DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
-
ArXiv URL: http://arxiv.org/abs/2402.03300v3
-
Author: Mingchuan Zhang; R. Xu; Zhihong Shao; Jun-Mei Song; Qihao Zhu; Y. K. Li; Peiyi Wang; Yu Wu; Daya Guo
-
Publisher: DeepSeek-AI; Peking University; Tsinghua University
TL;DR
This article introduces DeepSeekMath, a 7B language model that pushes the mathematical reasoning ability of open-source models to near-GPT-4 levels by continuing pretraining on a carefully constructed 120B mathematical corpus and adopting a new, efficient reinforcement learning algorithm called GRPO.
Key Definitions
- DeepSeekMath Corpus: A large-scale, high-quality mathematical pretraining corpus containing 120B token. It is extracted from public Common Crawl web data through a carefully designed iterative data filtering process. The corpus is multilingual and has undergone strict decontamination, forming the foundation of the model’s strong mathematical capabilities.
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm proposed in this paper, a variant of Proximal Policy Optimization (PPO). Its core innovation is to remove the critic model from PPO and instead evaluate multiple answers generated for the same problem, using the average score of the group as the baseline to estimate the advantage function. This design significantly reduces memory consumption and computational overhead during training, enabling more efficient reinforcement learning.
Related Work
At present, top-tier language models such as GPT-4 and Gemini-Ultra perform exceptionally well in mathematical reasoning, but they are closed-source, and neither their technical details nor model weights are publicly available. Meanwhile, existing open-source models still lag significantly behind these leading models in mathematical ability, which has become a key bottleneck in the field.
This paper aims to address this specific problem: narrowing the gap between the open-source community and state-of-the-art closed-source models in mathematical reasoning ability. By building a more powerful, publicly available math-specialized foundation model, it seeks to advance research and applications in the area.
Method
This paper builds and optimizes the DeepSeekMath model through a three-stage pipeline: large-scale mathematical pretraining, supervised fine-tuning (SFT), and reinforcement learning (RL) based on GRPO.
Stage 1: Large-Scale Mathematical Pretraining
DeepSeekMath Corpus Construction
To obtain high-quality mathematical pretraining data, the paper designs an iterative process for mining math-related web pages from Common Crawl (CC).
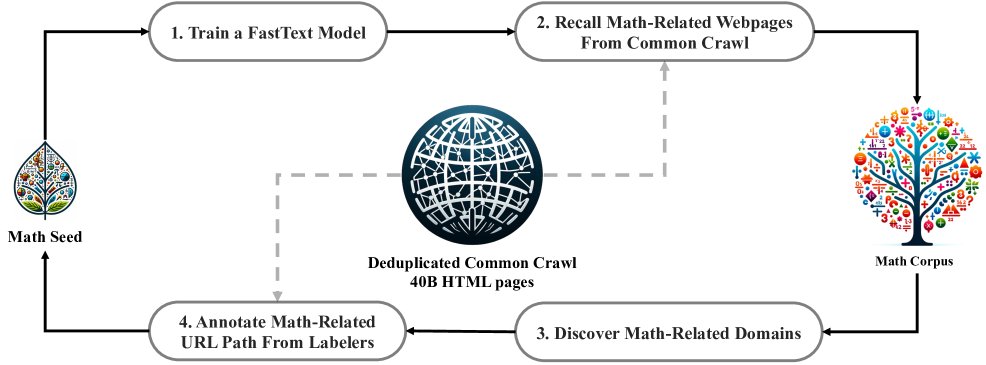
- Initial stage: Use a high-quality mathematical text collection, OpenWebMath, as seed corpus to train a fastText classifier for initially retrieving math-related web pages from massive CC data.
- Iterative refinement: To improve the classifier’s diversity and accuracy, the paper analyzes the domains of the initially retrieved pages and identifies domains with a high proportion of mathematical content, such as \(mathoverflow.net\). Then, by manually labeling specific URL patterns under these domains, more math pages that were not retrieved are added to the seed corpus.
- Loop and termination: Retrain the classifier with the expanded seed corpus and perform the next round of data mining. This process is repeated four times until the newly retrieved data begins to saturate (in the fourth round, about 98% of the data had already been collected in the third round). Ultimately, the DeepSeekMath corpus containing 120B token is built.
