BrowseConf: Confidence-Guided Test-Time Scaling for Web Agents
-
ArXiv URL: http://arxiv.org/abs/2510.23458v2
-
Authors: Yong Jiang; Pengjun Xie; Xixi Wu; Litu Ou; Rui Ye; Huifeng Yin; Jingren Zhou; Kuan Li; Zhongwang Zhang; Zile Qiao; and 11 others
-
Publishing Organization: Alibaba Group; Tongyi Lab
TL;DR
This paper proposes a test-time scaling (TTS) method called BrowseConf. By leveraging a large language model intelligent agent’s “verbalized confidence” in its own answers, it dynamically decides whether additional computation attempts are needed, thereby significantly improving the computational efficiency of web information retrieval tasks while maintaining task performance.
Key Definitions
The core method in this paper is built on the following key concepts:
- Verbalized Confidence: A model-agnostic confidence estimation method. By adding a specific instruction in the prompt, the model outputs a self-assessed confidence score (0-100 in this paper) while generating the final answer.
- BrowseConf: The core method proposed in this paper. It is a confidence-based test-time scaling strategy that dynamically allocates computational resources according to the intelligent agent’s reported verbalized confidence. A new round of solving attempts is launched only when the confidence falls below a preset threshold.
- Confidence Threshold ($\tau$): A pre-set decision boundary. If the intelligent agent’s current attempt has a confidence score $C_i < \tau$, the result is considered unreliable and another attempt is made; otherwise, the current answer is accepted and the process terminates. This threshold is determined by calibration on a validation set.
- BrowseConf Variants:
- BrowseConf-Zero: The most basic variant. When another attempt is needed, it starts completely from scratch, retaining no information from previous attempts.
- BrowseConf-Summary: A knowledge transfer strategy. Before starting a new attempt, the model is asked to summarize the previous low-confidence attempt, and the summary is fed as additional input to guide the next attempt.
- BrowseConf-Neg: A negative constraint strategy. All incorrect answers produced by previous low-confidence attempts are provided to the model, along with an explicit instruction to generate a new answer different from all of them.
Related Work
Even state-of-the-art large language models (LLMs) still produce hallucinations and overconfident errors. Although the academic community has explored various confidence estimation methods, such as verbalized scores, token probabilities, and self-reflection, most of this work focuses on single-step, non-interactive tasks.
For complex intelligent agent tasks that require multiple rounds of interaction with the external environment, such as the web, confidence estimation remains underexplored. In such long-horizon tasks, intelligent agents are prone to forgetting previously acquired information or struggling to recover from early mistakes, making the final confidence assessment unreliable.
At the same time, existing test-time scaling (TTS) techniques, such as Self-Consistency, typically use a fixed multi-sample rollout strategy for all questions. This wastes substantial computational resources when the intelligent agent can already solve some questions with ease.
The problem this paper aims to solve is: how to use computational resources more efficiently in complex web information retrieval intelligent agent tasks, avoiding unnecessary repeated computation on easy questions while improving the ability to solve difficult ones.
Method
The paper first experimentally demonstrates that, in complex web browsing tasks, there is a strong positive correlation between an intelligent agent’s verbalized confidence and its task accuracy. As shown in the figure below, although the model is generally overconfident (reported confidence far exceeds actual accuracy), higher confidence scores do correspond to higher accuracy.
