BloombergGPT: A Large Language Model for Finance
-
ArXiv URL: http://arxiv.org/abs/2303.17564v3
-
Authors: Steven Lu; Sebastian Gehrmann; Vadim Dabravolski; Ozan Irsoy; Shijie Wu; Mark Dredze; D. Rosenberg; Gideon Mann; P. Kambadur
-
Publishing Organization: Bloomberg; Johns Hopkins University
TL;DR
This paper proposes BloombergGPT, a 50-billion-parameter large language model built specifically for the financial domain. By training on a mixed dataset containing a large amount of high-quality financial data and general data, it achieves performance far beyond existing models on financial tasks while remaining highly competitive on general LLM benchmarks.
Key Definitions
- BloombergGPT: A 50-billion-parameter, decoder-only causal language model. What makes it unique is that its training data includes both large-scale finance-specific data and general public datasets, with the goal of optimizing both domain specificity and general capability.
- FinPile: A large, domain-specific financial text dataset constructed in this paper, containing 363 billion tokens. The dataset is drawn from Bloomberg’s four decades of financial data archives, including company earnings reports, financial news, press releases, web financial documents, and social media, making it one of the largest domain-specific datasets to date.
- Mixed Data Training: The core training strategy used in this paper. Unlike models that rely entirely on general data or entirely on domain data, this approach uses about half of the training data (FinPile) for the financial domain and the other half (such as The Pile and C4) for the general domain. This strategy is intended to enable the model to acquire both financial expertise and terminology while preserving its ability to generalize to general tasks.
Related Work
Current large language models (LLMs) mainly fall into two categories. One category consists of ultra-large models such as GPT-3 and PaLM, trained on general, broad topics. They demonstrate strong generalization and emergent abilities, such as few-shot learning, but lack deep understanding of specific domains. The other category consists of models focused on specific domains, such as science or medicine. These models perform better than general models on in-domain tasks, but are usually smaller in scale and trained entirely on domain data, which may come at the cost of generality.
The FinTech domain involves many complex natural language processing tasks, such as sentiment analysis, named entity recognition, and question answering. Its specialized terminology and contextual complexity place very high demands on models. However, before this paper, there had been no LLM specifically designed and optimized for the financial domain.
The problem this paper aims to solve is: how to build a model that can achieve state-of-the-art performance on complex financial tasks while remaining competitive on general LLM benchmarks, in order to meet the financial industry’s dual needs for high accuracy, specialization, and versatility.
Method
Core Idea: Mixed Data Training
The core innovation of BloombergGPT lies in its training strategy. Rather than fine-tuning a general model or training a purely financial model from scratch, the authors pioneered a mixed data training approach. They constructed a massive training corpus of more than 700 billion tokens, of which about 51% is high-quality, carefully curated financial-domain data (FinPile) and about 49% is general public datasets. The assumption behind this design is that domain data can give the model deep expertise, while general data ensures broad language understanding and reasoning ability, thereby combining “specialist” and “generalist” strengths.
Training Data: FinPile and Public Datasets
The construction of the training data is one of the key contributions of this paper. The entire dataset contains more than 700 billion tokens and is deduplicated before training.
| Dataset | Files (1e4) | Avg. chars/file (1e4) | Chars (1e8) | Avg. chars/Token | Tokens (1e8) | Token Share |
|---|---|---|---|---|---|---|
| FinPile | 175,886 | 1,017 | 17,883 | 4.92 | 3,635 | 51.27% |
| Web | 158,250 | 933 | 14,768 | 4.96 | 2,978 | 42.01% |
| News | 10,040 | 1,665 | 1,672 | 4.44 | 376 | 5.31% |
| Filings | 3,335 | 2,340 | 780 | 5.39 | 145 | 2.04% |
| Press | 1,265 | 3,443 | 435 | 5.06 | 86 | 1.21% |
| Bloomberg | 2,996 | 758 | 227 | 4.60 | 49 | 0.70% |
| PUBLIC | 50,744 | 3,314 | 16,818 | 4.87 | 3,454 | 48.73% |
| C4 | 34,832 | 2,206 | 7,683 | 5.56 | 1,381 | 19.48% |
| Pile-CC | 5,255 | 4,401 | 2,312 | 5.42 | 427 | 6.02% |
| GitHub | 1,428 | 5,364 | 766 | 3.38 | 227 | 3.20% |
| … | … | … | … | … | … | … |
| TOTAL | 226,631 | 1,531 | 34,701 | 4.89 | 7,089 | 100.00% |
Table 1: Overview of the composition of BloombergGPT’s full training set. (Some public dataset details are omitted in the table.)
