Beyond Turn Limits: Training Deep Search Agents with Dynamic Context Window
-
ArXiv URL: http://arxiv.org/abs/2510.08276v1
-
Authors: Qiaoyu Tang; Yaojie Lu; Xianpei Han; Zhenru Zhang; Le Yu; Shixuan Liu; Hao Xiang; Hongyu Lin; Bowen Yu; Pengbo Wang; and 13 others
-
Publishing Organization: Alibaba Group; Chinese Academy of Sciences; University of Chinese Academy of Sciences
TL;DR
This paper proposes the DeepMiner framework, which significantly improves a large language model’s reasoning and execution capabilities as a deep-search intelligent agent in multi-turn long-horizon interactions by constructing highly challenging training tasks and designing a dynamic context window strategy.
Key Definitions
- DeepMiner: A novel training framework proposed in this paper, aimed at stimulating and training the deep reasoning ability of multi-turn long-horizon interaction intelligent agents through (1) generating highly challenging training tasks and (2) introducing a dynamic context window management mechanism.
- Reverse Construction Method: A method designed in this paper for generating complex but verifiable QA pairs. Starting from real web information sources, it ensures the challenge and reliability of the training data through entity-driven information collection, question generation across multiple information sources, and strict multi-stage filtering.
- Dynamic Context Management / Sliding Window Strategy: A strategy designed to address context length limitations in long-horizon interactions. Through a sliding window, it selectively replaces older tool call outputs with placeholders while fully preserving the agent’s own reasoning traces, thereby supporting more interaction turns within a limited context.
Related Work
At present, reinforcement learning with verifiable rewards (RLVR) has achieved significant success in single-turn reasoning tasks such as math and programming, enabling models to exhibit complex cognitive behaviors like self-checking and backtracking. However, when extending this capability to multi-turn long-horizon tasks that require dozens or even hundreds of interaction turns, such as deep research, existing open-source methods have encountered two major bottlenecks:
- Insufficient training data difficulty: Existing QA datasets, such as HotpotQA, are mostly based on structured Wikipedia content, with relatively simple task patterns. Models can easily complete them through shallow information retrieval, making it impossible to stimulate advanced cognitive abilities such as deep exploration, verification, and strategic planning.
- Context length limitations: In multi-turn interactions, the large amount of text returned by tools quickly fills up the model’s context window (for example, a 32k context can only support about 10-15 interaction turns). The current mainstream solution relies on external models to summarize tool outputs, but this not only loses key fine-grained information, it also increases system complexity and cannot be optimized end-to-end by the reinforcement learning process.
This paper aims to solve the above two problems, namely how to train a search intelligent agent capable of deep reasoning in long-horizon interactions by constructing truly challenging training data and designing an efficient context management strategy.
Method
This paper proposes the DeepMiner framework, whose core consists of two parts: a reverse construction method for complex questions and a reinforcement learning strategy with a dynamic context window.
Complex Question Construction
To generate training tasks that can stimulate the model’s deep reasoning ability, this paper designs a three-stage reverse construction process:
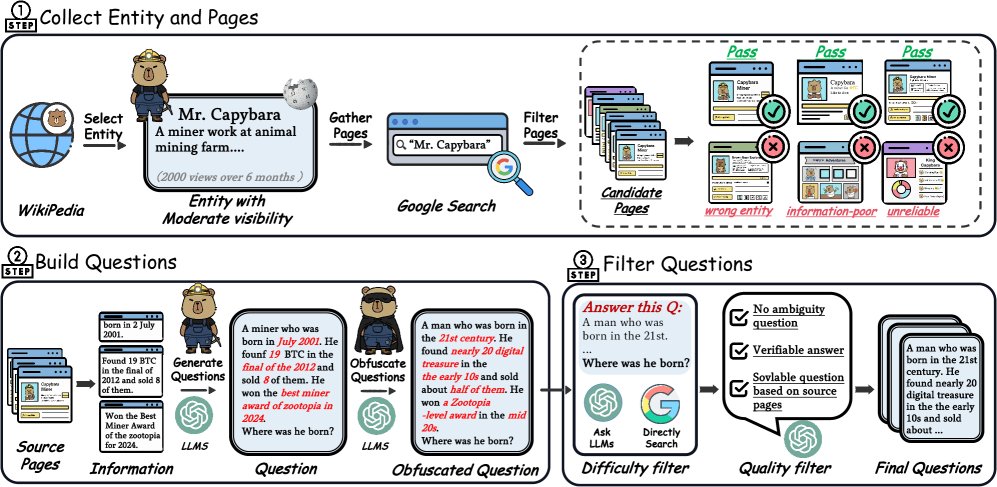
- Entity-driven information collection: First, moderately well-known entities are selected from Wikipedia to ensure the information is rich enough while not yet solidified into parametric knowledge by the model. Then, web pages related to the entity are collected through a search engine and filtered in three rounds: verifying the correspondence between the web page and the entity, evaluating whether the information is complementary, and filtering out unreliable sources.