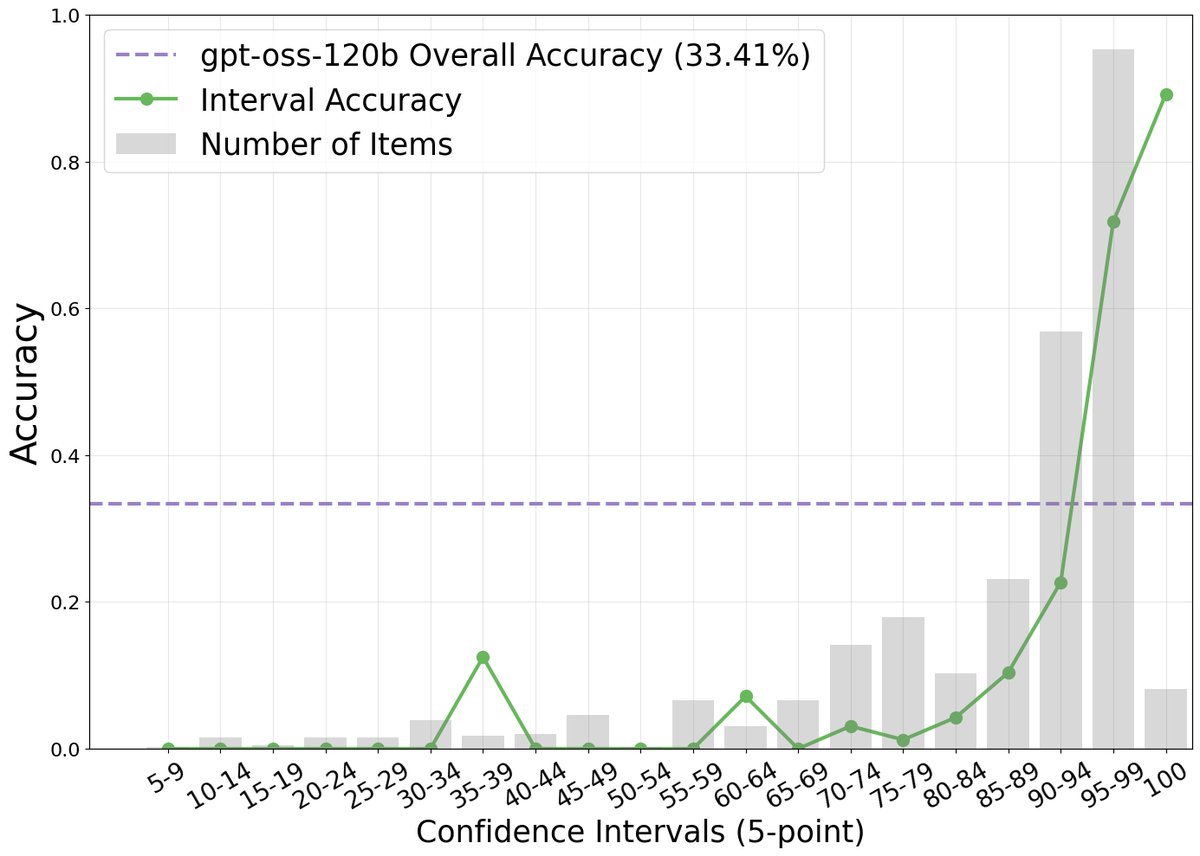
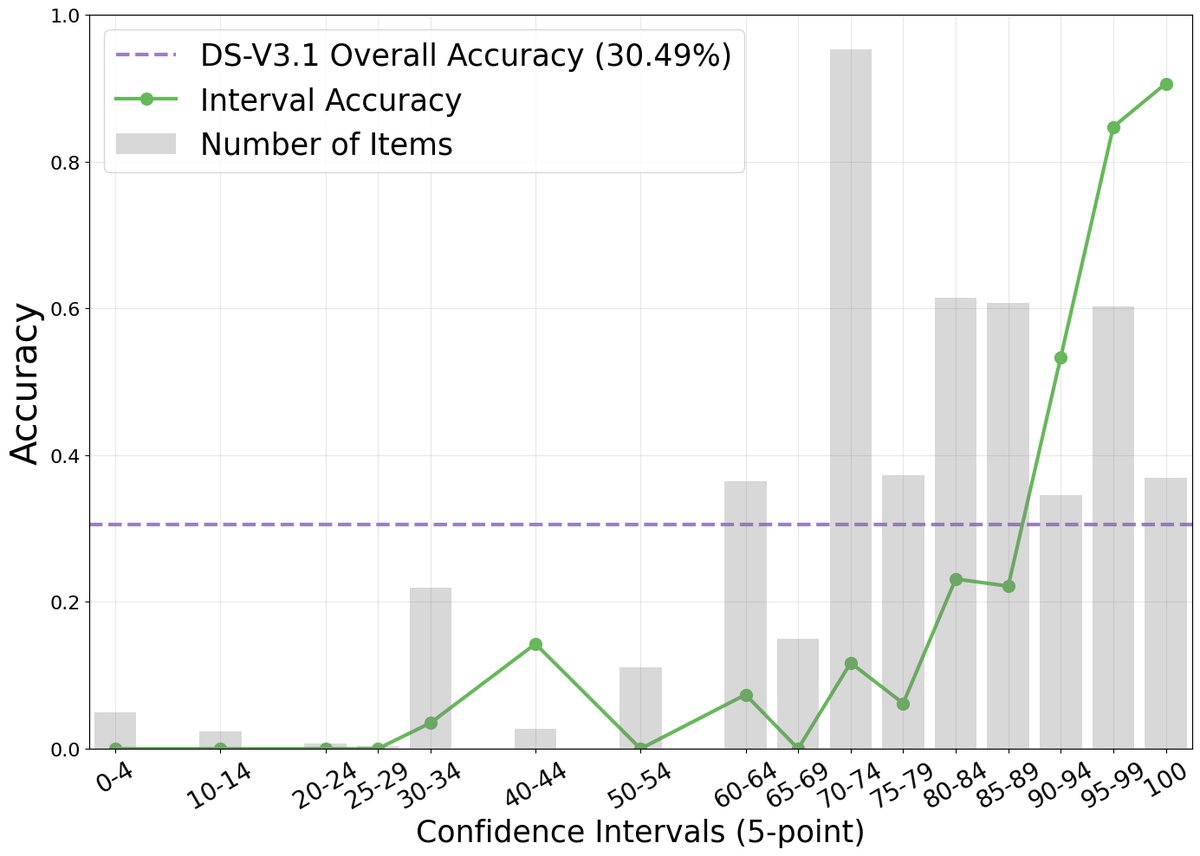
Innovation
Based on this finding, the paper proposes BrowseConf, a test-time scaling method that dynamically allocates computation budget according to confidence. Its core innovation is to use the intelligent agent’s own confidence judgment to trigger computation dynamically, rather than adopting a fixed, uniform computational cost.
Core Algorithm
For a given query $q$, the procedure is as follows:
- The intelligent agent makes the $i$-th attempt, generating answer $A_i$ and confidence score $C_i$.
- Determine whether $C_i$ is greater than or equal to the preset confidence threshold $\tau$.
- If $C_i \geq \tau$, the answer is considered reliable, the process terminates, and $A_i$ is returned.
- If $C_i < \tau$ and the total number of attempts has not reached the upper limit $N$, the next attempt is launched.
- If none of the $N$ attempts reaches the confidence threshold, return the answer $A_{best}$ with the highest confidence among all attempts.
Threshold Calibration
To avoid test set leakage, the confidence threshold $\tau$ is calibrated on an independent validation set (the paper uses a subset of SailorFog-QA). The criterion for selecting $\tau^*$ is: find the smallest confidence score such that the subset of samples above that score achieves at least a $k\%$ relative improvement in accuracy over the overall accuracy of the entire validation set. The formula is:
\[\tau^{*}=\min\bigg\{\tau\in[0,100]\mid\frac{\text{Acc}(\{x\in D_{val}\mid C\geq\tau\})-\text{Acc}(D_{val})}{\text{Acc}(D_{val})}\geq\frac{k}{100}\bigg\}\]Advantages
The core advantage of BrowseConf is computational efficiency. It effectively avoids redundant computation attempts on problems where the intelligent agent is already highly confident, putting compute to “good use” and performing multiple explorations only on difficult questions the intelligent agent is uncertain about. As a result, it can greatly reduce average computational cost while matching or even surpassing the performance of fixed-budget methods.
