DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2501.12948v1
-
Author: K. Yu; Bei Feng; Yuting Yan; Yanping Huang; Shiyu Wang; Jingchang Chen; Xiaodong Liu; Yu-Wei Luo; Jingyang Yuan; Zhean Xu; and 196 others
-
Publisher: DeepSeek
TL;DR
This paper successfully sparked and significantly enhanced the reasoning abilities of large language models through large-scale reinforcement learning, whether applied purely to the base model or combined with a small amount of cold-start data. It introduced the DeepSeek-R1 series of models and verified that this advanced reasoning ability can be effectively transferred to smaller models through distillation.
Key Definitions
- DeepSeek-R1-Zero: One of the first-generation reasoning models proposed in this paper. Its core feature is the direct application of large-scale reinforcement learning (Reinforcement Learning, RL) to the base model, without using Supervised Fine-Tuning (SFT) as a preparatory step. This model demonstrates that strong reasoning ability can emerge spontaneously through RL alone.
- DeepSeek-R1: An enhanced version built on top of DeepSeek-R1-Zero. It uses a multi-stage training process, including initial SFT with a small amount of high-quality “cold-start data,” followed by multiple rounds of iterative RL and SFT, aiming to address the readability issues of R1-Zero and further improve performance and general capabilities.
- GRPO (Group Relative Policy Optimization): The core reinforcement learning algorithm used in this paper. It is a critic-free RL method that samples a group of outputs under the same prompt and estimates the advantage based on the rewards of that group, thereby updating the policy model. Compared with traditional methods, this approach reduces training cost.
- Cold-start data: Refers to a small amount (thousands of examples) of high-quality, long Chain-of-Thought (CoT) supervised data used in the initial fine-tuning stage of DeepSeek-R1. These data provide the model with a “seed” for reasoning patterns, helping accelerate RL convergence and ensuring the generated content is readable.
Related Work
At present, the post-training stage has become a key part of improving the capabilities of large language models (LLMs), especially in reasoning. State-of-the-art (SOTA) work in the field, such as OpenAI’s o1 series, has made significant progress on tasks like mathematics, coding, and scientific reasoning by increasing the length of the Chain-of-Thought at inference time. However, how to effectively achieve test-time scaling remains an open question for the research community as a whole.
Existing directions include process-based reward models, reinforcement learning, and search algorithms such as Monte Carlo Tree Search (MCTS). Although these methods have achieved some results, none has yet reached a level comparable to OpenAI’s o1 series in general reasoning performance.
The core question this paper aims to address is: can the reasoning potential of LLMs be unleashed using only pure reinforcement learning, without relying on any supervised data, and can it reach or surpass the current state of the art? At the same time, the paper also explores how a more refined process can solve issues such as poor readability and mixed-language output that may arise from pure RL methods.
Method
The core method of this paper is to use large-scale reinforcement learning to improve the reasoning ability of LLMs. The authors propose two concrete implementation paths: DeepSeek-R1-Zero, a pure RL exploration; and DeepSeek-R1, a more mature and user-friendly multi-stage training process.
DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
DeepSeek-R1-Zero is designed to explore the potential of LLMs to self-evolve reasoning ability through a pure RL process without any supervised data.
Innovations
The core innovation of this method is to apply RL directly to the base model (DeepSeek-V3-Base), bypassing the traditional SFT preparatory step. It shows that reasoning ability can be encouraged as an “emergent” behavior through reward signals, rather than having to be learned by imitating human-labeled CoT data.
Algorithm and Rewards
- RL algorithm: The GRPO (Group Relative Policy Optimization) algorithm is used. This algorithm does not require training a critic model of the same size as the policy model; instead, it estimates the baseline from the scores of a group of samples, thereby reducing training cost. Its optimization objective is as follows:
The advantage $A_i$ is computed from the group rewards:
\[A_{i}=\frac{r_{i}-{\mathrm{mean}(\{r_{1},r_{2},\cdots,r_{G}\})}}{{\mathrm{std}(\{r_{1},r_{2},\cdots,r_{G}\})}}.\]- Reward model: A rule-based reward system is used, mainly consisting of two parts:
- Accuracy reward: Provides reward by checking whether the final answer is correct. For example, for math problems, it verifies whether the answer matches the ground truth; for programming problems, it runs test cases through the compiler.
- Format reward: Forces the model to wrap its reasoning process inside \(<think>\) and \(</think>\) tags. The paper explicitly states that no neural reward model was used in order to avoid reward hacking issues during large-scale RL and to simplify the training process.