- Data decontamination: To ensure fair evaluation, n-gram fragments in the corpus that match questions or answers from known mathematical benchmarks such as GSM8K and MATH are strictly filtered out.
DeepSeekMath-Base Model Training
The training does not start from a general-purpose language model, but from a code pretraining model \(DeepSeek-Coder-Base-v1.5 7B\). The paper finds that starting from a code model yields better mathematical ability than starting from a general model.
The base model \(DeepSeekMath-Base 7B\) is continuously trained for 500B token on a mixed dataset with the following composition:
- 56% from the DeepSeekMath corpus
- 20% from GitHub code
- 10% from arXiv papers
- 10% from general Chinese and English natural language data
- 4% from AlgebraicStack (mathematical code)
This mixed training not only improves mathematical ability, but also preserves strong coding ability and enhances the model’s general reasoning ability.
Stage 2: Supervised Fine-Tuning (SFT)
After pretraining yields the powerful \(DeepSeekMath-Base\) model, the paper constructs a math instruction fine-tuning dataset with 776K samples to perform SFT, producing the \(DeepSeekMath-Instruct 7B\) model.
The dataset covers bilingual K-12 math problems in English and Chinese, and its solution formats are diverse, including:
- Chain-of-Thought (CoT): detailed textual reasoning steps.
- Program-of-Thought (PoT): solving problems by writing code.
- Tool-integrated reasoning: combining natural language and code tools for solving.
Stage 3: Reinforcement Learning (RL)
To further unlock the model’s potential, the paper proposes the innovative GRPO algorithm and uses it to train the final \(DeepSeekMath-RL 7B\) model.
Group Relative Policy Optimization (GRPO)
The PPO algorithm requires a critic model comparable in size to the policy model to estimate the value function, which brings substantial resource overhead. GRPO addresses this problem in the following way:
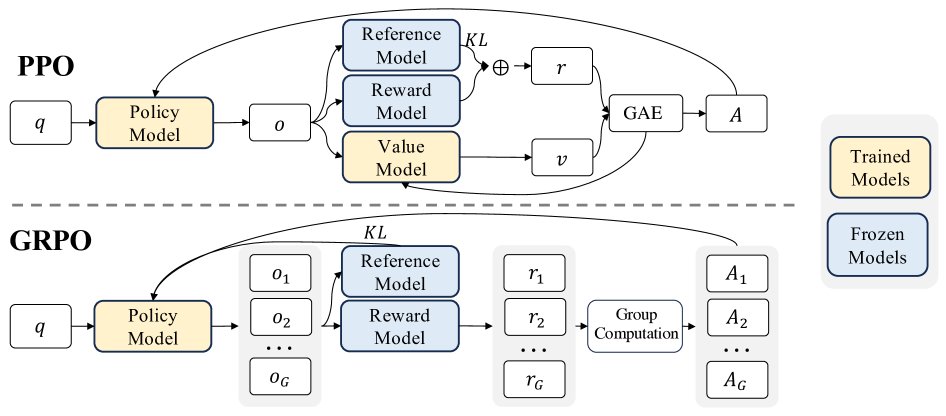
- Core mechanism: For each problem, GRPO no longer relies on a critic model; instead, it lets the current policy model generate a group of answers (for example, 64). Then a reward model scores these answers.
- Advantage estimation: GRPO uses the average reward of the group as the baseline. The advantage of each answer is the difference between its own reward and the group’s average reward. This relative advantage \($\hat{A}\_{i,t}\)$ is used to guide policy optimization.
- Objective function: GRPO’s optimization objective is to maximize the following function, which includes PPO’s clipping mechanism to stabilize training and directly adds the KL divergence to the reference model as a regularization term.
This method aligns the computation of the advantage function with the intrinsic structure of comparison data, and becomes extremely efficient because no critic model needs to be trained.
DeepSeekMath-RL Model Training
The \(DeepSeekMath-RL\) model is obtained by performing GRPO training on top of \(DeepSeekMath-Instruct 7B\), using only CoT-format questions related to GSM8K and MATH from the SFT data. This restricted training setup helps test the generalization ability of the RL stage.
Experimental Conclusions
The paper validates the effectiveness of its method at each stage through comprehensive evaluation on multiple standard mathematical benchmarks.
