DocReward: A Document Reward Model for Structuring and Stylizing
-
ArXiv URL: http://arxiv.org/abs/2510.11391v1
-
Author: Si-Qing Chen; Jiayu Ding; Lei Cui; Tao Ge; Tengchao Lv; Yilin Jia; Yupan Huang; Bowen Cao; Xun Wang; Junpeng Liu; and 17 others
-
Publishing Organization: Microsoft; The Chinese University of Hong Kong; UCAS; University of Michigan; XJTU
TL;DR
This paper proposes a document reward model called DocReward, which is trained on a large-scale dataset of 117K document pairs and is specifically designed to evaluate the structural and stylistic professionalism of documents. It significantly outperforms powerful baseline models such as GPT-5 on this task.
Key Definitions
The core concepts proposed or used in this paper include:
- DocReward: The core model proposed in this paper, a Document Reward Model designed specifically to evaluate the structural and stylistic professionalism of documents rather than the quality of the text content.
- DocStruct-117K: A multi-domain dataset built to train DocReward. It contains 117,000 document pairs spanning 32 domains and 267 document types. The two documents in each pair have exactly the same content, but differ clearly in the professionalism of their structure and style.
- Textual-quality-agnosticism: A key property of DocReward, meaning that the model ignores the quality of the text content itself during evaluation and focuses only on how well the document performs in terms of structure and style given the content. This is achieved by training on document pairs with identical content but different forms.
- Document structure and style professionalism: The specific definition of the evaluation target in this paper, including:
- Structure: Reasonable use of whitespace, appropriate margins, clear section breaks, good text alignment, sufficient paragraph spacing, correct indentation, inclusion of headers and footers, and logically coherent organization of content.
- Style: Appropriate font choices (type, size, color, readability), clear heading styles, effective use of emphasis (bold, italics), bullet points, numbering, and consistency in formatting.
Related Work
At present, automated professional document generation in agentic workflows is an important direction. However, existing research mainly focuses on improving the quality of text content, while overlooking the visual structure and style that are crucial for readability and professionalism.
The key bottleneck in this field is the lack of a suitable reward model to guide agents in generating documents that are more professional in structure and style. Although there are aesthetic evaluation models for graphic design, UI interfaces, or single images, they are not suitable for multi-page documents; traditional document AI models (such as LayoutLM) mainly focus on extracting information from documents rather than evaluating their layout quality.
Therefore, the core question this paper aims to address is: How can we quantitatively evaluate the structural and stylistic professionalism of documents, and create a reward model that can effectively guide document-generation agents?
Method
This paper proposes DocReward, a reward model focused on evaluating the structural and stylistic professionalism of documents. Its core lies in constructing a high-quality preference dataset \(DocStruct-117K\) and training the model on it for scoring.
Dataset Construction (DocStruct-117K)
To enable the model to learn professionalism evaluation that is independent of text content, the paper designs an elaborate dataset construction pipeline:
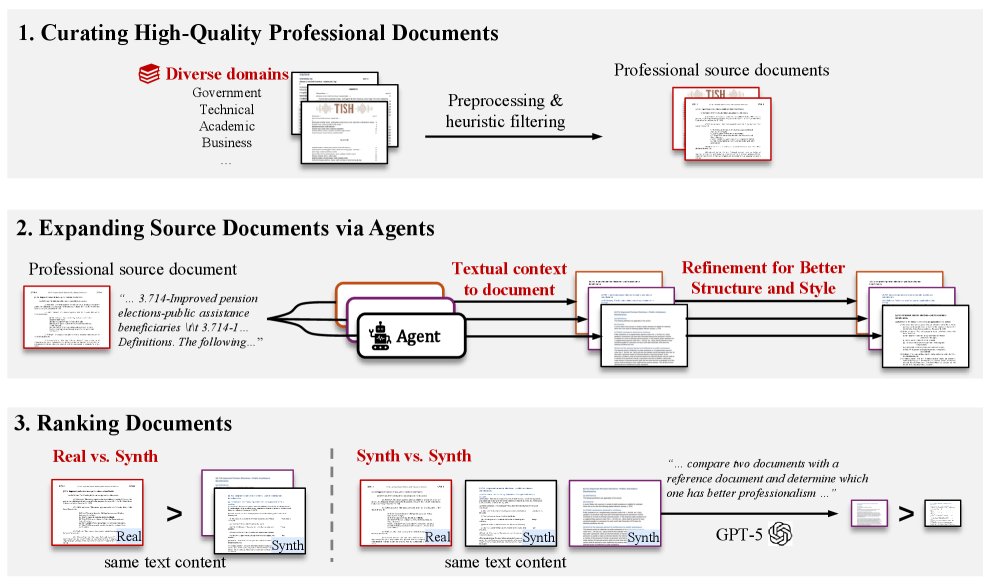
- Collect high-quality source documents: First, a large number of human-created, high-quality professional documents were collected from sources such as GovDocs1, NapierOne, and CommonCrawl (e.g., government reports, business proposals, academic papers). After filtering, examples with strong structure and style were retained.
