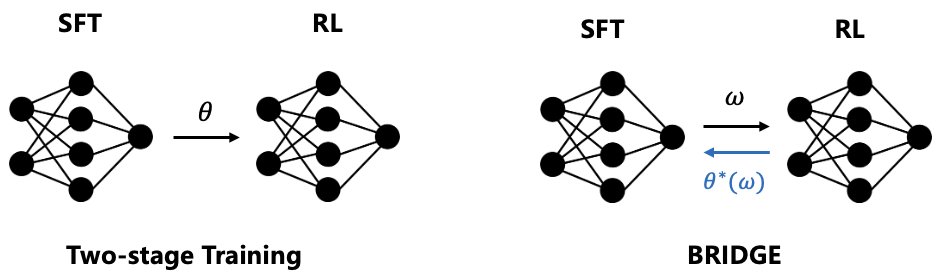
Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning
-
ArXiv URL: http://arxiv.org/abs/2509.06948v1
-
Authors: Xueting Han; Li Shen; Jing Bai; Kam-Fai Wong; Liang Chen
-
Publishing Institutions: Microsoft Research; Sun Yat-sen University; The Chinese University of Hong Kong
TL;DR
- This paper proposes a novel training framework called BRIDGE, which tightly integrates supervised fine-tuning (SFT) and reinforcement learning (RL) through bilevel optimization, surpassing the traditional two-stage training paradigm and more efficiently and effectively improving the reasoning ability of large language models.
Key Definitions
The core of this paper is a new training framework, whose key concepts are rooted in bilevel optimization theory:
- Bilevel Optimization Framework: This paper models the combination of SFT and RL as a leader-follower game. SFT serves as the upper-level problem (leader), and RL serves as the lower-level problem (follower). The upper-level SFT objective is conditioned on the optimal lower-level RL policy, enabling SFT to “meta-learn” how to guide the RL optimization process.
- Augmented Model Architecture: To enable bilevel optimization, the model parameters are decomposed into two parts: the base model parameters \($\theta\)$ and the Low-Rank Adaptation (LoRA) parameters \($w\)$. The lower-level RL optimizes the base parameters \($\theta\)$, while the upper-level SFT optimizes the LoRA parameters \($w\)$.
- Cooperative Gain: This is the core of the upper-level objective, defined as the performance advantage of joint SFT-RL training over RL training alone. By explicitly maximizing this gain in the upper-level optimization, BRIDGE ensures that SFT guidance is always beneficial to RL, thereby guaranteeing effective collaboration.
Related Work
At present, the mainstream methods for improving the reasoning ability of large language models include Supervised Fine-Tuning (SFT) and rule-based Reinforcement Learning (RL). SFT quickly learns reasoning patterns by imitating expert data, but has poor generalization; RL achieves higher performance through trial-and-error exploration, but training efficiency is low.
In practice, the most common approach is a “Cold-Start” two-stage training process: first warm up with SFT, then fine-tune with RL. The key bottleneck of this method is stage decoupling:
- Catastrophic forgetting: after switching to the RL stage, the model rapidly forgets the knowledge learned during the SFT stage.
- Inefficient exploration: the initial guidance from SFT is limited, and during the RL stage the model may still get stuck in local optima and fail to solve difficult problems.
This paper aims to address the above issues by designing a unified training framework that allows SFT and RL to truly work together, achieving a \(1+1>2\) effect and ensuring performance superior to using RL alone.
Method
This paper proposes BRIDGE, a cooperative meta-learning framework based on bilevel optimization, to achieve deep integration of SFT and RL.
Method Architecture
BRIDGE adopts an augmented model architecture that splits the model parameters into two parts:
- Base model parameters \($\theta\)$: optimized by the lower-level RL objective.
- LoRA module parameters \($w\)$: optimized by the upper-level SFT objective.
This parameter separation is the key to bilevel optimization, allowing the two objectives to adapt together during training rather than overwriting each other.
Bilevel Optimization Formulation
The framework is formalized as a bilevel optimization problem, with SFT as the upper-level problem and RL as the lower-level problem:
\[\begin{align*} \max_{w} \quad & J_{\mathrm{SFT}}(w, \theta^*(w)) \\ \text{s.t.} \quad & \theta^*(w) = \arg\max_{\theta} J_{\mathrm{RL}}(\theta, w) \end{align*}\]- Lower-level problem (Follower): given the LoRA parameters \($w\)$, solve for the optimal base model parameters \($\theta^\*(w)\)$ by maximizing the RL objective \($J\_{\mathrm{RL}}\)$.
- Upper-level problem (Leader): find the optimal LoRA parameters \($w\)$ such that the model \($\theta^\*(w)\)$ after lower-level RL optimization performs best on the SFT task \($J\_{\mathrm{SFT}}\)$.