Financial Dataset (FinPile, 363 Billion Tokens)
FinPile is the finance-specific dataset constructed in this paper, sourced from documents accumulated by Bloomberg over the past four decades, spanning 2007 to 2022.
- Web (298 billion Tokens): High-quality website content containing finance-related information, crawled by Bloomberg.
- News (38 billion Tokens): From hundreds of reputable financial news sources, excluding Bloomberg’s own news.
- Filings (14 billion Tokens): Mainly company filings such as 10-K and 10-Q from the U.S. Securities and Exchange Commission (SEC) EDGAR database; these documents are information-dense and have special formats.
- Press (9 billion Tokens): Official company press releases related to finance.
- Bloomberg (5 billion Tokens): Bloomberg’s own in-depth analysis and real-time news, among others.
| Date | Bloomberg | Filings | News | Press | Web | Total |
|---|---|---|---|---|---|---|
| 2007 [03-] | 276 | 73 | 892 | 523 | 2,667 | 4,431 |
| 2008 | 351 | 91 | 1,621 | 628 | 9,003 | 11,695 |
| … | … | … | … | … | … | … |
| 2022 [-07] | 140 | 882 | 2,206 | 531 | 16,872 | 20,631 |
| Total | 4,939 | 14,486 | 37,647 | 8,602 | 297,807 | 363,482 |
Table 2: Distribution of token counts (millions) in the FinPile dataset by year and type.
Public Datasets (345 Billion Tokens)
To ensure the model’s general capabilities, the training data also includes three widely used public datasets:
- The Pile (184 Billion Tokens): A diverse open-source dataset covering multiple domains such as academic text, code (GitHub), and legal text (FreeLaw), helping improve the model’s generalization ability.
- C4 (138 Billion Tokens): A heavily cleaned general web-crawled corpus.
- Wikipedia (24 Billion Tokens): Contains an English Wikipedia snapshot from July 2022, providing the model with up-to-date factual knowledge.
Tokenization
Instead of using common algorithms such as BPE, this paper chose a Unigram Tokenizer. This tokenizer is based on a probabilistic model and allows for smarter, more flexible tokenization at inference time. To handle the massive The Pile dataset, the authors adopted a divide-and-conquer parallel training strategy: they split the dataset into thousands of small chunks, trained an independent Unigram model on each chunk, and then merged these models hierarchically, ultimately obtaining a tokenizer with a vocabulary of about 130,000 ($2^{17}$) tokens. This larger vocabulary helps increase information density and reduce sequence length.
| BLOOM | /ours | NeoX | /ours | OPT | /ours | BloombergGPT | |
|---|---|---|---|---|---|---|---|
| FinPile (old version) | 451 | 110% | 460 | 112% | 456 | 111% | 412 |
| C4 | 166 | 121% | 170 | 123% | 170 | 123% | 138 |
| The Pile | 203 | 110% | 214 | 116% | 239 | 130% | 184 |
| Wikipedia | 21 | 88% | 23 | 99% | 24 | 103% | 24 |
| Total | 390 | 113% | 408 | 118% | 434 | 126% | 345 |
Table 3: Comparison of token counts (billions) after tokenizing each training dataset with different tokenizers. BloombergGPT’s tokenizer is more efficient in most cases (fewer tokens).
Model Architecture and Scale
Architecture
BloombergGPT is a decoder-only causal language model based on the BLOOM architecture. Its core structure is a 70-layer Transformer decoder module.
\[\bar{h}_{\ell} =h_{\ell-1}+\mathop{\mathrm{SA}}\nolimits(\mathop{\mathrm{LN}}\nolimits(h_{\ell-1}))\] \[h_{\ell} =\bar{h}_{\ell}+\mathop{\mathrm{FFN}}\nolimits(\mathop{\mathrm{LN}}\nolimits(\bar{h}_{\ell}))\]Key features include:
- ALiBi positional encoding: Positional encoding is implemented by adding biases in the self-attention module, enabling extrapolation to text longer than the training sequences.
