CreativityPrism: A Holistic Benchmark for Large Language Model Creativity
-
ArXiv URL: http://arxiv.org/abs/2510.20091v1
-
Authors: Snigdha Chaturvedi; Anneliese Brei; Bhiman Kumar Baghel; Faeze Brahman; Zhaoyi Joey Hou; Meng Jiang; Ximing Lu; Daniel Khashabi; Yining Lu; Haw-Shiuan Chang; 11 others
-
Publishing Institutions: Allen Institute for Artificial Intelligence; Johns Hopkins University; University of Massachusetts Amherst; University of North Carolina; University of Notre Dame; University of Pittsburgh; University of Washington
TL;DR
This paper proposes a holistic evaluation framework called \(CreativityPrism\), which systematically assesses the creativity of large language models across three dimensions—quality, novelty, and diversity—through nine tasks and twenty metrics spanning three domains: divergent thinking, creative writing, and logical reasoning.
Key Definitions
The core of this paper revolves around the proposed \(CreativityPrism\) framework, and its decomposition of creativity is key to understanding the paper.
- CreativityPrism: A holistic, scalable benchmark for evaluating the creativity of large language models (LLMs). It consists of three domains—divergent thinking, creative writing, and logical reasoning—nine specific tasks, and twenty evaluation metrics, aiming to comprehensively measure model creativity.
- Quality: One of the creativity dimensions, used to assess whether generated content meets the basic requirements and functionality of the task. For example, in code generation, quality refers to whether the code can execute successfully and complete the task; in story writing, it refers to whether the story is coherent, grammatically correct, and satisfies the constraints.
- Novelty: One of the creativity dimensions, used to assess the originality or rarity of generated content compared with existing or common content. For example, in math problems, novelty refers to whether a solution different from the reference answer can be proposed; in the alternative uses task, it refers to whether unconventional uses can be imagined.
- Diversity: One of the creativity dimensions, used to assess differences among multiple outputs generated by the model. For example, in creative writing, diversity measures the lexical richness of generated stories; in divergent association tasks, it refers to the semantic differences among generated nouns.
Related Work
There are two major challenges in evaluating the creativity of large language models (LLMs). First, existing evaluation methods are fragmented, with different domains and tasks using vastly different definitions and measures of creativity, leading to inconsistent conclusions and making cross-task comparison difficult. For example, some tasks focus on lexical diversity, while others emphasize unconventional ideas, but all of them capture only a single aspect of creativity.
Second, many evaluation methods are not scalable, as they rely heavily on expensive and time-consuming human evaluation. As model iteration speeds up, there is an urgent need for a scalable, automated evaluation approach.
Therefore, this paper aims to address the current lack of a unified, comprehensive framework for evaluating LLM creativity. The authors’ goal is to create a holistic, scalable benchmark that integrates multiple tasks and dimensions to measure and compare the creativity of different LLMs in a unified way.
Method
This paper proposes \(CreativityPrism\), a holistic benchmark framework for evaluating machine creativity. Its core idea is that creativity is not a single concept, but a polyhedron that exhibits different traits in different domains (contexts), much like light refracted through a prism into a spectrum of different colors.