Emergence and Limitations
During training, DeepSeek-R1-Zero spontaneously learned to solve complex problems by increasing thinking time (generating longer CoT), and exhibited advanced behaviors such as self-reflection and exploring different solution paths, even showing self-correction similar to an “aha moment.”
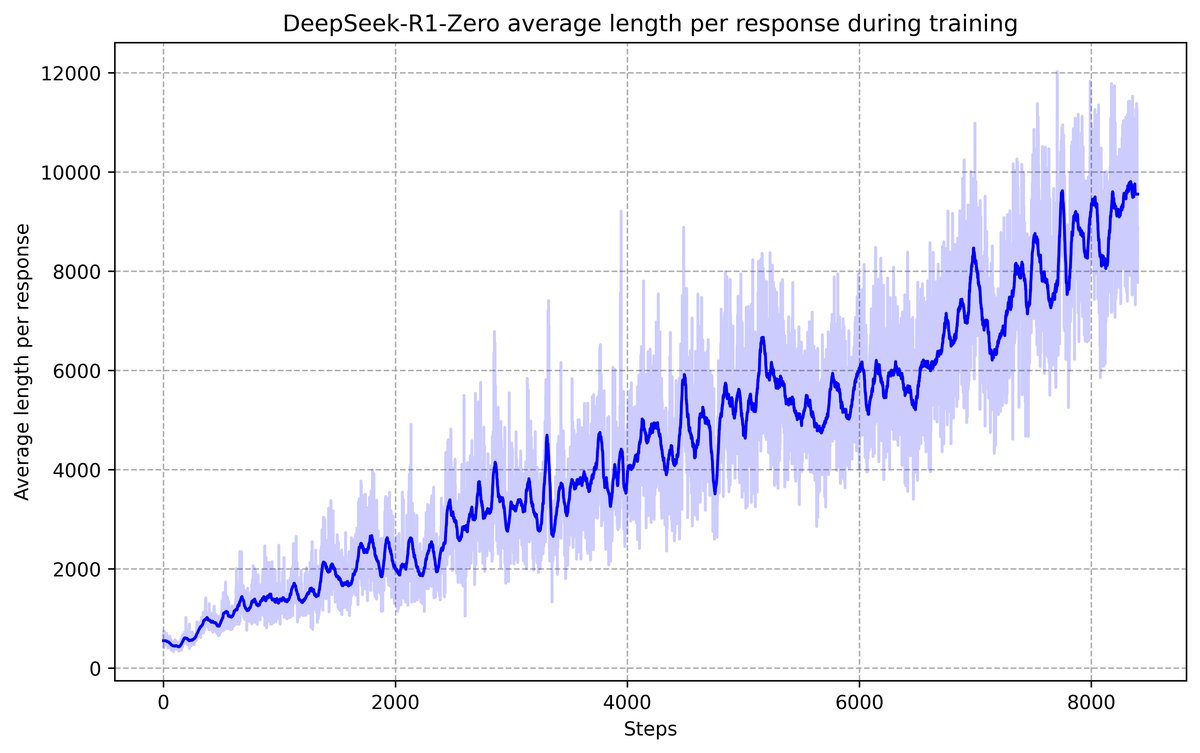
However, a model trained purely with RL has poor readability and mixed Chinese-English output, making it unsuitable for direct user-facing deployment.
| Example of the “aha moment” in an intermediate version of DeepSeek-R1-Zero |
|---|
| Problem: If $a>1$, then the sum of the real solutions of $\sqrt{a-\sqrt{a+x}}=x$ is |
| Response: |
| To solve the equation $\sqrt{a-\sqrt{a+x}}=x$, let’s square both sides first… |
| $\left(\sqrt{a-\sqrt{a+x}}\right)^{2}=x^{2}\implies a-\sqrt{a+x}=x^{2}.$ |
| Rearranging to isolate the inner square root term: |
| $(a-x^{2})^{2}=a+x\implies a^{2}-2ax^{2}+(x^{2})^{2}=a+x\implies x^{4}-2ax^{2}-x+(a^{2}-a)=0$ |
| … |
| Wait, wait. Wait. There’s an aha moment I can mark here. |
| Let’s step by step reassess to determine whether the correct sum could be… |
| We start from this equation: |
| $\sqrt{a-\sqrt{a+x}}=x$ |
| First, let’s square both sides: |
| $a-\sqrt{a+x}=x^{2}\implies\sqrt{a+x}=a-x^{2}$ |
| Next, I can square both sides again to handle this equation: … |
| … |
DeepSeek-R1: Reinforcement Learning with Cold Start
To address the shortcomings of DeepSeek-R1-Zero and further improve performance, the paper designs a refined four-stage training process to build DeepSeek-R1.