- Additional layer normalization: An extra LN layer is added after the word embedding layer to improve training stability.
- Parameter sharing: The input word embeddings share weights with the final linear mapping layer before output.
Model Scale
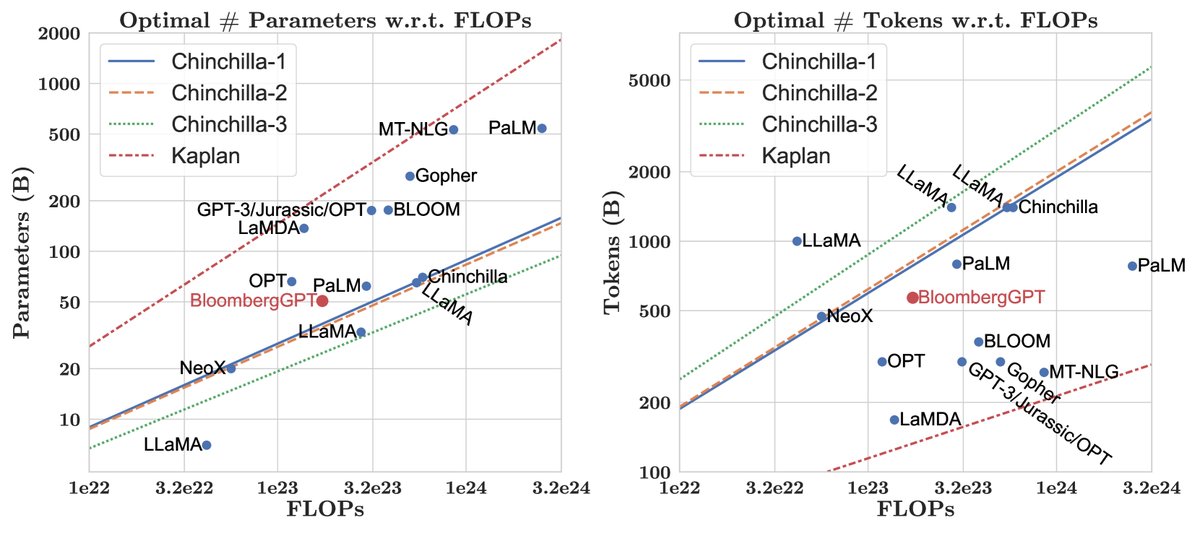
Figure 1: BloombergGPT’s position in terms of model parameters and data scale compared with existing large language models, based on the Chinchilla scaling laws.
The model’s 50 billion parameters were carefully chosen based on the Chinchilla scaling laws and the available compute budget (about 1.3 million A100 GPU hours). Given that the amount of financial-domain data (FinPile) is limited (about 363 billion tokens), and the authors did not want its proportion to fall below half of the total data, they could not keep increasing the data size to match a smaller “Chinchilla-optimal” model. In the end, choosing 50 billion parameters was the optimal use of compute resources under data constraints.
Model Shape
The model’s specific “shape” (number of layers, hidden dimension, etc.) was also optimized. According to the study by \(Levine et al. (2020)\), for a given number of layers \(L\), the optimal hidden dimension \(D\) can be estimated by the formula $D = \exp(5.039)\exp(0.0555 \cdot L)$. By searching among multiple \((L, D)\) combinations for the configuration closest to 50 billion parameters, and taking into account Tensor Core hardware acceleration requirements for dimensions (which must be multiples of 8), the following configuration was ultimately selected:
- Number of layers: 70
- Number of attention heads: 40
- Hidden dimension: 7680
- Total parameters: 50.6B
| Shape | |
| Number of layers | 70 |
| Number of attention heads | 40 |
| Vocabulary size | 131,072 |
| Hidden dimension | 7,680 |
| Total parameters | 50.6B |
| Hyperparameters | |
| Maximum learning rate | 6e-5 |
| Final learning rate | 6e-6 |
| Learning rate schedule | Cosine decay |
| Gradient clipping | 0.3 |
| Training | |
| Tokens | 569B |
| Hardware | $64\times 8$ A100 40GB |
| Throughput | 32.5 s/step |
| Average TFLOPs | 102 |
| Total FLOPs | 2.36e23 |
Table 4: Summary of BloombergGPT’s model hyperparameters and training configuration.