- Question generation: Using a large language model, questions are generated based on multiple filtered real web pages (at least 4, and Wikipedia is deliberately excluded). This process forces the model to answer by integrating multiple scattered information sources. To further increase difficulty, the generated questions are also subjected to a second “obfuscation” step, such as replacing specific details with more general descriptions, forcing the intelligent agent to perform more complex reasoning and information integration when solving the problem.
- Multi-stage filtering: The generated QA pairs are subjected to strict difficulty and quality filtering. Difficulty filtering ensures that the questions cannot be solved directly through a simple search engine query or zero-shot prompting of the model. Quality filtering excludes questions with ambiguous wording, unclear answers, or answers that cannot be logically derived from the given evidence, ensuring the reliability of the training signal.
Reinforcement Learning with a Dynamic Context Window
Dynamic Context Management Strategy
Analysis of failure cases of existing models on complex tasks shows that context exhaustion is the main reason interactions terminate early. Typically, the content returned by tools is much longer than the agent’s reasoning process, causing the context to fill up rapidly.
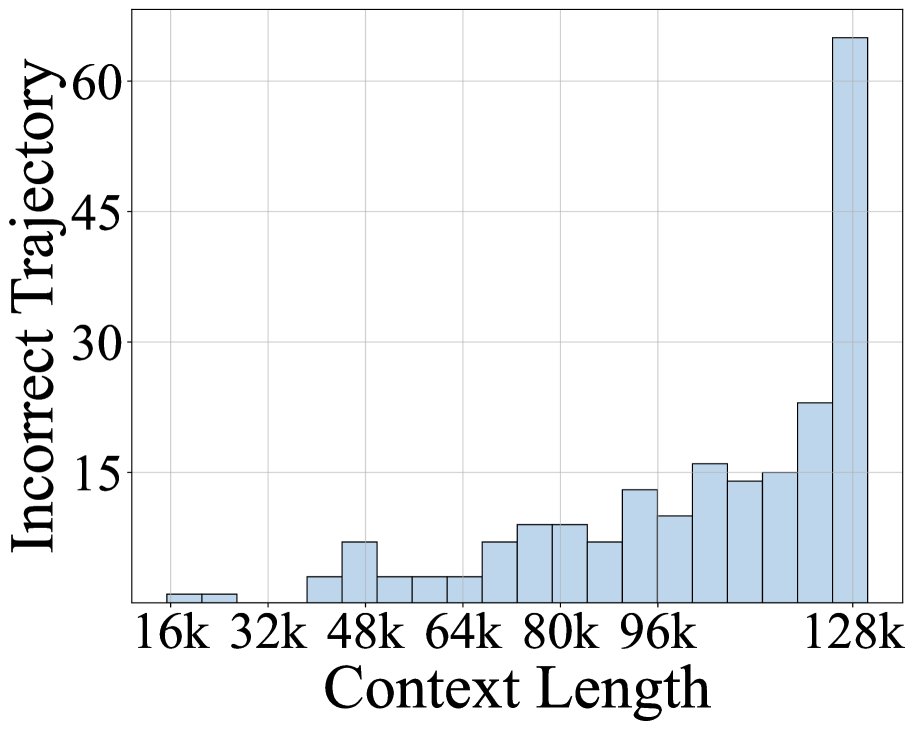
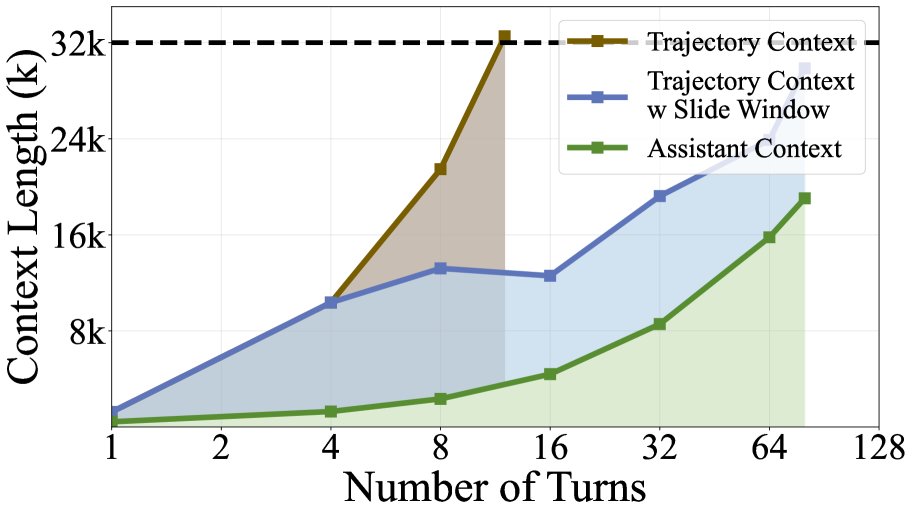
Based on this, this paper designs a dynamic context management strategy centered on a Sliding Window Mechanism:
- Innovation: The core idea of this mechanism is “drop tools, keep thinking.” In an interaction trajectory $\tau={q, a_1, t_1, \ldots, a_T}$ ($a_i$ denotes the agent’s reasoning, and $t_i$ denotes tool output), when the number of tool outputs reaches the window size $\mathcal{W}$, the system replaces the earliest tool outputs $t_i$ with a placeholder (such as \([Previous tool output skipped. Re-run tool if needed.]\)), while fully preserving all of the agent’s reasoning processes $a_i$.
- Advantages: This design preserves the complete reasoning chain that guides strategic planning, while greatly saving context space by compressing older tool outputs that have less impact on the current decision. This allows the model to support nearly 100 interaction turns even within a 32k context. At the same time, it avoids the information loss and optimization blind spots introduced by external summarization models.
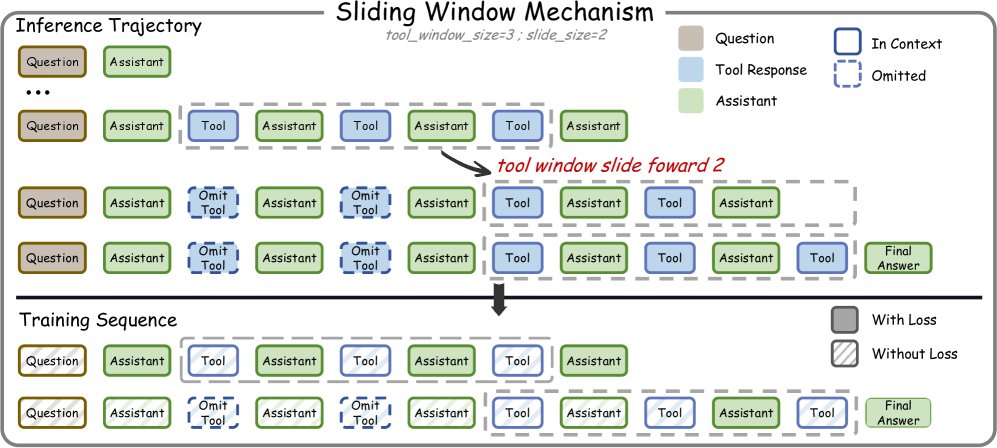
Training-Test Consistency
To adapt the model to dynamically changing context during inference, this paper decomposes each long trajectory during training. A trajectory containing $T$ tool calls is split into multiple training sequences. Each sequence simulates the state of the sliding window at different stages, where some early tool outputs are replaced by placeholders. A masking mechanism ensures that each agent reasoning output is trained only once across all sequences, thereby achieving consistency between training and test behavior.
\[\mathcal{M}^{(k)}_{i}=\begin{cases}0&\text{if }i<\mathcal{W}+(k-2)\cdot\mathcal{S}+2\\ 1&\text{otherwise}\end{cases}\]Training Process
- Cold Start: First, cold start is performed through supervised fine-tuning (SFT). A powerful language model is used to generate high-quality tool-call trajectories (also applying the sliding window mechanism to support long-horizon generation), and the successful cases are selected for initial model training so that it acquires basic tool-use and long-horizon reasoning capabilities.