-
Generate diverse corresponding documents: The plain-text content of the source documents was extracted, and then agents driven by multiple large language models (such as GPT-4o, GPT-5, etc.) were used to regenerate DOCX documents from scratch. This process simulates the real-world scenario of generating professional documents from plain text, producing many versions with different structures and styles but identical content. In addition, an “improvement agent” was designed to refine generated documents by referring to the original document.
-
Annotate preference pairs: Documents with the same content were paired and labeled with winner/loser relationships. The annotation rules are as follows:
- Human vs. generated: If one document is the original professional document created by a human and the other is generated by an agent, the original document is always labeled as the “winner.”
- Generated vs. generated: If both documents are generated by agents, GPT-5 is used as a proxy annotator. By providing GPT-5 with the original professional document as a reference, it judges which of the two generated documents is closer to the reference standard.
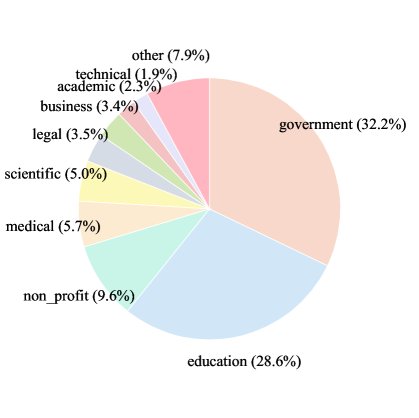
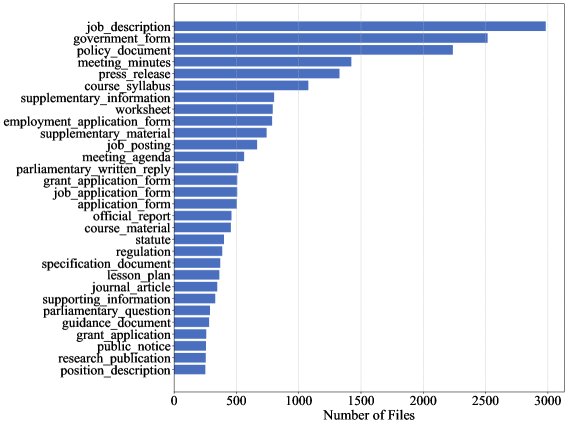
Through this process, the \(DocStruct-117K\) dataset was ultimately built, containing 117,108 document pairs.
| Domain | Document Type | Number of Documents | Average Pages | Total Document Pairs | Human vs. Generated | Generated vs. Generated |
|---|---|---|---|---|---|---|
| 32 | 267 | 69,137 | 3.2 | 117,108 | 36,664 | 80,444 |
Model Architecture and Optimization
-
Model architecture: This paper uses Qwen-2.5-VL as the base model because it natively supports multi-image input, making it suitable for processing multi-page documents. Each page of a document is rendered as an image and fed into the model. A regression head is added on top of the model to output a scalar score representing professionalism.
-
Optimization objective: The training process uses the Bradley-Terry (BT) loss function. For each preference pair $(D^w, D^l)$, where $D^w$ is the winner and $D^l$ is the loser, the model aims to maximize the score difference between the two. The loss function is as follows:
where $\mathcal{R}_{\theta}$ is the reward model and $\sigma$ is the sigmoid function. This loss penalizes the model when it assigns a higher score to the loser than to the winner.
