Budget-Aware Tool-Use Enables Effective Agent Scaling
AI Agent Only “Burns Through” Compute? Google’s BATS Framework Teaches It to Be Frugal, Optimizing Both Cost and Performance

As AI Agents become increasingly powerful, we tend to assume that giving them more compute and more tool calls should make them perform better. But is that really the case? Google’s latest research reveals a counterintuitive phenomenon: simply increasing an Agent’s budget quickly hits a “ceiling,” after which performance no longer improves. What’s going wrong? It turns out these Agents lack a crucial capability—budget awareness. They’re like employees with no concept of a budget: even when resources are abundant, they don’t know how to dig deeper or adjust their strategy.
Paper Title: Budget-Aware Tool-Use Enables Effective Agent Scaling ArXiv URL: http://arxiv.org/abs/2511.17006v1
To solve this problem, Google DeepMind and other institutions introduced a brand-new intelligent framework called BATS, which teaches Agents how to be “frugal” and maximize performance within a limited budget.
Performance Bottleneck: Agents That Can “Act” but Don’t Know How to “Plan”
For tool-augmented agents that need to interact with the external environment, capability scaling depends not only on internal “thinking” (which consumes Tokens), but also on external “actions” (such as calling tools like web search).
The number of tool calls directly determines the breadth and depth of the Agent’s exploration of external information.
However, the research found that standard Agents, such as those based on the ReAct framework, cannot effectively use increased tool-call budgets. They often perform shallow searches and, once they think they have found a “good enough” answer or get stuck, they terminate the task early, completely unaware that a large amount of resources remain unused.
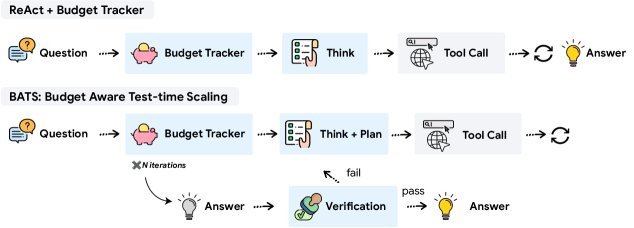 Figure 1: The Budget Tracker can be applied to both standard ReAct Agents (top) and the more advanced BATS framework (bottom). The blue boxes indicate modules that are adjusted according to the budget.
Figure 1: The Budget Tracker can be applied to both standard ReAct Agents (top) and the more advanced BATS framework (bottom). The blue boxes indicate modules that are adjusted according to the budget.
This raises a core question: how can we enable Agents to achieve the most effective performance scaling under a given resource budget?
The First Breakthrough: A Lightweight “Budget Tracker”
The research team first proposed a simple yet highly effective solution: the Budget Tracker.
This is a plug-and-play lightweight module that, after each action taken by the Agent, uses a Prompt to explicitly tell the Agent: “How many tool calls do you still have left?”
 Figure 2: In each round of interaction, before generating the next thought and tool call, the Agent learns its current and remaining budget through the Budget Tracker.
Figure 2: In each round of interaction, before generating the next thought and tool call, the Agent learns its current and remaining budget through the Budget Tracker.
Don’t underestimate this simple reminder! It gives the Agent a clear sense of resource consumption and remaining budget, allowing it to adjust subsequent reasoning and action strategies.
The experimental results prove its power. As shown below, without budget awareness, the performance of the standard ReAct Agent saturates once the budget reaches 100. After adding the Budget Tracker, the Agent can continue to make use of the increased budget, and performance rises steadily, successfully breaking through the performance ceiling.
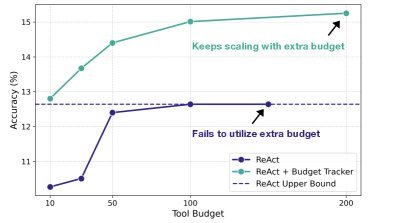 Figure 3: On the BrowseComp dataset, the standard ReAct Agent (blue dashed line) quickly saturates, while the budget-aware Agent (orange solid line) continues to scale performance.
Figure 3: On the BrowseComp dataset, the standard ReAct Agent (blue dashed line) quickly saturates, while the budget-aware Agent (orange solid line) continues to scale performance.
BATS: An Intelligent Framework for Dynamic Planning and Verification
After demonstrating the effectiveness of “budget awareness,” the research team further developed a more advanced BATS (Budget Aware Test-time Scaling) framework, deeply integrating budget awareness into the Agent’s entire workflow.
