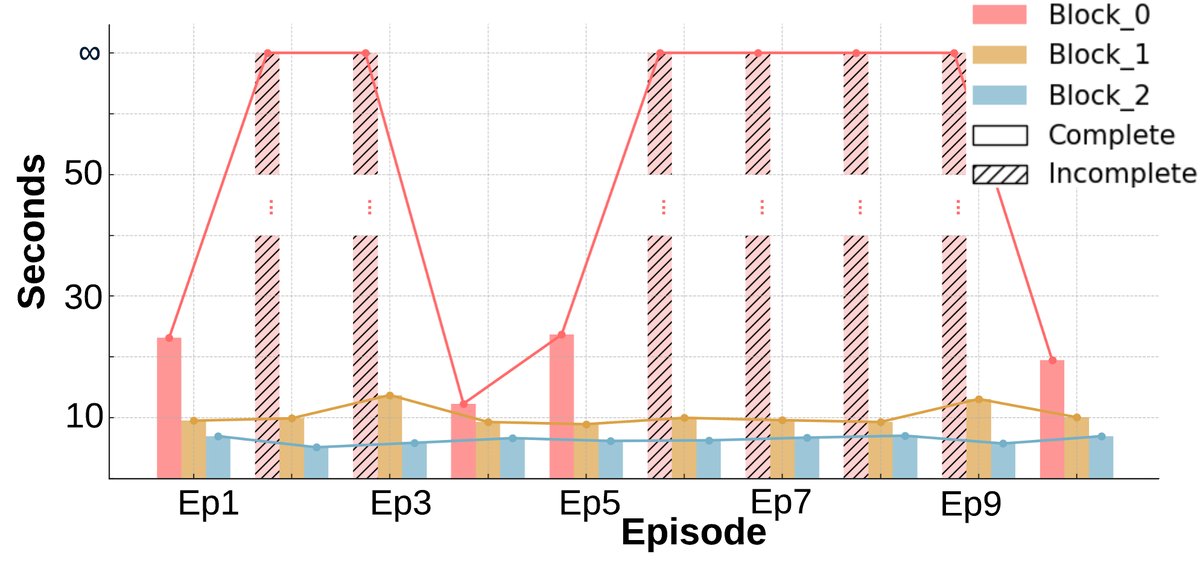
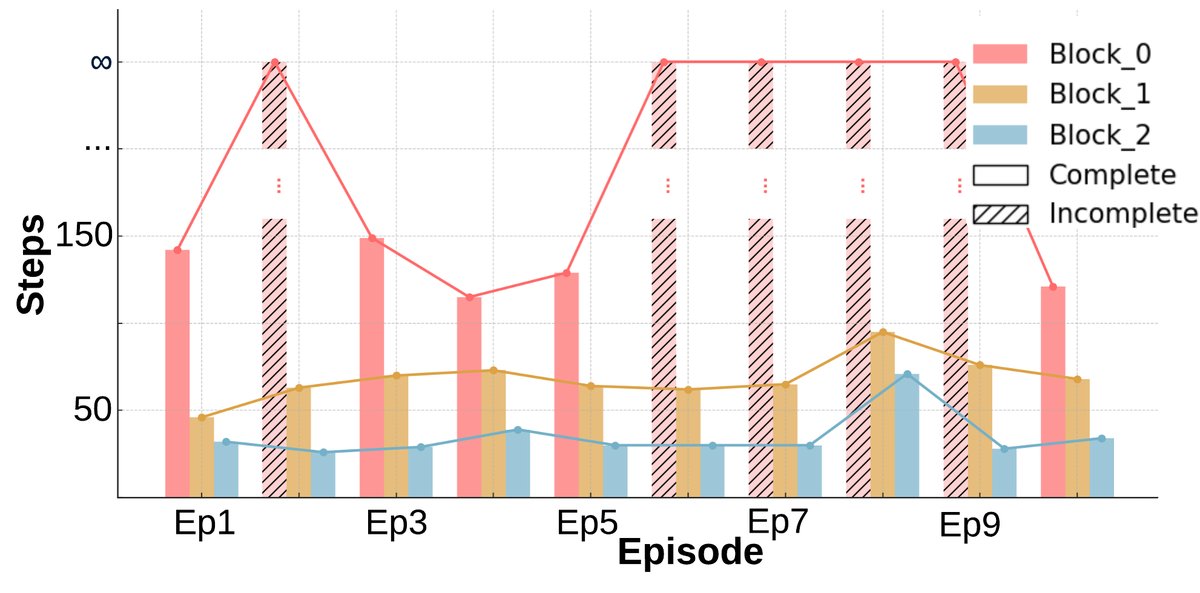
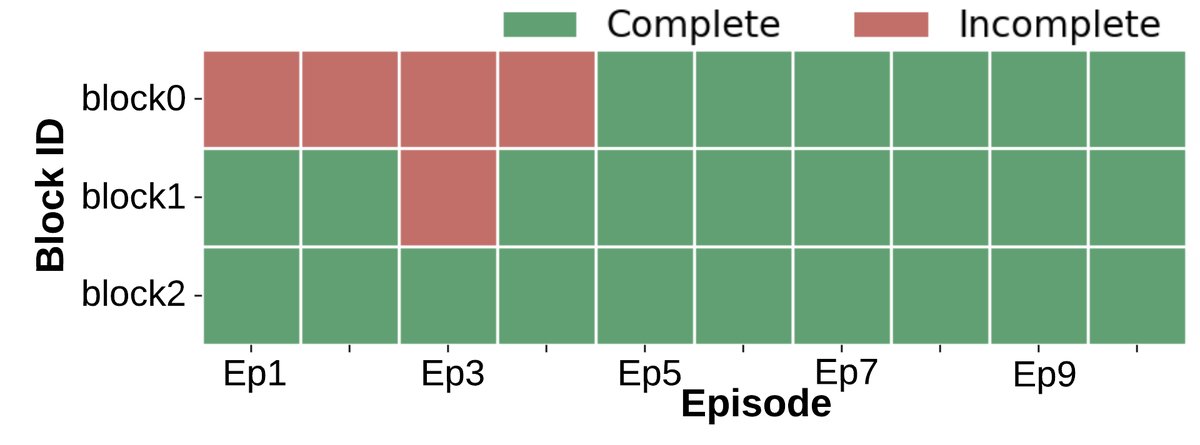
- Significant learning and adaptability: Unlike the baseline, after the early episodes, almost all blocks can be completed consistently (Figure a). The number of environment steps required to finish the task (Figure b) and the wall-clock time (Figure c) both show a clear downward trend, indicating that the agents learned more efficient strategies.
- Improved collaboration efficiency: The task commitment pattern (Figure d) shows that after several episodes, the agents are able to reach a stable division of labor, reducing unnecessary task overlap.
- Cost and benefit: Although negotiation and replanning introduce some additional wall-clock time overhead, the total number of environment interaction steps drops significantly. This shows that the agents trade a small amount of planning time for more efficient physical execution, resulting in higher overall collaboration efficiency.