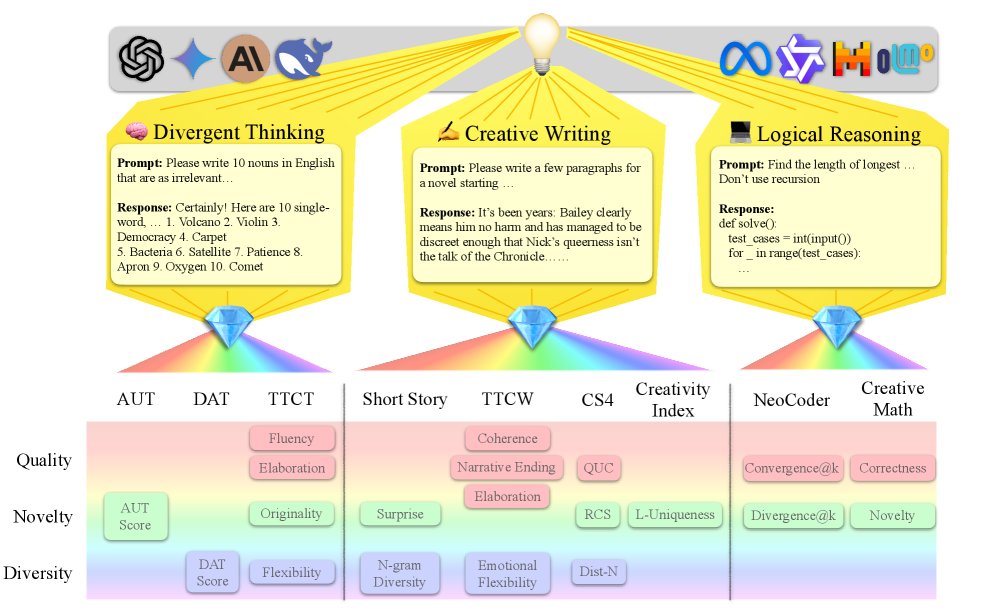
Framework Components
The \(CreativityPrism\) framework consists of three main parts:
- Three task domains: The framework covers three domains that test different aspects of creativity:
- Divergent Thinking: Includes classic psychology-based test tasks designed to assess the model’s ability to generate diverse, unconventional answers.
- Creative Writing: Includes tasks that require the model to write short texts, using either direct instructions or specific rule constraints to stimulate unconventional thinking.
- Logical Reasoning: Includes coding and math tasks used to assess the model’s ability to generate creative solutions under strict, explicit logical constraints.
- Nine specific tasks: The framework selects nine tasks (datasets) from prior work across the three domains above. These tasks all have scalable automated evaluation metrics and show good agreement with human judgment.
| Domain | Task | Example Input and Description |
|---|---|---|
| 🧠 Divergent Thinking | Alternative Use Task (AUT) | Input: a common everyday object. Task: come up with as many innovative uses as possible. |
| 🧠 Divergent Thinking | Divergent Association Task (DAT) | Input: 10 nouns. Task: find a word that is semantically as far as possible from those 10 words. |
| 🧠 Divergent Thinking | Torrance Test of Creative Thinking (TTCT) | Input: an incomplete figure. Task: complete the drawing and give it a title. |
| ✍️ Creative Writing | Creative Short Story (CSS) | Input: the beginning of a story. Task: continue it with a creative twist. |
| ✍️ Creative Writing | Creative Story with 4 constraints (CS4) | Input: 4 constraints (e.g., specific vocabulary, sentence patterns). Task: write a coherent story that satisfies all constraints. |
| ✍️ Creative Writing | Creativity Index (CI) | Input: a Wikipedia paragraph. Task: rewrite it in an innovative way while preserving the core information. |
| ✍️ Creative Writing | Torrance Test of Creative Writing (TTCW) | Input: a strange visual scene. Task: write a story around this scene. |
| 🧬 Logical Reasoning | NeoCoder | Input: a programming problem. Task: generate code that is different from the standard answer but still correctly solves the problem. |
| 🧬 Logical Reasoning | Creative Math | Input: a math problem. Task: generate a solution that is different from the reference solution but still correctly solves the problem. |
- Three evaluation dimensions: The core innovation of \(CreativityPrism\) is that it summarizes the twenty specific metrics across all tasks into three unified dimensions, enabling structured analysis:
- Quality: Measures whether the output is compliant and effective. For example, whether code runs successfully (\(convergent@0\)), or whether a story is coherent.
- Novelty: Measures whether the output is original and rare. For example, whether a code solution differs from the reference answer (\(divergent@0\)), or whether the rewritten text has low n-gram overlap with the training corpus.
- Diversity: Measures variation and richness within the outputs. For example, the lexical diversity of generated stories, or the semantic differences among multiple generated answers.