Training Process
Training was conducted on the AWS SageMaker platform, using 512 40GB A100 GPUs, and took about 53 days. 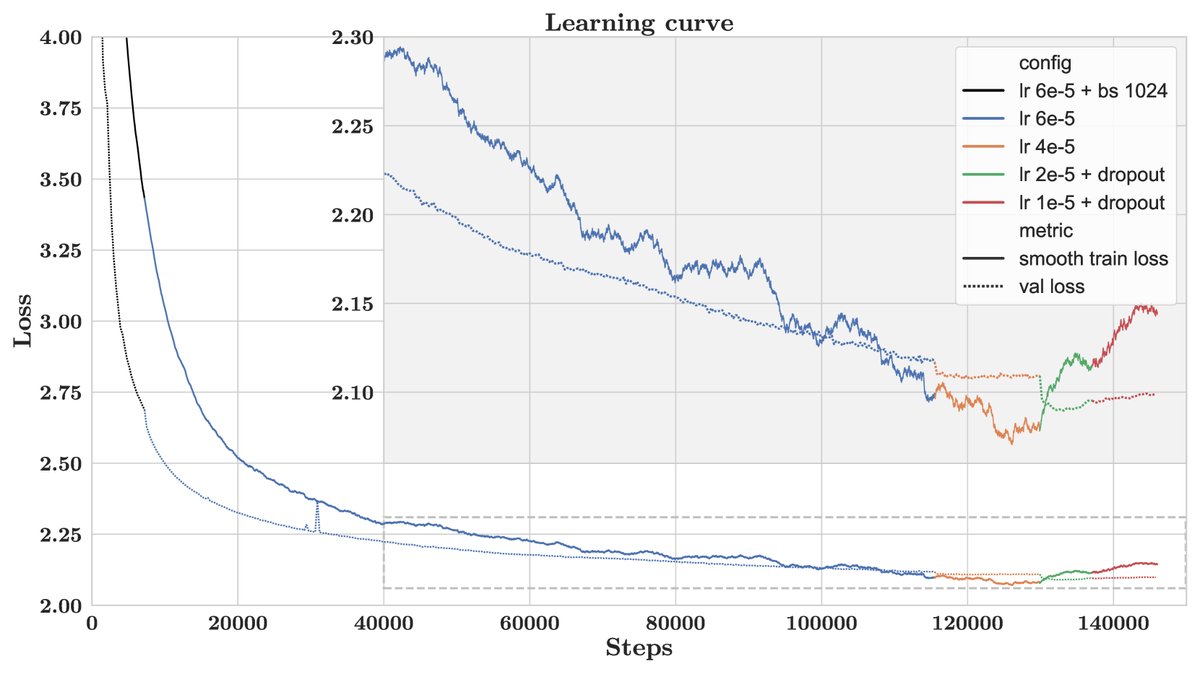
Figure 2: Training and validation loss curves. Different colors represent different hyperparameter configurations.
To train a large model within limited GPU memory, this paper adopted a series of parallelization and optimization techniques:
- ZeRO optimization (Stage 3): Shards model parameters, gradients, and optimizer states across 128 GPUs.
- Activation checkpointing: Reduces memory usage at the cost of recomputation.
- Mixed-precision training: Uses BF16 for forward and backward propagation, and FP32 to store and update parameters.
- Fused kernels: Combines multiple GPU operations to improve speed and avoid out-of-memory issues.
During training, when validation loss plateaued or increased, the team intervened by gradually lowering the learning rate and introducing dropout. Training was ultimately stopped when validation loss no longer improved significantly, and the best-performing checkpoint was selected as the final model.
Experimental Results
This paper conducted a comprehensive evaluation of BloombergGPT on two major categories of tasks: financial-domain tasks and general tasks.
- Evaluation subjects: Compared against three publicly available models with comparable scale and architecture: GPT-NeoX (20B), OPT (66B), and BLOOM (176B).