Innovations
- Uniqueness of the task: For the first time, the focus of document evaluation is shifted from “text content” to “structure and style,” filling a gap in existing research.
- Data-driven approach: By constructing a large-scale preference dataset \(DocStruct-117K\) with consistent content and diverse forms, the model learns professional layout conventions in a data-driven way, achieving “textual-quality-agnosticism.”
- Pointwise scoring model: The final DocReward is a pointwise model, meaning it scores a single document. This avoids the common “position bias” in pairwise comparison models, where the model tends to prefer the option presented in the second position, resulting in more stable and reliable evaluation.
Experimental Conclusions
This paper comprehensively validates the effectiveness of DocReward through both internal and external evaluations.
Internal Evaluation: Accuracy Surpasses Strong Baselines
On a test set annotated by human experts, DocReward performs far better than all baseline models, including GPT-5.
| Model Type | Model | Real vs. Synth (Accuracy %) | Synth vs. Synth (Accuracy %) | Overall (Accuracy %) |
|---|---|---|---|---|
| Pairwise | ||||
| GPT-4o | 58.91 | 66.43 | 63.22 | |
| Claude Sonnet 4 | 57.86 | 69.02 | 64.26 | |
| GPT-5 | 64.78 | 72.32 | 69.10 | |
| Pointwise | ||||
| GPT-4o | 50.99 | 64.21 | 58.56 | |
| Claude Sonnet 4 | 48.02 | 66.79 | 58.77 | |
| GPT-5 | 64.85 | 73.43 | 69.77 | |
| DocReward-3B (this paper) | 72.77 | 97.42 | 86.89 | |
| DocReward-7B (this paper) | 78.22 | 97.42 | 89.22 |
- Outstanding performance: DocReward-7B achieves an overall accuracy of 89.22%, nearly 20 percentage points higher than the strongest closed-source baseline, GPT-5 (69.77%).
- Scenario advantage: When distinguishing “human professional documents” from “AI-generated documents,” DocReward is nearly perfect (97.42% accuracy), indicating a deep understanding of professional standards.
- Bias avoidance: Experiments found that pairwise baseline models such as GPT-4o exhibit obvious position bias, whereas pointwise DocReward does not.
| Reward Model | Times Preferring Position 1 | Times Preferring Position 2 |
|---|---|---|
| GPT-4o | 202 | 271 |
| Claude Sonnet 4 | 189 | 284 |
| GPT-5 | 240 | 233 |
External Evaluation: Effectively Guiding Document Generation
To verify the practical value of DocReward, this paper conducted an external evaluation: a document generation intelligent agent was asked to generate multiple candidate documents, and Random, GPT-5, and DocReward were then used as reward models to select the best version. The results were ultimately judged by human evaluators.
| Reward Model | Win Rate (%) | Loss Rate (%) | Tie Rate (%) |
|---|---|---|---|
| Random | 24.6 | 66.2 | 9.2 |
| GPT-5 | 37.7 | 40.0 | 22.3 |
| DocReward (this paper) | 60.8 | 16.9 | 22.3 |
The results show that documents selected using DocReward achieved a 60.8% win rate, far higher than GPT-5 (37.7%). This proves that DocReward’s reward signal is highly aligned with human preferences for structure and style, and can effectively guide the generation intelligent agent to produce documents that are more favored by humans.
Interpretability Analysis
Through case studies and attention map visualization, it can be seen that DocReward is indeed focusing on the right signals.
-
Case studies: For different layouts of the same content, the scores given by DocReward are consistent with human intuition. Documents with cluttered layouts and poor alignment receive low scores, while documents with clear structure and prominent key points receive high scores.



-
Attention maps: The visualization results show that, when making decisions, the model’s attention is more concentrated on structural elements such as titles, numbering, headers and footers, bullet points, table lines, and margins, rather than on the specific text content.



Summary
The experimental results strongly demonstrate that DocReward outperforms existing general-purpose large models in evaluating the structural and stylistic professionalism of documents, and can serve as an effective reward model to substantially improve the final quality of automated document generation.