Innovations
The most essential innovation of this method is that it proposes a decomposed, structured evaluation system. Rather than trying to define creativity with a single metric, it breaks this vague concept down into three measurable and comparable dimensions: quality, novelty, and diversity. By unifying tasks and metrics from different domains within this framework, \(CreativityPrism\) achieves, for the first time, a comprehensive (holistic) and cross-domain systematic evaluation of LLM creativity.
Advantages
- Holistic: By covering multiple domains, it avoids the one-sidedness of single-task evaluation and can more comprehensively reflect a model’s creativity profile.
- Structured: The three-dimensional decomposition of quality-novelty-diversity provides a clear perspective for analyzing model capabilities, revealing strengths and weaknesses across different aspects of creativity.
- Scalability: The framework mainly relies on automated evaluation metrics, including reliable LLM-as-a-Judge methods, making it more efficient and easier to scale than traditional human evaluation and better suited to the rapid iteration of models.
Experimental Conclusions
This paper evaluated 17 state-of-the-art closed-source and open-source LLMs, revealing their performance in creativity.
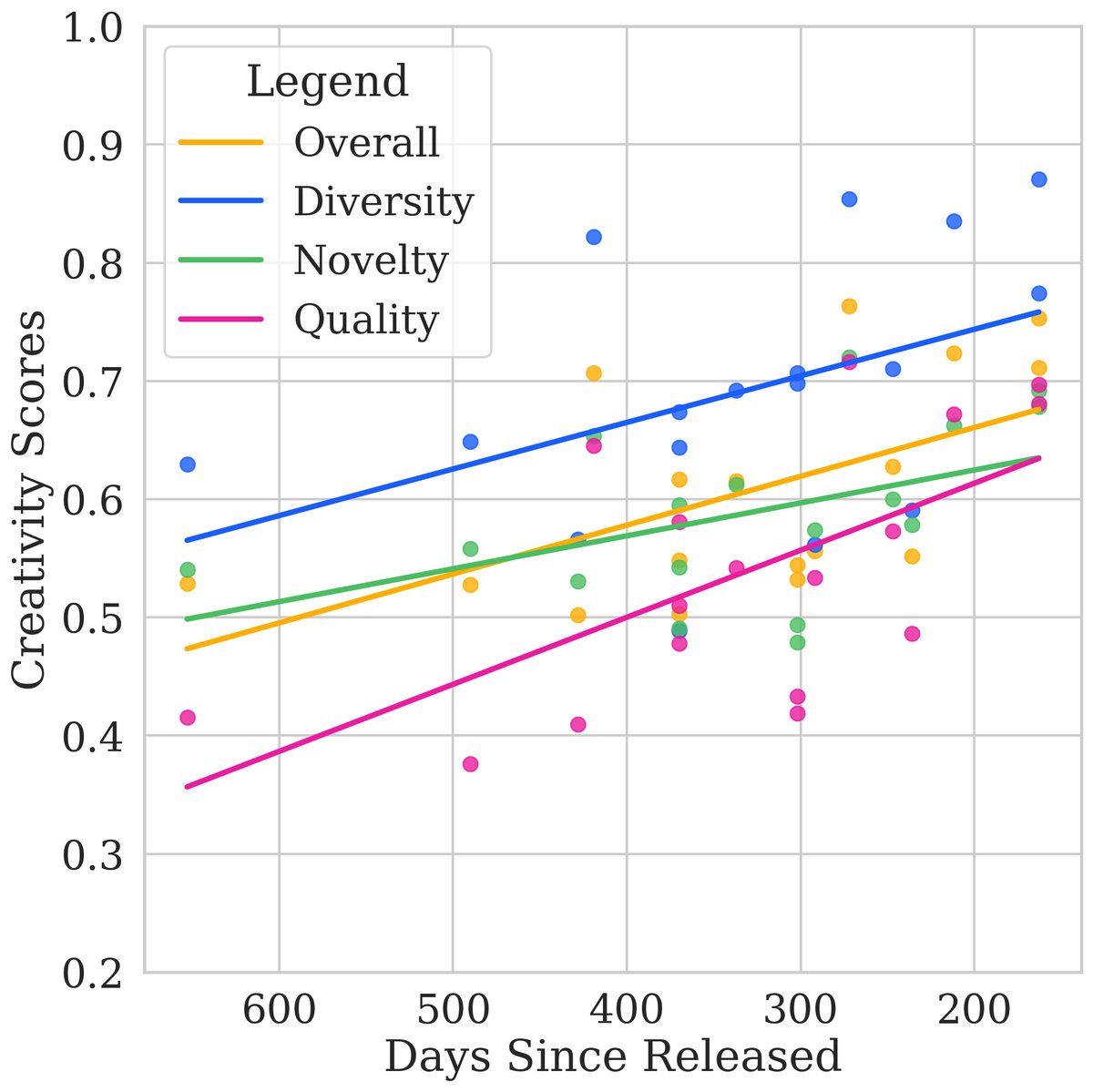
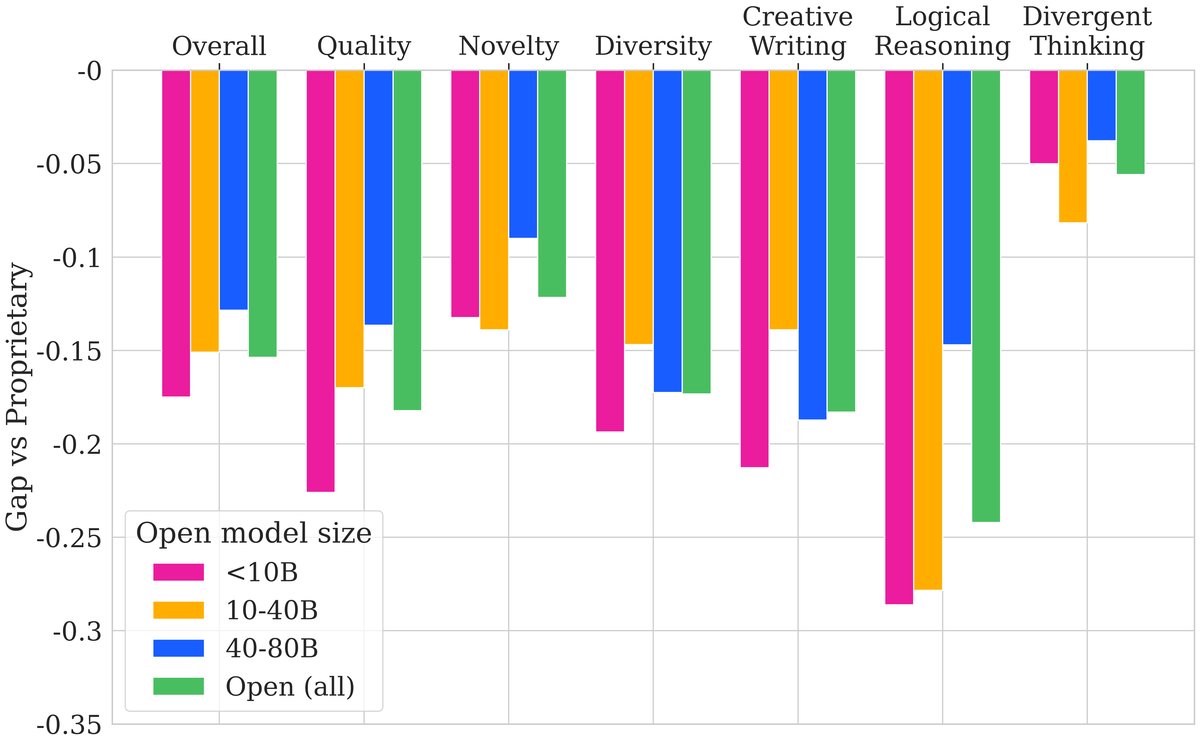
Key Experimental Results
- There is a significant gap between closed-source and open-source models: As shown in the overview table, the top closed-source models (such as GPT-4o and Claude-3-Opus) significantly outperform the best open-source models (such as Qwen2.5-72B and DeepSeek-V3) in overall creativity scores. This gap is especially pronounced in the fields of logical reasoning and creative writing, while it is relatively smaller in divergent thinking. Similarly, the gap is large in the quality and diversity dimensions, but smaller in the novelty dimension.