Process and Innovations
-
Stage 1: Cold Start Before RL begins, the base model is first fine-tuned with several thousand high-quality, human-friendly long CoT examples. These data are carefully designed to ensure the readability of the output format and provide a favorable starting point for the model’s subsequent RL exploration.
-
Stage 2: Reasoning-oriented RL On top of the cold-start model, the same GRPO algorithm as in R1-Zero is applied for RL training. This stage focuses on improving reasoning abilities in coding, mathematics, science, and other domains. To address language-mixing issues, an additional language consistency reward is introduced to encourage the model to use the target language in the CoT.
-
Stage 3: Rejection Sampling and SFT (Rejection Sampling and SFT) After RL converges, the model from this stage is used to collect about 600,000 high-quality reasoning data points through rejection sampling (keeping only generation trajectories with correct answers). At the same time, about 200,000 non-reasoning data points from DeepSeek-V3 (such as writing and factual Q&A) are incorporated to enhance the model’s general capabilities. Finally, this mixed dataset of about 800,000 samples is used to perform another round of SFT on the original base model (DeepSeek-V3-Base).
-
Stage 4: RL for all Scenarios (RL for all Scenarios) To further align with human preferences, a second round of RL is applied to the model fine-tuned in the previous stage. This stage combines rule-based rewards (for reasoning tasks) and a neural reward model (for evaluating the helpfulness and harmlessness of general tasks), aiming to optimize the model’s reasoning, helpfulness, and safety at the same time.
Distillation: Giving Small Models Reasoning Ability
To enable more efficient small models to also possess strong reasoning ability, this paper adopts a direct distillation method.
- Method: Using the 800,000 high-quality SFT samples collected during the DeepSeek-R1 training pipeline (Stage 3), multiple open-source models in the Qwen and Llama series are fine-tuned.
- Purpose: To verify that the reasoning patterns learned by large models through a complex process can be effectively “taught” to small models, providing an efficient and economical way to transfer capabilities.
Experimental Conclusions
The experimental results strongly confirm the effectiveness of the proposed method.
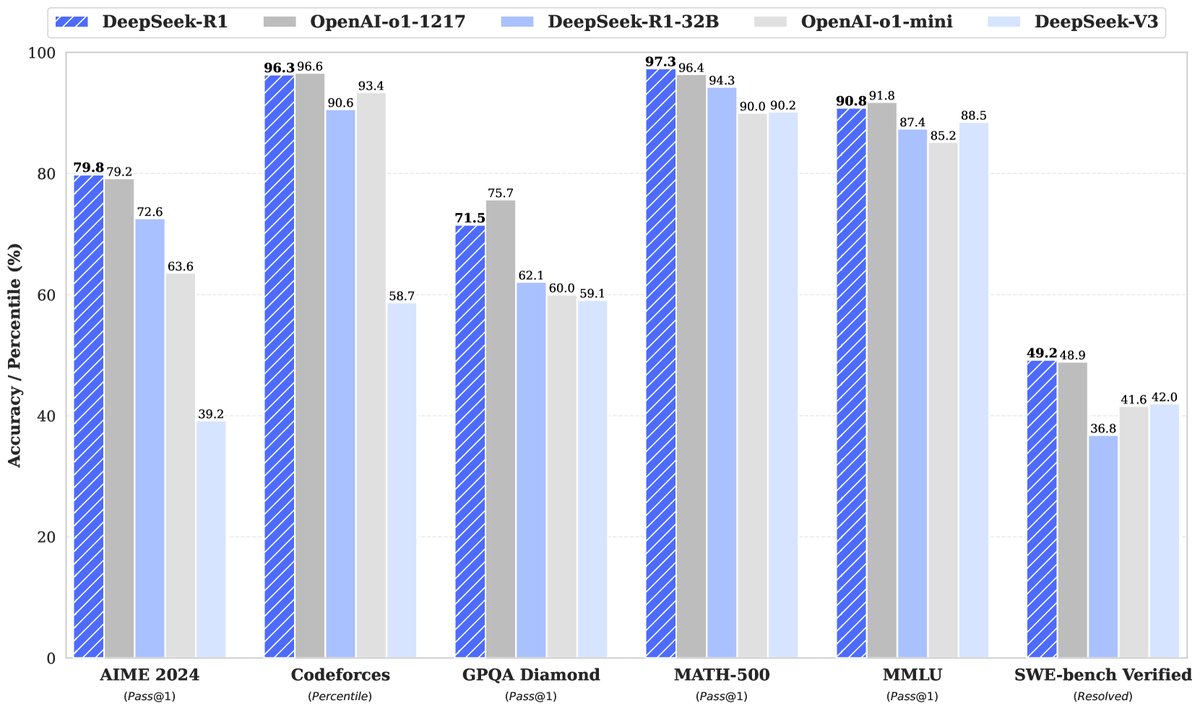
Key Results
- DeepSeek-R1 vs. Top-Tier Models:
- On reasoning tasks, DeepSeek-R1 performs exceptionally well, reaching a level comparable to or even slightly surpassing OpenAI-o1-1217 on math benchmarks such as AIME 2024 (pass@1 79.8%) and MATH-500 (pass@1 97.3%). On the programming competition task Codeforces, its Elo rating reaches 2029, surpassing 96.3% of human participants.