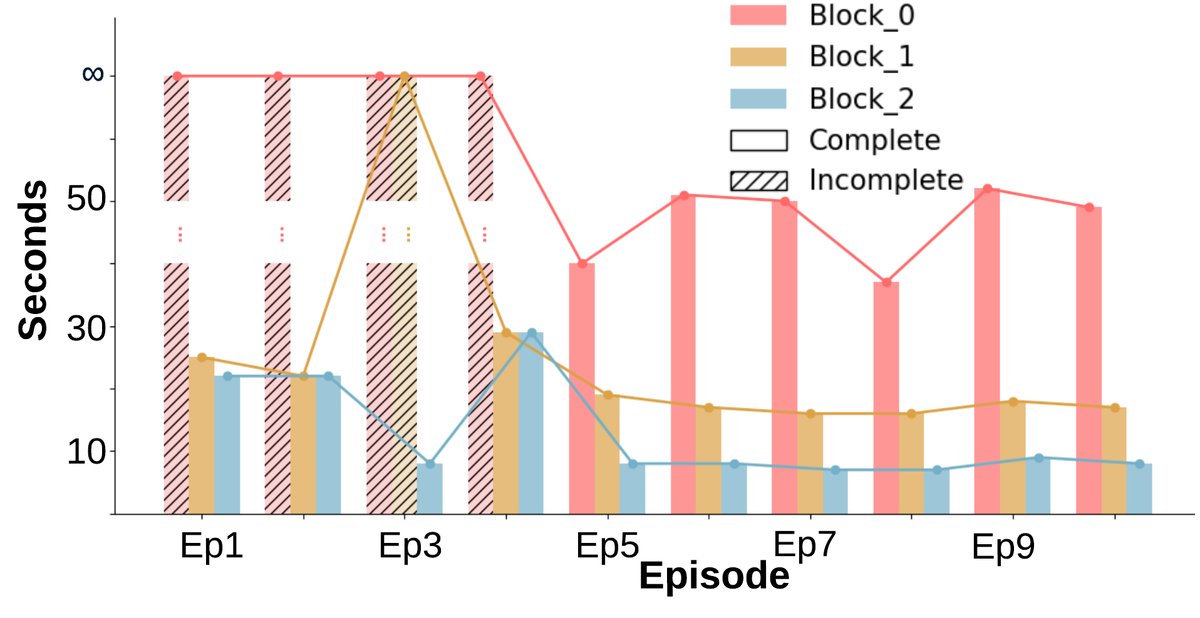
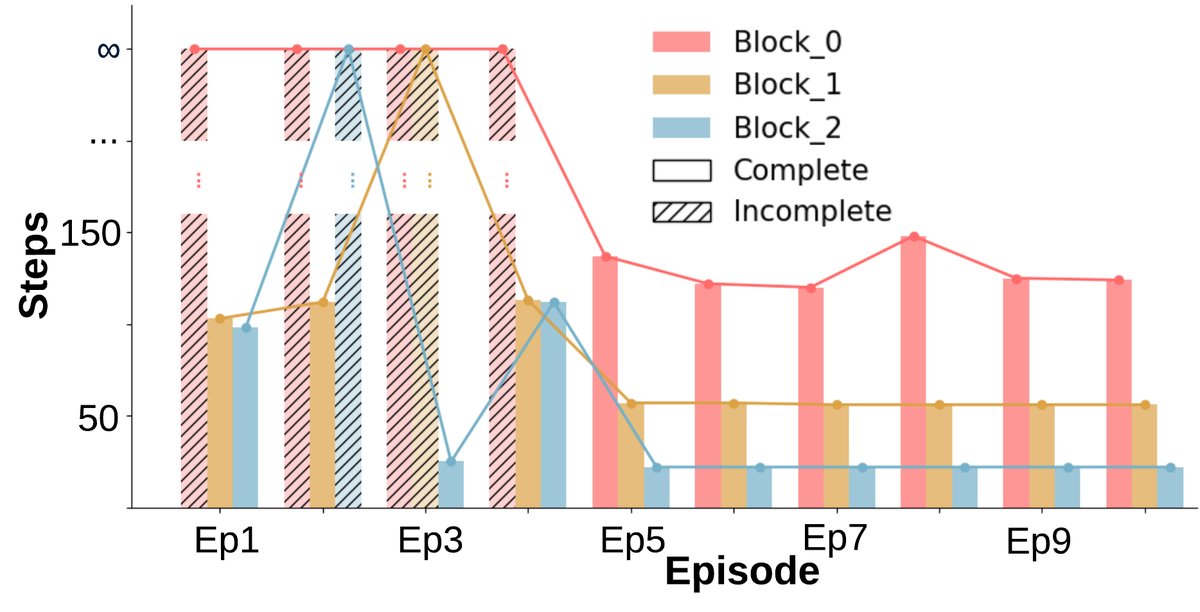
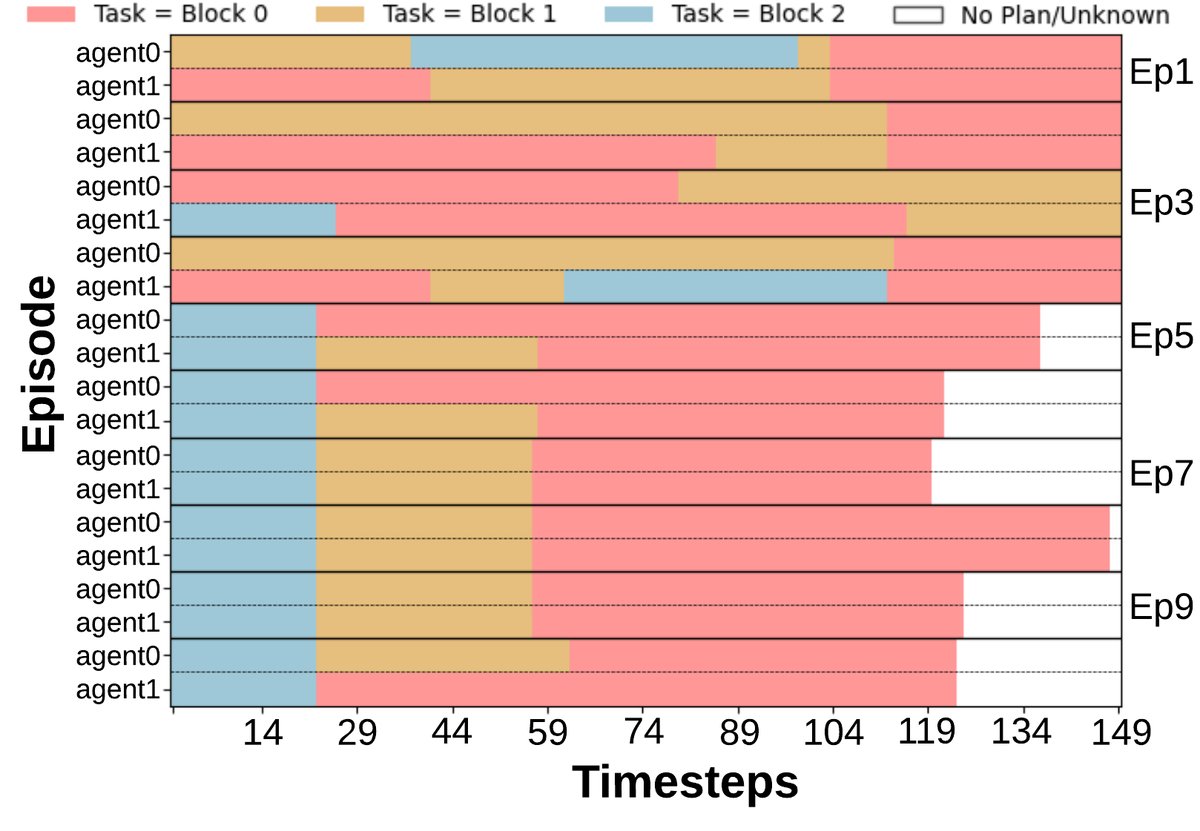
Evolution of the World Model
By visualizing the graph structure of the world model, we can see how it evolves as the number of episodes increases.
- From the sparse graph in Episode 1, to the emerging structure in Episode 5, and then to the dense graph in Episode 10, the WM clearly records and organizes tasks, reusable planning patterns, and concrete execution cases. This proves that the WM is not just a log recorder, but a dynamic memory system that can integrate experience and distill abstract knowledge.
 Episode 1 |  Episode 5 |  Episode 10 |
Summary
The experimental results strongly demonstrate that the proposed DR. WELL framework, by combining structured negotiation and a dynamic symbolic world model, enables a group of LLM agents to learn from experience and progressively optimize their collaboration strategies, thereby achieving higher completion rates and execution efficiency in multi-agent collaboration tasks.