CogFlow: Bridging Perception and Reasoning through Knowledge Internalization for Visual Mathematical Problem Solving
Say No to “Seeing Right, Calculating Wrong”! CogFlow Pioneers a Knowledge Internalization Mechanism, Achieving SOTA in 7B Model Visual Mathematical Reasoning

Multimodal large language models (MLLMs) often exhibit a rather absurd phenomenon when handling visual math problems: the model clearly identifies the geometric elements in an image correctly (for example, recognizing that it is a right triangle), but in the subsequent reasoning and calculation, it completely ignores these visual cues and starts to “sound perfectly serious while talking nonsense.”
ArXiv URL:http://arxiv.org/abs/2601.01874v1
This phenomenon is known as Reasoning Drift. Existing models either mix everything together in a one-step reasoning process, or completely separate perception from reasoning, causing the “eyes” and the “brain” to work independently.
To address this pain point, a research team from Sichuan University, Tsinghua University, and Zhejiang University proposed a new human-cognition-inspired framework—CogFlow. For the first time, this framework explicitly simulates the hierarchical thought flow of human cognition: “perception $\Rightarrow$ internalization $\Rightarrow$ reasoning.” By introducing a unique “knowledge internalization” stage, it successfully bridges the gap between visual perception and logical reasoning. On authoritative benchmarks such as MathVerse and MathVista, CogFlow with only 7B parameters has shown the potential to surpass closed-source giants like GPT-4V.
Why do models always “see right but calculate wrong”?
Before diving into the technical details, we first need to understand the limitations of current approaches.
As shown in Figure 1, existing visual mathematical reasoning methods mainly fall into two camps:
-
One-step reasoning: directly asking the model to output the answer, which mixes perception and reasoning and is prone to errors.
-
Decoupled reasoning: first use one module to extract visual information, then hand it over to a language model for reasoning.
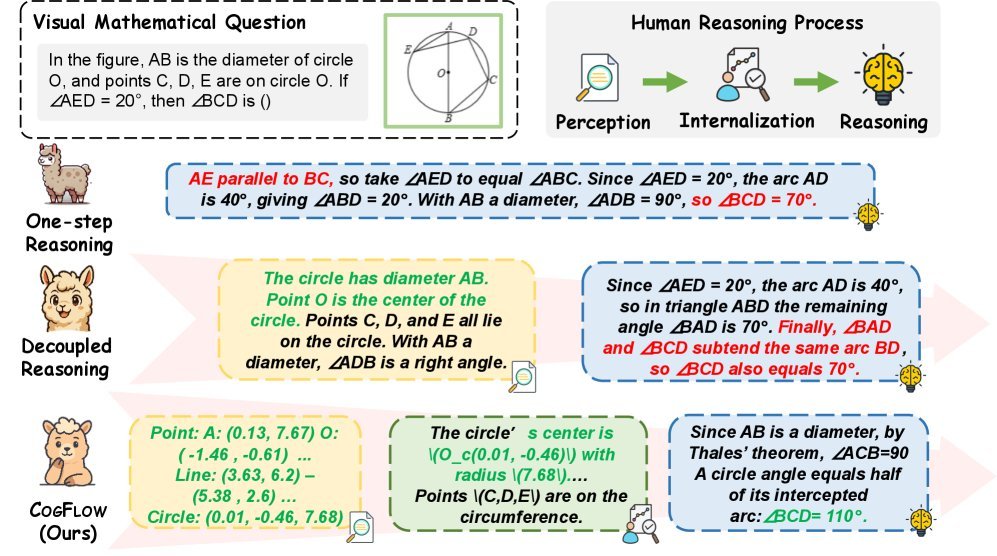
However, the research team found that although decoupled methods improve perception accuracy, the reasoning module often ignores the extracted visual clues, leading to Reasoning Drift. It is like a student who clearly copied down the conditions in the problem but then uses none of them when solving it, relying entirely on guesswork.
The core insight of CogFlow is that when humans solve math problems, they do not jump directly from “seeing the figure” to “writing formulas.” There is a crucial Knowledge Internalization process in between—transforming low-level visual signals into structured semantic knowledge that can be used for reasoning (for example, internalizing “seeing segment AB passing through the center of the circle” as the knowledge point “AB is a diameter”).
CogFlow: A Detailed Look at the Three-Stage Cognitive Architecture
CogFlow strictly follows the cognitive flow of “perception $\Rightarrow$ internalization $\Rightarrow$ reasoning,” and designs specialized enhancement mechanisms for each stage.
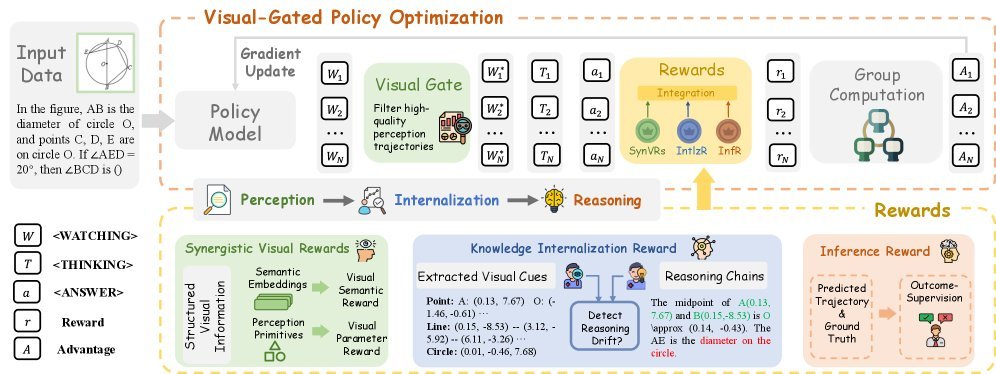
1. Perception Stage: Synergistic Visual Rewards (SynVRs)
To make the model “see” more accurately, CogFlow does not stop at simple text descriptions. Instead, it designs Synergistic Visual Rewards (SynVRs) and optimizes from two dimensions:
-
Visual Parameterized Reward (VPR): computes Euclidean distance in parameter space to ensure the precision of geometric primitives (points, lines, circles).