-
Reinforcement Learning Training: GRPO (Group Relative Policy Optimization) is used for reinforcement learning. During training, $G$ complete interaction trajectories are generated for each question. The reward is binary (1 for a correct answer, 0 for an incorrect one). The trajectory-level advantage is computed as follows:
\[\hat{A}_i = \frac{1}{ \mid \mathcal{G} \mid } \sum_{j \in \mathcal{G}} (\mathbb{I}[r_i > r_j] - \mathbb{I}[r_i < r_j])\]
The core modification of this paper lies in advantage propagation: the computed trajectory-level advantage $\hat{A}_i$ is propagated to all training sequences decomposed from that trajectory. This ensures that even when training on dynamically changing context sequences, the policy learning signal remains consistent and effective.
Experimental Results
Main Results
This paper trained DeepMiner-32B based on the Qwen3-32B model and evaluated it on multiple deep research benchmarks.
| Model | BrowseComp-en | BrowseComp-zh | XBench-DeepSearch | GAIA |
|---|---|---|---|---|
| Open-source Agents | ||||
| Webshaper-34B | 13.9 | 15.6 | 17.5 | 18.0 |
| ASearcher-7B | 12.1 | 14.2 | 16.5 | 16.8 |
| WebDancer-8B | 12.8 | - | 19.3 | - |
| WebSailor-7B | 11.2 | - | 16.2 | 14.1 |
| General Models | ||||
| DeepSeek-V3.1-671B | 31.7 | - | 34.0 | - |
| This Work | ||||
| DeepMiner-32B (SFT) | 21.2 | 23.3 | 29.5 | 27.6 |
| DeepMiner-32B (RL) | 33.5 | 35.4 | 38.5 | 31.9 |
- Significant performance gains: DeepMiner-32B significantly outperforms all previous open-source agents across all benchmarks. In particular, on the most challenging BrowseComp-en, its 33.5% accuracy is nearly 20 percentage points higher than the previous best open-source method, and even surpasses DeepSeek-V3.1-671B, which is 20 times larger.
- The RL stage is highly effective: From SFT to RL, the model achieves substantial improvements on all benchmarks (for example, a 12.3-point gain on BrowseComp-en), demonstrating that the reinforcement learning framework in this work can effectively enhance the model’s deep reasoning and strategic planning capabilities.
Efficiency and Analysis