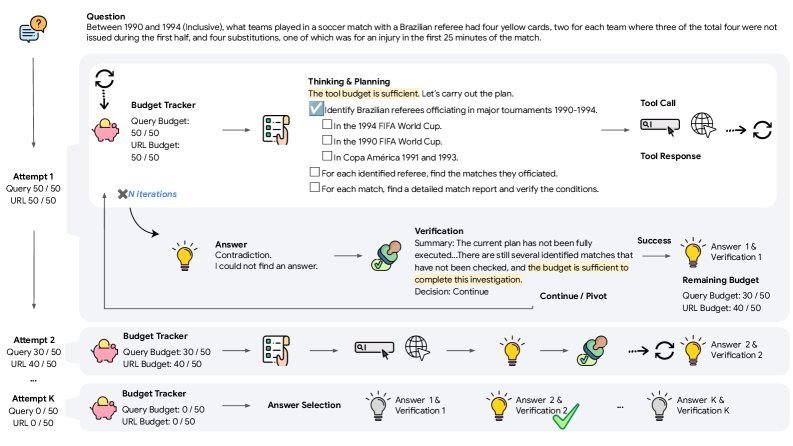 Figure 6: Overview of the BATS framework. The Agent starts with budget-aware thinking and planning, and continuously updates its strategy during iteration based on new information and the budget. After proposing an answer, BATS performs verification and decides whether to continue, pivot, or retry based on the remaining budget.
Figure 6: Overview of the BATS framework. The Agent starts with budget-aware thinking and planning, and continuously updates its strategy during iteration based on new information and the budget. After proposing an answer, BATS performs verification and decides whether to continue, pivot, or retry based on the remaining budget.
The core design principle of BATS is to keep budget awareness throughout the entire process, mainly reflected in two intelligent modules:
-
Budget-Aware Planning: At the start of a task, BATS guides the Agent to decompose the problem and identify which clues are “exploratory” for expanding the search space and which are “verificatory” for checking specific information. Based on the remaining budget, the Agent dynamically decides whether to explore broadly first or verify directly, avoiding premature exhaustion of resources on uncertain paths.
-
Budget-Aware Self-verification: When the Agent proposes an initial answer, BATS does not end hastily. The verification module traces back through the entire reasoning process to check whether all problem constraints have been satisfied. More importantly, it makes decisions based on the remaining budget:
- If the budget is sufficient and the current path looks promising, it decides to dig deeper.
- If the current path seems blocked but budget remains, it chooses to pivot, opening a new exploration path.
- Only when the answer is reliable and the budget is tight does it confirm and output the final answer.
Experimental Results: A Better Cost-Performance Curve
To fairly evaluate the efficiency of different methods, the study proposes a unified cost metric that takes into account both Token consumption and tool-call costs.
\[C\_{\textit{unified}}(x;\pi)=\underbrace{c\_{\textit{token}}(x;\pi)}\_{\text{Token Cost}}+\underbrace{\sum\_{i=1}^{K}c\_{i}(x;\pi)\cdot P\_{i}}\_{\text{Total Tool Cost}}\]On several challenging information retrieval tasks such as BrowseComp, BrowseComp-ZH, and HLE-Search, BATS performs remarkably well.
Most notably, BATS is a fully training-free framework. By introducing budget-aware intelligent strategies only at inference time, it achieves better performance than many specially fine-tuned Agents under strict budget constraints. For example, when using the Gemini-2.5-Pro model, BATS achieves 24.6% accuracy on BrowseComp.
The figure below clearly shows BATS’s major advantage in the cost-performance trade-off. It pushes forward the cost-performance Pareto frontier, meaning that at the same cost, BATS can achieve higher accuracy; or, to reach the same accuracy, BATS requires lower cost.
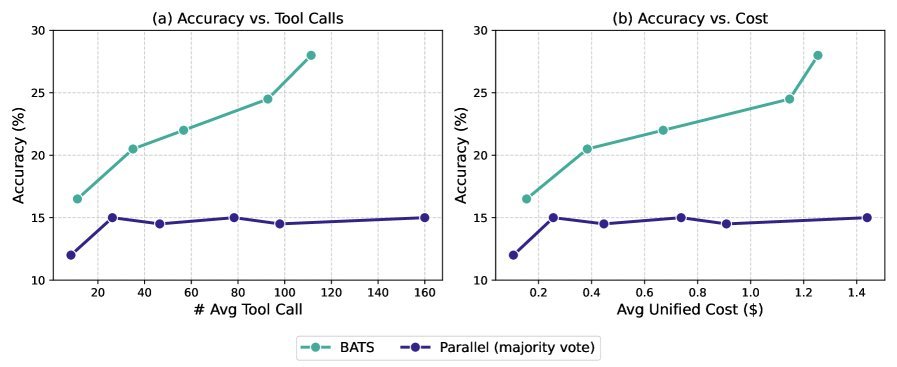 Figure 7: Under the unified cost metric, BATS (orange) shows a superior scaling curve compared with baseline methods (blue), delivering better cost-effectiveness.
Figure 7: Under the unified cost metric, BATS (orange) shows a superior scaling curve compared with baseline methods (blue), delivering better cost-effectiveness.
Conclusion
This study is the first to systematically explore the performance scaling of tool-augmented Agents under budget constraints. It reveals that “budget awareness” is the key to unlocking an Agent’s potential.
From a simple “Budget Tracker” to the sophisticated BATS framework, this work demonstrates that teaching Agents to be frugal not only breaks through performance bottlenecks, but also significantly improves cost efficiency. It points to a highly promising direction for building more efficient, more reliable, and more controllable AI Agent systems in the future.