-
Visual Semantic Reward (VSR): re-renders the extracted text description into an image and computes its cosine distance from the original image in semantic space (CLIP embedding), ensuring consistency in overall layout and style.
This two-pronged strategy ensures that the visual cues extracted by the model are both geometrically accurate and globally semantically consistent.
2. Internalization Stage: Knowledge Internalization Reward (IntlzR)
This is the most innovative part of CogFlow. To prevent reasoning drift, the researchers introduced Knowledge Internalization Reward (IntlzR).
This module trains the model to recognize what constitutes “high-quality internalized knowledge” by comparing positive and negative sample trajectories. The research team summarized five common internalization failure modes (such as missing primitives, fabricating facts, and incorrectly citing theorems), and optimized them using the Softmax-DPO loss function. This step is like installing a “validator” in the model, ensuring that subsequent reasoning is strictly based on the perceived facts.
3. Reasoning Stage: Visual-Gated Policy Optimization (VGPO)
With accurate perception and internalized knowledge in place, how can we ensure the stability of multi-step reasoning? CogFlow proposes a Visual-Gated Policy Optimization (VGPO) algorithm.
The core idea of VGPO is very intuitive: if the first step is wrong, no amount of reasoning later can save it.
Therefore, VGPO introduces a “Visual Gate.” Before generating a reasoning chain, the model first generates multiple perception trajectories and uses the aforementioned SynVRs to evaluate their quality. Only high-quality perception results are allowed through the “gate” and into the subsequent reasoning generation stage. If all perception results are poor, the model will try regenerating until it is satisfied.
Experimental Results: The Comeback of a 7B Model
To train CogFlow, the research team also built a new dataset called MathCog, containing 120K high-quality samples with fine-grained perception-reasoning alignment annotations.
Experimental results on multiple mainstream benchmarks such as FlowVerse, MathVerse, and MathVista show that CogFlow achieves significant performance gains.
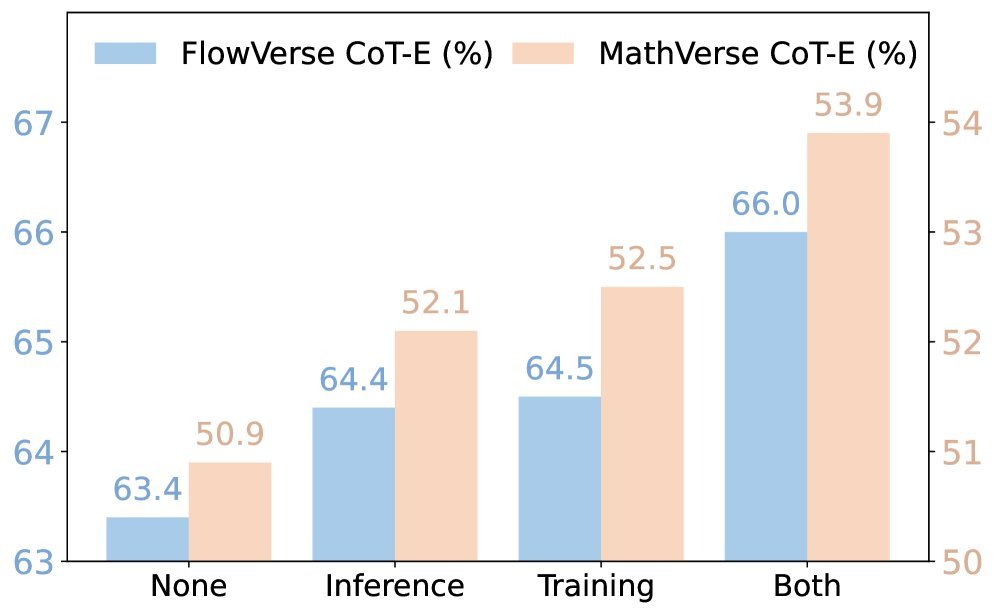
From the table above, we can see that:
-
CogFlow-7B comprehensively outperforms open-source models of the same scale on multiple leaderboards, such as Qwen-VL-Chat and InternLM-XC2.
-
Surprisingly, on highly challenging benchmarks such as FlowVerse and MathVerse, the 7B-parameter CogFlow even beats closed-source large models like GPT-4V and Gemini-Pro.
-
In particular, CogFlow’s advantage is especially pronounced on Vision Intensive sub-tasks, directly demonstrating the effectiveness of its perception enhancement and knowledge internalization mechanisms.
Conclusion
CogFlow’s success proves that in multimodal reasoning tasks, simply “brute-forcing it” by scaling up parameters and data is not the only path. By drawing on the achievements of cognitive science, explicitly modeling the hierarchical structure of “perception-internalization-reasoning,” and using reinforcement learning (RL) to finely align each stage, even small models can show astonishing breakout performance on complex visual mathematical reasoning tasks.
This work not only addresses the long-standing problem of “reasoning drift,” but also offers a new direction for future MLLMs to develop toward more rigorous and more interpretable logical reasoning.