Context management efficiency We compared the efficiency of three context management strategies. The sliding-window method in this work, using only a 32k context, outperforms other methods that use a 128k context, while supporting nearly 100 interaction turns, far exceeding the others.
| Strategy | Context Efficiency | Auxiliary Model | Information Loss | End-to-end Optimization | Max Turns (32k) | Performance (BrowseComp) |
|---|---|---|---|---|---|---|
| Vanilla | Low | No | None | Yes | ~15 | 29.2% (128k) |
| External Summary | Medium | Yes | High | No | ~30 | 31.7% (128k) |
| DeepMiner (Sliding Window) | High | No | Low | Yes | ~100 | 33.3% (32k) |
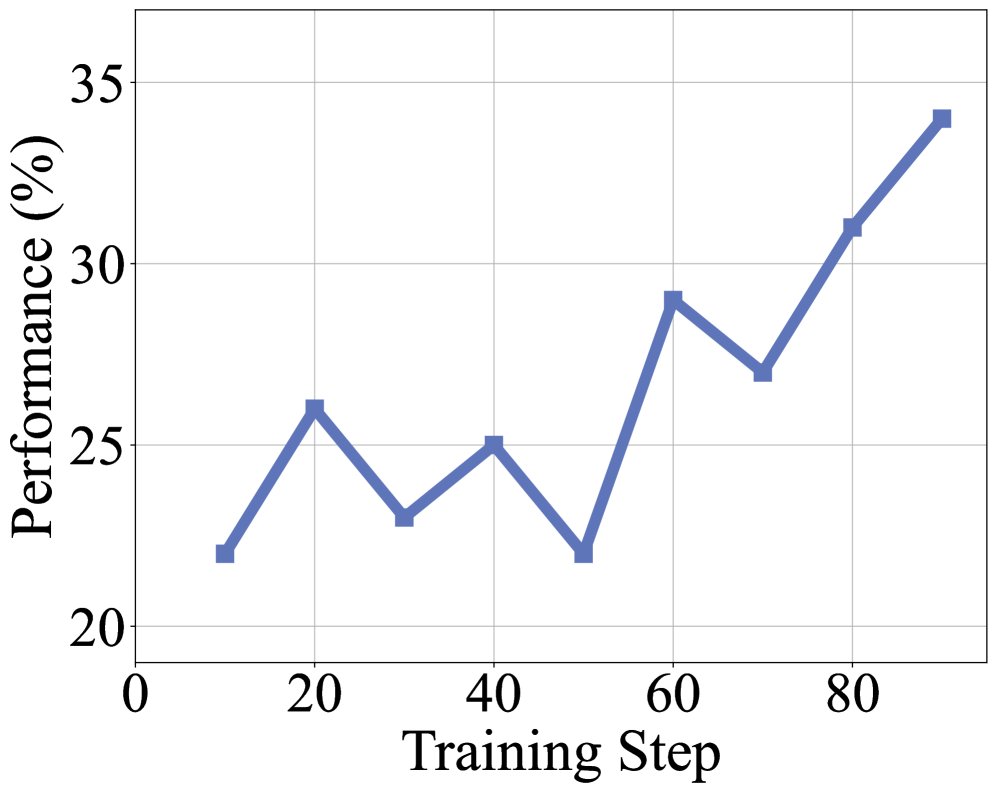
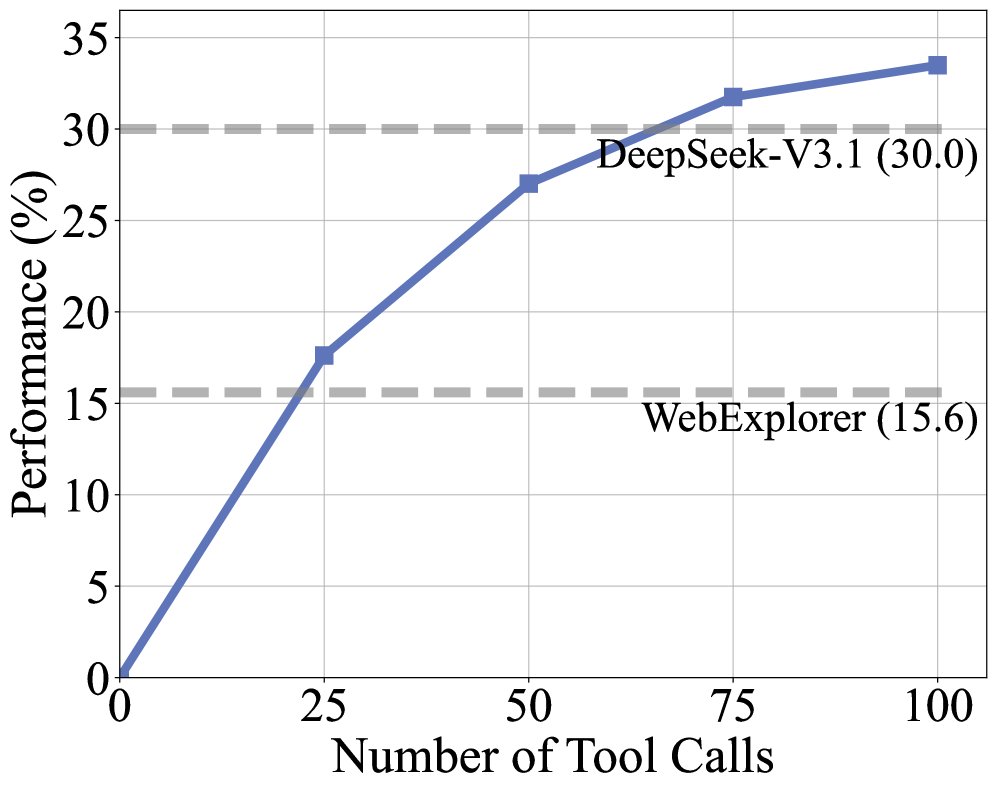
Training dynamics and context scaling During training, both rewards and trajectory length steadily increase, indicating that the model is continuously learning to solve the complex tasks constructed in this work. Performance improves as the tool-call budget increases, surpassing the strong baseline model after 60 calls. Moreover, even with the limited 32k context, DeepMiner achieves near-saturated performance, demonstrating the efficiency of its context management strategy.
Data efficiency To validate the effectiveness of the data construction method in this work, we compared SFT training using our data versus the commonly used HotpotQA dataset.
| Training Data | BrowseComp Performance |
|---|---|
| HotpotQA-SFT | 15.6% |
| DeepMiner-SFT | 21.2% |
The results show that the model trained on DeepMiner data far outperforms the model trained on HotpotQA, proving that the high-difficulty data constructed in this work is both necessary and effective for stimulating the cognitive capabilities of complex web agents.
Final conclusion: This work demonstrates that combining high-quality, high-difficulty training data with an efficient dynamic context management strategy can effectively unlock the deep reasoning potential of large language models in multi-turn long-horizon interactions, making it a key path toward developing the next generation of deep research agents.