Method Variants
To further improve efficiency across multiple attempts, the paper also proposes two enhanced strategies that leverage information from previous failed attempts:
- BrowseConf-Summary: This variant asks the model to summarize the low-confidence attempt, extracting key entities, contradictions, and unfinished reasoning steps. The summary is then used as additional information to guide the next attempt and avoid repeated exploration.
- BrowseConf-Neg: This variant provides the model with the set of low-confidence answers produced in all previous attempts and explicitly instructs it to generate a new answer different from all of them, thereby constraining the search space and avoiding known wrong paths.
Experimental Conclusions
Experiments were conducted on the gpt-oss-120b and DeepSeek-V3.1 models, as well as on the two challenging information-seeking benchmarks BrowseComp and BrowseComp-zh.
Main Results
As shown in the table below, the BrowseConf family of methods achieves performance comparable to strong baseline methods such as Self-Consistency and CISC, and in some cases even better.
| Model | Method | BrowseComp (English) | BrowseComp-zh (Chinese) |
|---|---|---|---|
| gpt-oss-120b | |||
| Pass@1 | 33.8 / 1 | 38.0 / 1 | |
| Pass@10 | 70.3 / 10 | 74.7 / 10 | |
| Self-Consistency (10) | 47.5 / 10 | 50.5 / 10 | |
| CISC (10) | 52.2 / 10 | 53.3 / 10 | |
| BrowseConf-Zero | 52.1 / 3.76 | 51.6 / 2.32 | |
| BrowseConf-Summary | 48.7 / 2.06 | 49.2 / 2.09 | |
| BrowseConf-Neg | 52.5 / 3.87 | 54.5 / 2.43 | |
| DeepSeek-V3.1 | |||
| Pass@1 | 29.5 / 1 | 51.1 / 1 | |
| Pass@10 | 68.6 / 10 | 82.0 / 10 | |
| Self-Consistency (10) | 36.7 / 10 | 61.1 / 10 | |
| CISC (10) | 38.7 / 10 | 59.8 / 10 | |
| BrowseConf-Zero | 41.3 / 5.67 | 59.2 / 3.42 | |
| BrowseConf-Summary | 40.1 / 5.14 | 53.4 / 3.74 | |
| BrowseConf-Neg | 41.7 / 5.72 | 54.3 / 3.68 |
Table note: Each cell is formatted as “accuracy (%) / average number of attempts”.
- Performance and efficiency: The BrowseConf methods are highly competitive in accuracy while significantly reducing computational cost. For example, on gpt-oss-120b, BrowseConf-Neg achieved the highest accuracy, while the average number of attempts was only 2.43-3.87, far below the fixed 10 attempts used by the baseline methods.
- Variant comparison: Among the three variants, BrowseConf-Neg (negative constraints) usually achieves the highest task accuracy. BrowseConf-Summary (summary guidance) performs best in computational efficiency, requiring the fewest average attempts. BrowseConf-Zero (from scratch) offers a balance between performance and efficiency.
Ablation Study and Analysis
-
Effect of the confidence threshold: Experiments show that a stricter confidence threshold (i.e., a larger $k\%$) can lead to higher final accuracy, but at the cost of more average attempts. This reveals a trade-off between accuracy and computational cost.