| Model Family | Model | 🧠 Div. Think. | ✍️ Crea. Writ. | 🧬 Log. Reas. | ✅ Quality | ✨ Novelty | 🎨 Diversity | 🏆 Overall |
|---|---|---|---|---|---|---|---|---|
| (Avg.) | 0.54 | 0.57 | 0.51 | 0.55 | 0.62 | 0.49 | 0.55 | |
| Proprietary | GPT-4o | 0.82 | 0.81 | 0.86 | 0.88 | 0.73 | 0.83 | 0.81 |
| Claude-3-Opus | 0.82 | 0.82 | 0.80 | 0.85 | 0.76 | 0.83 | 0.81 | |
| Gemini-1.5-Pro | 0.77 | 0.76 | 0.78 | 0.81 | 0.74 | 0.73 | 0.76 | |
| DeepSeek-V2 | 0.72 | 0.72 | 0.69 | 0.75 | 0.70 | 0.69 | 0.71 | |
| GPT-4-Turbo | 0.72 | 0.74 | 0.70 | 0.76 | 0.70 | 0.69 | 0.72 | |
| … | … | … | … | … | … | … | … | |
| Open-Source | Qwen2.5-72B | 0.77 | 0.73 | 0.58 | 0.71 | 0.72 | 0.64 | 0.69 |
| DeepSeek-Coder-V2 | 0.59 | 0.58 | 0.78 | 0.73 | 0.60 | 0.60 | 0.64 | |
| Llama-3-70B | 0.68 | 0.65 | 0.38 | 0.54 | 0.65 | 0.59 | 0.59 | |
| Qwen2-57B | 0.71 | 0.67 | 0.40 | 0.59 | 0.69 | 0.50 | 0.59 | |
| … | … | … | … | … | … | … | … |
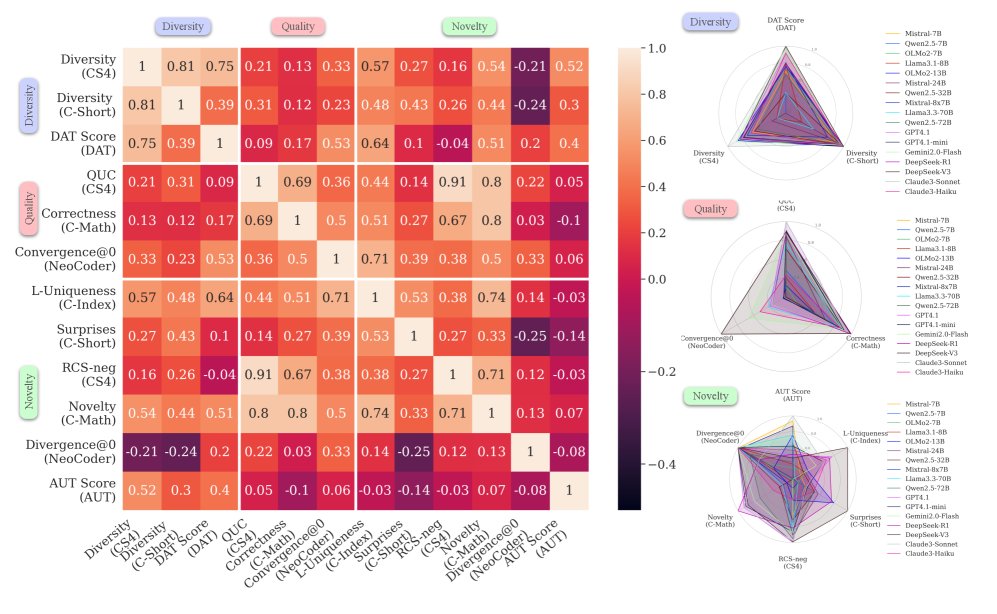
- Performance correlation analysis reveals the multifaceted nature of creativity:
- Within-dimension correlation: The metrics within the quality and diversity dimensions show strong correlations with one another. This means that a model that performs well in quality (or diversity) on one task also tends to perform well in quality (or diversity) on other tasks.