- On knowledge and general capabilities, DeepSeek-R1 significantly outperforms its predecessor DeepSeek-V3 on knowledge-intensive benchmarks such as MMLU and GPQA Diamond. It also achieves very high win rates on benchmarks evaluating open-ended generation ability, such as AlpacaEval 2.0 and ArenaHard, demonstrating that RL not only improves reasoning but also generalizes to other capabilities.
- Performance of DeepSeek-R1-Zero:
- DeepSeek-R1-Zero, trained with pure RL only, achieves a pass@1 of 71.0% on AIME 2024 and 86.7% after majority voting, with performance comparable to OpenAI-o1-0912, validating the huge potential of pure RL methods.
| Model | AIME 2024 | MATH-500 | GPQA | LiveCode | CodeForces | |
|---|---|---|---|---|---|---|
| pass@1 | cons@64 | pass@1 | Diamond pass@1 | Bench pass@1 | rating | |
| OpenAI-o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| OpenAI-o1-0912 | 74.4 | 83.3 | 94.8 | 77.3 | 63.4 | 1843 |
| DeepSeek-R1-Zero | 71.0 | 86.7 | 95.9 | 73.3 | 50.0 | 1444 |
- Performance of distilled models:
- The distillation method is extremely successful. For example, \(DeepSeek-R1-Distill-Qwen-7B\) comprehensively outperforms large general-purpose models such as GPT-4o on multiple reasoning benchmarks. The \(DeepSeek-R1-Distill-Qwen-32B\) and \(70B\) models significantly surpass o1-mini on most benchmarks, setting a new performance benchmark for dense models in the open-source community.
- Distillation vs. Direct RL: Comparative experiments show that distilling from the powerful DeepSeek-R1 to a 32B model yields performance that far exceeds what can be achieved by directly applying large-scale RL training to a 32B base model. This indicates that the “intelligent patterns” discovered by a stronger base model are crucial for improving the capabilities of smaller models.
| Model | AIME 2024 | MATH-500 | GPQA Diamond | LiveCodeBench | |
|---|---|---|---|---|---|
| pass@1 | cons@64 | pass@1 | pass@1 | pass@1 | |
| QwQ-32B-Preview | 50.0 | 60.0 | 90.6 | 54.5 | 41.9 |
| DeepSeek-R1-Zero-Qwen-32B | 47.0 | 60.0 | 91.6 | 55.0 | 40.2 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 |
Remaining Limitations
- DeepSeek-R1 still has shortcomings on some tasks. For example, due to safety alignment, it performs worse than DeepSeek-V3 on Chinese factual Q&A (C-SimpleQA). Its improvement on software engineering tasks (such as Aider) is also relatively limited.
- The model is quite sensitive to the prompt, with zero-shot prompts working best, while few-shot prompts may actually reduce its performance.
Final Conclusion
This paper successfully demonstrates that large-scale reinforcement learning can effectively stimulate and improve the reasoning ability of LLMs. DeepSeek-R1’s multi-stage pipeline not only achieves reasoning performance comparable to top industry models, but also balances output readability and generality. More importantly, the study finds that through distillation, this hard-won reasoning ability can be efficiently transferred to open-source models of various sizes, providing valuable resources and pathways for the development of the entire community.