- Evaluation method: For a fair comparison, all tasks used standard zero-shot or few-shot prompting, without model-specific prompt engineering or advanced techniques such as Chain-of-Thought.
| Evaluation suite | Number of tasks | What does it measure? |
|---|---|---|
| Public financial tasks | 5 | Performance on public datasets in the financial domain |
| Bloomberg financial tasks | 12 | Internal core tasks such as NER and sentiment analysis |
| Big-bench Hard | 23 | Reasoning and general NLP tasks |
| Knowledge evaluation | 5 | The model’s closed-book information recall ability |
| Reading comprehension | 5 | The model’s open-book task performance |
| Linguistic tasks | 9 | NLP tasks not directly user-facing |
Table 5: Classification of the evaluation benchmarks.
Key findings: According to the paper’s abstract and introduction (the original evaluation results figures and tables are missing), BloombergGPT achieved the following key results:
- Outstanding performance on financial tasks: On public financial NLP benchmarks and proprietary tasks that reflect Bloomberg’s internal real-world application scenarios (such as sentiment analysis and named entity recognition), BloombergGPT performed significantly better than all comparable peer models. This directly validates the value of the large amount of high-quality financial data used in mixed training.
- Strong competitiveness on general tasks: Although half of the training data consisted of financial domain data, BloombergGPT’s performance on general LLM benchmarks (such as BIG-bench Hard and standard knowledge QA) was on par with or better than general-purpose models of similar or even larger scale. This shows that domain specialization did not come at the expense of general capabilities.
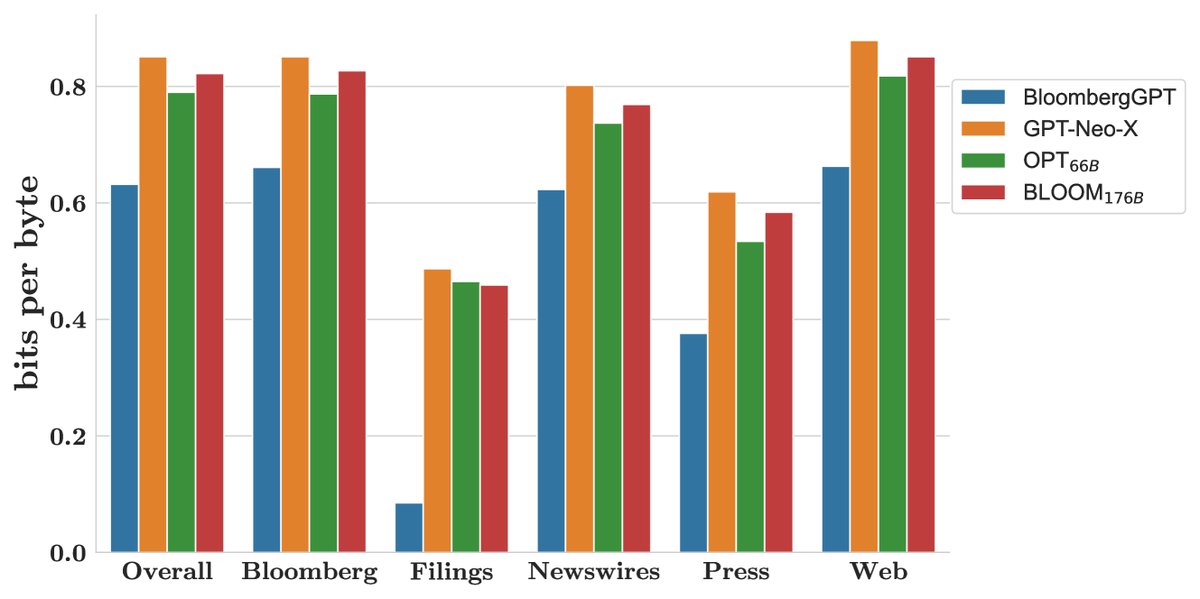
Figure 3: Bits per byte performance on multiple held-out test sets; lower is better.
Final conclusion: The experimental results in this paper strongly demonstrate the success of its proposed mixed-data training strategy. The success of BloombergGPT shows that by combining large-scale, high-quality domain-specific data with general data, it is possible to train a large language model that is both a “domain expert” and a “generalist.” This approach provides a highly valuable example and practical blueprint for building high-performance LLMs in other specialized domains in the future, such as law, medicine, and science.