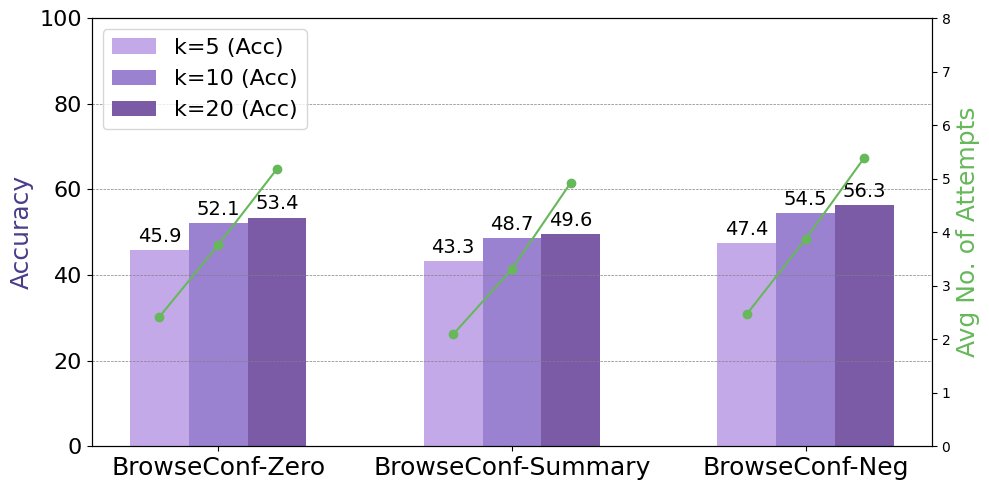
-
Interaction changes across consecutive attempts: Analysis shows that BrowseConf-Summary and BrowseConf-Neg, which carry historical information, significantly reduce the number of interaction steps (thought-action-observation loops) required in later attempts. This demonstrates that leveraging information from previous attempts enables the intelligent agent to solve problems more efficiently.
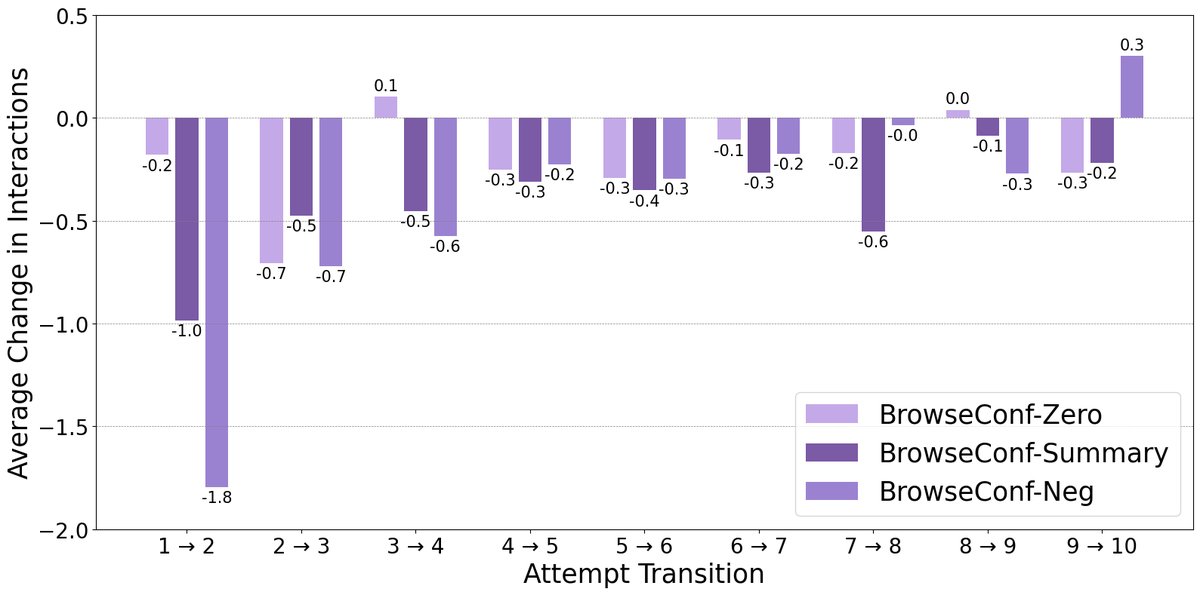
Conclusion
This paper confirms that verbalized confidence is a reliable signal for evaluating an intelligent agent’s performance on complex tasks. Based on this, the proposed BrowseConf method dynamically allocates computational resources, significantly outperforming traditional fixed-budget TTS methods in computational efficiency while maintaining high task accuracy, offering a new approach to building more efficient and intelligent AI intelligent agent.