This structure enables bidirectional information flow: SFT (upper level) can “anticipate” the optimization outcome of RL (lower level), thereby providing more targeted guidance.
Learning Algorithm and Innovations
Because directly solving the bilevel optimization problem involves complex second-order derivatives and is computationally expensive, this paper adopts a penalty-based first-order relaxation method for approximate solution.
1. Innovation 1: Lower-level update - curriculum-weighted gradient fusion The update rule for the base parameters \($\theta\)$ is a weighted sum of the SFT and RL gradients:
\[\theta^{k+1} = \theta^{k} + \alpha\left[(1-\lambda)\nabla_{\theta}J_{\mathrm{SFT}}(\theta,w) + \lambda\nabla_{\theta}J_{\mathrm{RL}}(\theta,w)\right]\]where \($\lambda\)$ is a weight that changes dynamically from 0 to 1. In the early stage of training, the model mainly learns by imitating SFT data; as the model becomes more capable, the weight of RL gradually increases, allowing the model to learn more through exploration. This design forms an adaptive curriculum learning mechanism.
2. Innovation 2: Upper-level update - explicit maximization of cooperative gain The update of the LoRA parameters \($w\)$ aims to maximize a composite objective, whose core is cooperative gain:
\[\underbrace{J_{\mathrm{RL}}(\theta,w) - J_{\mathrm{RL}}(\hat{\theta},w)}_{\text{cooperative gain}}\]where \($\theta\)$ is the parameter jointly optimized by SFT and RL, while \($\hat{\theta}\)$ is the parameter optimized only by RL. This gain term measures the performance improvement brought by “joint SFT-RL training” over “pure RL training.” By maximizing this gain, the upper-level SFT learns how to provide the most helpful guidance for RL, thereby theoretically ensuring that the collaboration outperforms RL alone.
Experimental Results
The paper conducted extensive experiments on three large language models (Qwen2.5-3B, Llama-3.2-3B, Qwen2-8B) and five mathematical reasoning benchmarks.
Key Findings
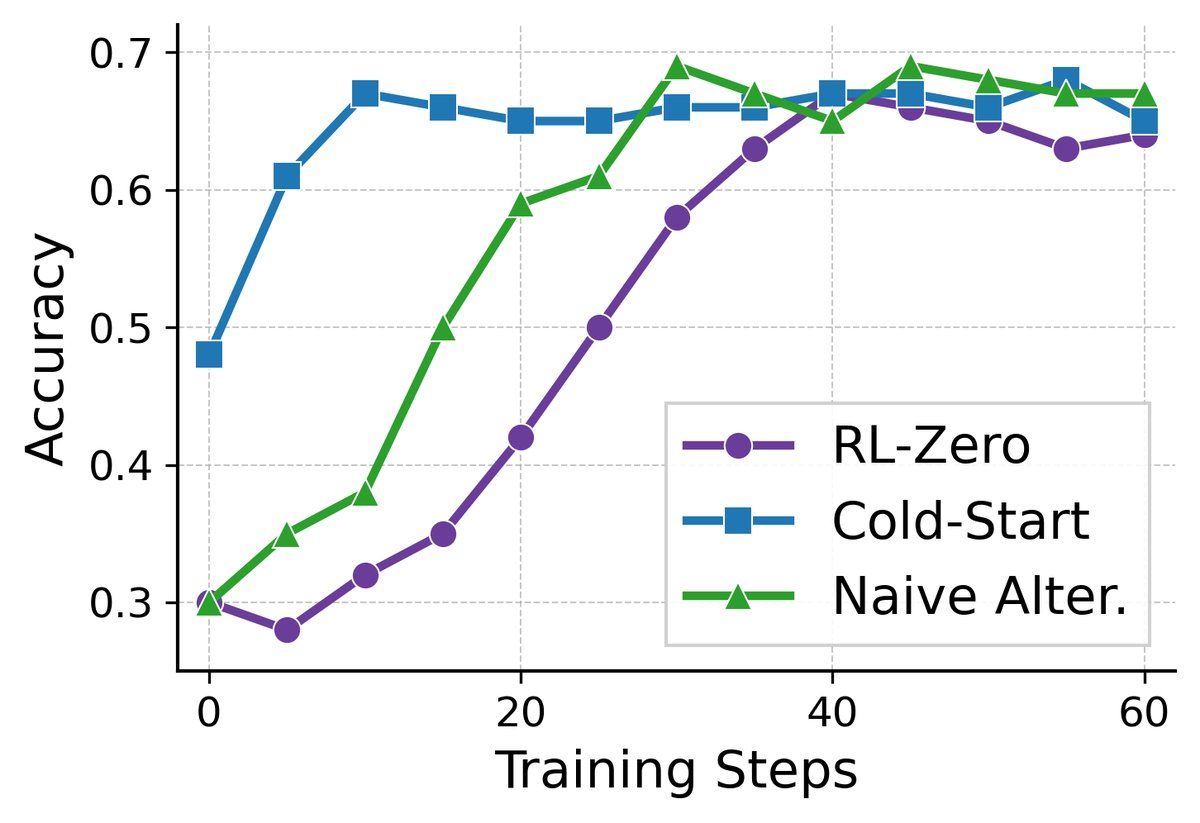
- Comprehensive performance gains: Across all models and datasets, BRIDGE consistently and significantly outperforms all baseline methods, including SFT, RL-zero (RL from scratch), Cold-start (two-stage), and a simple alternating-training baseline. For example, on Qwen2.5-3B, compared with Cold-start, BRIDGE achieved an average performance improvement of 11.8% on multiple challenging datasets.