- The uniqueness of novelty: The metrics within the novelty dimension are weakly correlated, or even negatively correlated. This suggests that different tasks have very different definitions and requirements for “novelty” (for example, the novelty of code and the novelty of a story are two different abilities), and the novelty a model demonstrates in one domain cannot be generalized to another.
- Cross-dimension and cross-domain correlation: Performance correlations across different dimensions (such as quality vs. novelty) and across different domains (such as creative writing vs. logical reasoning) are generally low.
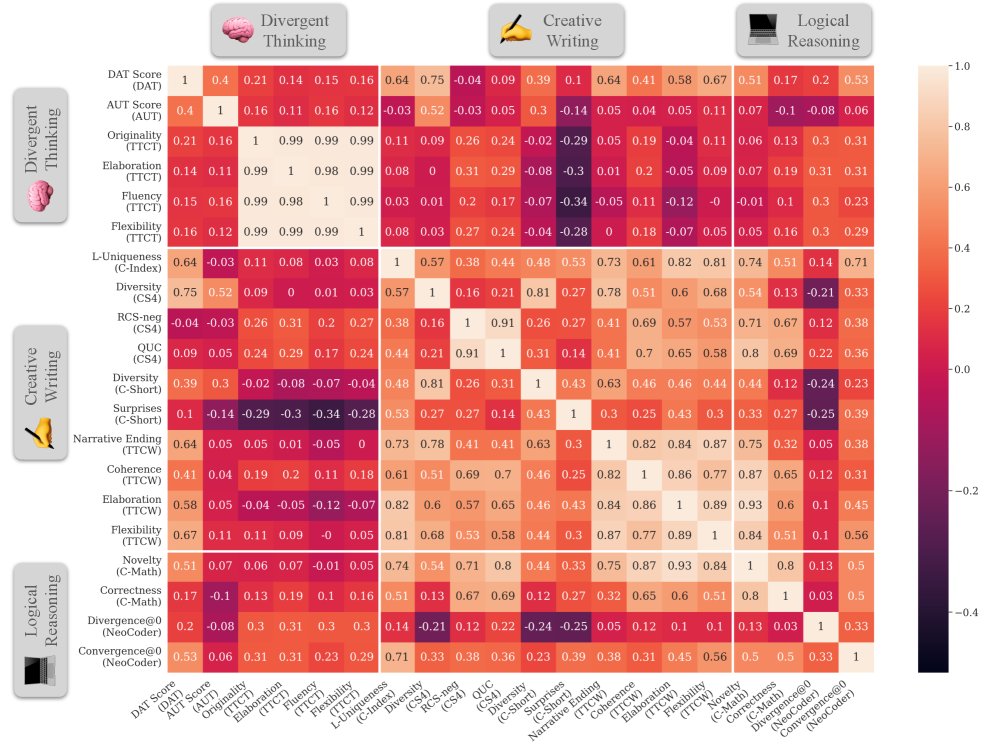
Conclusion
The experimental results strongly validate the paper’s core hypothesis: creativity is not a single ability, and excellent performance on one creativity task or dimension does not necessarily generalize to others. This highlights the necessity of a holistic, multidimensional evaluation framework like \(CreativityPrism\).
Ultimately, the proposed \(CreativityPrism\) provides a solid foundation for systematically measuring and understanding the creativity of LLMs, helping researchers and developers identify weaknesses in model creativity and pointing the way toward optimization for more creative AI. At the same time, the paper also acknowledges the limitations of the benchmark, such as being limited to English, possible LLM bias in evaluation, and text-only modality.