Effectiveness of the Pretraining Stage
- Corpus quality: After pretraining only, \(DeepSeekMath-Base 7B\) outperforms all open-source base models across multiple math benchmarks, including the larger \(Llemma 34B\).
- Surpassing large closed-source models: Notably, the 7B \(DeepSeekMath-Base\) achieves 36.2% accuracy on the competition-level MATH benchmark, even surpassing the closed-source \(Minerva 540B\), which is 77 times larger (33.6%), fully demonstrating the high quality of the DeepSeekMath corpus and the success of the pretraining strategy.
| Model | Size | GSM8K | MATH | MMLU STEM | CMATH |
|---|---|---|---|---|---|
| Closed-source base models | |||||
| Minerva | 540B | 58.8% | 33.6% | 63.9% | - |
| Open-source base models | |||||
| Mistral | 7B | 40.3% | 14.3% | 51.1% | 44.9% |
| Llemma | 34B | 54.0% | 25.3% | 52.9% | 56.1% |
| DeepSeekMath-Base | 7B | 64.2% | 36.2% | 56.5% | 71.7% |
Table 1: Performance comparison between DeepSeekMath-Base 7B and strong base models
- Gains from code training: Experiments show that performing code training before math training can significantly improve the model’s mathematical reasoning ability in both tool-using and tool-free settings.
- Tool use and formal mathematical ability: \(DeepSeekMath-Base 7B\) also delivers leading performance in solving math problems with Python (GSM8K+Python 66.9%, MATH+Python 31.4%) and in formal proof tasks (miniF2F-test 24.6%).
| Model | Size | GSM8K+Python | MATH+Python | miniF2F-test |
|---|---|---|---|---|
| CodeLlama | 34B | 52.7% | 23.5% | 18.0% |
| Llemma | 34B | 64.6% | 26.3% | 21.3% |
| DeepSeekMath-Base | 7B | 66.9% | 31.4% | 24.6% |
Table 2: Comparison of tool use and formal proof capabilities
Effectiveness of the SFT and RL stages
\(DeepSeekMath-RL 7B\) (final model) achieved the best performance among all open-source models and came close to, or even surpassed, some powerful closed-source models.
- Tool-free reasoning: In chain-of-thought reasoning without external tools, \(DeepSeekMath-RL 7B\) achieved an accuracy of 51.7% on MATH, making it the first open-source model to break the 50% barrier on this highly challenging benchmark. This result surpasses all open-source models from 7B to 70B, as well as closed-source models such as Gemini Pro and GPT-3.5.
- Tool-integrated reasoning: When using tools, \(DeepSeekMath-RL 7B\) reached 58.8% accuracy on MATH, again leading all existing open-source models.
- GRPO’s generalization ability: Although the RL training data was limited to CoT formats from GSM8K and MATH, the final model showed significant improvements over the SFT model on all test benchmarks, including the unseen Chinese math benchmark CMATH and tool-use scenarios. This demonstrates that the capability gains brought by the GRPO algorithm generalize strongly.
| Model | Size | GSM8K (CoT) | MATH (CoT) | MGSM-zh (CoT) | CMATH (CoT) |
|---|---|---|---|---|---|
| Closed-source models | |||||
| Gemini Ultra | - | 94.4% | 53.2% | - | - |
| GPT-4 | - | 92.0% | 52.9% | - | 86.0% |
| GLM-4 | - | 87.6% | 47.9% | - | - |
| Open-source models | |||||
| InternLM2-Math | 20B | 82.6% | 37.7% | - | - |
| Qwen | 72B | 78.9% | 35.2% | - | - |
| MetaMath | 70B | 82.3% | 26.6% | 66.4% | 70.9% |
| Models in this paper | |||||
| DeepSeekMath-Instruct (SFT) | 7B | 82.9% | 46.8% | 73.2% | 84.6% |
| DeepSeekMath-RL (RL) | 7B | 88.2% | 51.7% | 79.6% | 88.8% |
Table 3: Comparison of chain-of-thought reasoning performance between the final model and top-tier models
Final conclusion: Through high-quality data engineering, a clever pretraining strategy, and the efficient reinforcement learning algorithm GRPO, this paper successfully elevated an open-source 7B-parameter model to industry-leading levels in mathematical reasoning, providing the open-source community with a powerful and reproducible mathematical foundation model.