| Method | MATH500 | Minerva Math | OlympiadBench | AIME24 | AMC23 | Average |
|---|---|---|---|---|---|---|
| Base | 32.4 | 11.8 | 7.9 | 0.0 | 20.0 | 14.4 |
| SFT | 53.4 | 18.8 | 21.5 | 3.3 | 42.5 | 27.9 |
| RL-zero | 64.4 | 26.5 | 27.0 | 3.3 | 40.0 | 32.2 |
| Cold-start | 66.0 | 24.3 | 26.8 | 9.0 | 35.0 | 32.2 |
| Naive Alter. | 65.2 | 25.3 | 27.1 | 6.7 | 42.5 | 33.4 (+3.7) |
| BRIDGE | 66.2 | 23.9 | 28.9 | 13.3 | 47.5 | 36.0 (+11.8) |
-
Stronger generalization: BRIDGE shows particularly superior generalization on more difficult competition-level mathematical reasoning tasks (such as OlympiadBench and AIME24), while baseline methods show limited improvement or even degradation on these tasks.
-
Higher training efficiency: Training dynamics analysis shows that the Cold-start method exhibits a “decrease first, then increase” performance pattern in the early stage of RL, indicating that the model is forgetting SFT knowledge, which leads to low efficiency. In contrast, BRIDGE achieves rapid and stable reward growth through continuous SFT guidance, avoiding catastrophic forgetting.
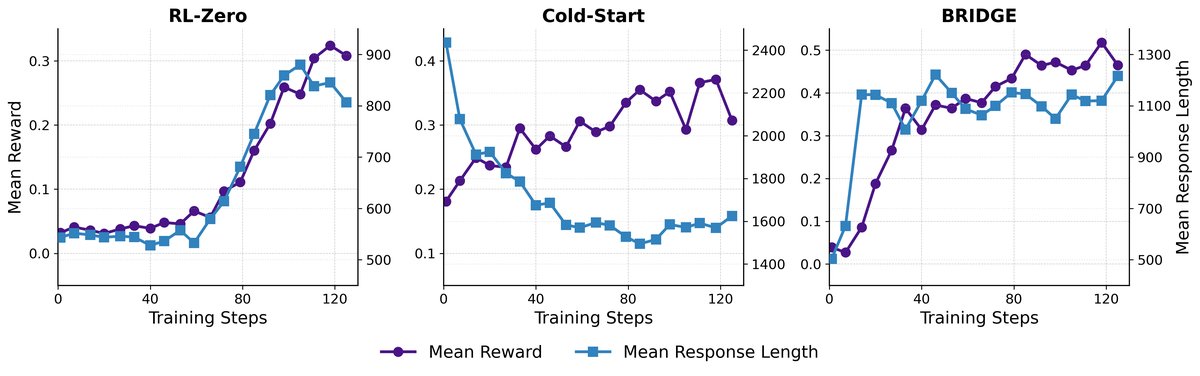
- Better cost-effectiveness: Compared with the Cold-start method, which requires nearly twice the training time, BRIDGE saves 14%-44% of training time while achieving higher performance, demonstrating its cost advantage in practical deployment.
| Metric | Qwen 2.5-3B | Qwen 3-8B-Base | ||||
|---|---|---|---|---|---|---|
| RL-zero | Cold-start | BRIDGE | RL-zero | Cold-start | BRIDGE | |
| Time (hours) | 6.1 | 12.3 | 6.9 | 38.5 | 39.1 | 33.5 |
| VRAM (GB) | 52.2 | 45.9 | 59.3 | 50.7 | 60.8 | 67.4 |
| Accuracy (%) | 32.2 | 32.2 | 36.4 | 42.9 | 45.5 | 49.9 |
Summary
The experimental results strongly demonstrate the effectiveness of the BRIDGE framework. By modeling the combination of SFT and RL as a bilevel optimization problem, BRIDGE not only addresses the inherent shortcomings of traditional two-stage methods, but also achieves a new balance between performance and efficiency, providing a superior paradigm for training powerful reasoning models.