Better World Models Can Lead to Better Post-Training Performance
New Breakthrough in AI Rubik’s Cube Solving: Pretrain a “World Model,” and Reinforcement Learning Performance Improves by 40%!

Large language models, after a series of “training” stages such as pretraining, fine-tuning, and reinforcement learning, demonstrate astonishing capabilities. But have we ever wondered how these training stages shape the model’s internal “worldview”? Could a clearer, more accurate internal world model further empower AI in subsequent learning?
ArXiv URL:http://arxiv.org/abs/2512.03400v1
Recently, researchers from top universities such as Harvard and Princeton revealed the answer through an ingenious 2x2 Rubik’s Cube experiment. The study found that explicitly teaching the model the “rules of the world” first can significantly improve the effectiveness of later reinforcement learning, with performance on the hardest tasks increasing by as much as 40%!
Experimental Setup: An Ingenious Rubik’s Cube World
To study this question precisely, the researchers chose a perfect “sandbox” that requires planning and reasoning—the 2x2 Rubik’s Cube.
The task is simple: give a Transformer a sequence of scrambled cube states and have it generate a sequence of “optimal” steps to solve the cube.
The key here is that during training, the model only sees the initial state and the final solution steps, but does not see the intermediate cube states after each move.
This means the model must internally “imagine” what the cube looks like and understand how each rotation (action) changes the cube’s state (world). This internal “imagination” process is what is called a world model.
How Do We Build a Better “World Model”?
The researchers designed three different training strategies to compare the effects of implicit and explicit world-model learning:
-
Standard Fine-Tuning: This is the most common approach. The model is directly trained to learn the correct solution from a scrambled cube, relying entirely on predicting the next token to implicitly grasp the cube’s rules.
-
State-Prediction Pretraining: A two-step approach.
-
First, instead of teaching the model to solve the cube, it is shown random rotation steps and asked to accurately predict the exact state of the cube after each step (the colors of the 24 stickers). This is equivalent to explicitly giving the model a “physics lesson,” so it first learns the operating rules of the cube world.
-
Second, the model is then fine-tuned using the standard method to learn how to solve the cube.
- Joint Training: A compromise. While training the model to solve the cube, an auxiliary task is added that requires it to also predict the cube’s state. This is like learning to solve the problem while reinforcing the physical rules at the same time.
Probing and Intervention: Going Deep into AI’s “Brain”
How clear is the model’s internal world model, really? The researchers used two clever methods to “peek into” and “test” the model’s internal representations.
Linear Probing
This is like attaching an “EEG monitor” to the model. The researchers trained a simple linear classifier (a probe) to try to decode the exact cube state from the model’s internal hidden state $h$.
The higher the decoding accuracy, the clearer and more structured the model’s internal representation of the cube state.
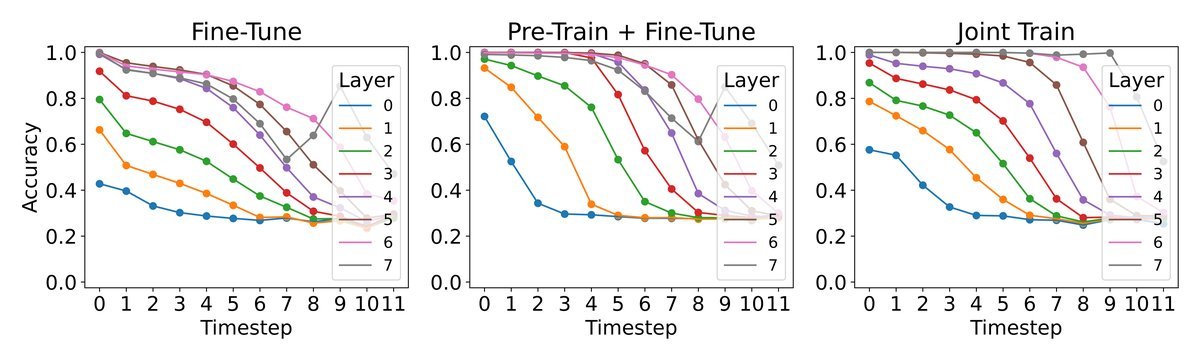
As shown in the figure above, models that underwent “world model pretraining” (Pre-Train) or “joint training” (Joint-Train) achieved significantly higher probe accuracy than the standard fine-tuning model. This proves that explicit learning does indeed build a higher-quality internal world representation.
Causal Intervention
Being able to “read” it is not enough—does this internal representation really guide the model’s decisions?
The researchers performed a bolder “brain surgery”: before the model generated the next move, they forcibly intervened in its internal hidden state and “tampered” with the cube state $S$ in its mind, changing it to another state $T$.
If the model truly relies on this internal representation, then its next decision should shift from “a reasonable step to solve cube S” to “a reasonable step to solve cube T.”
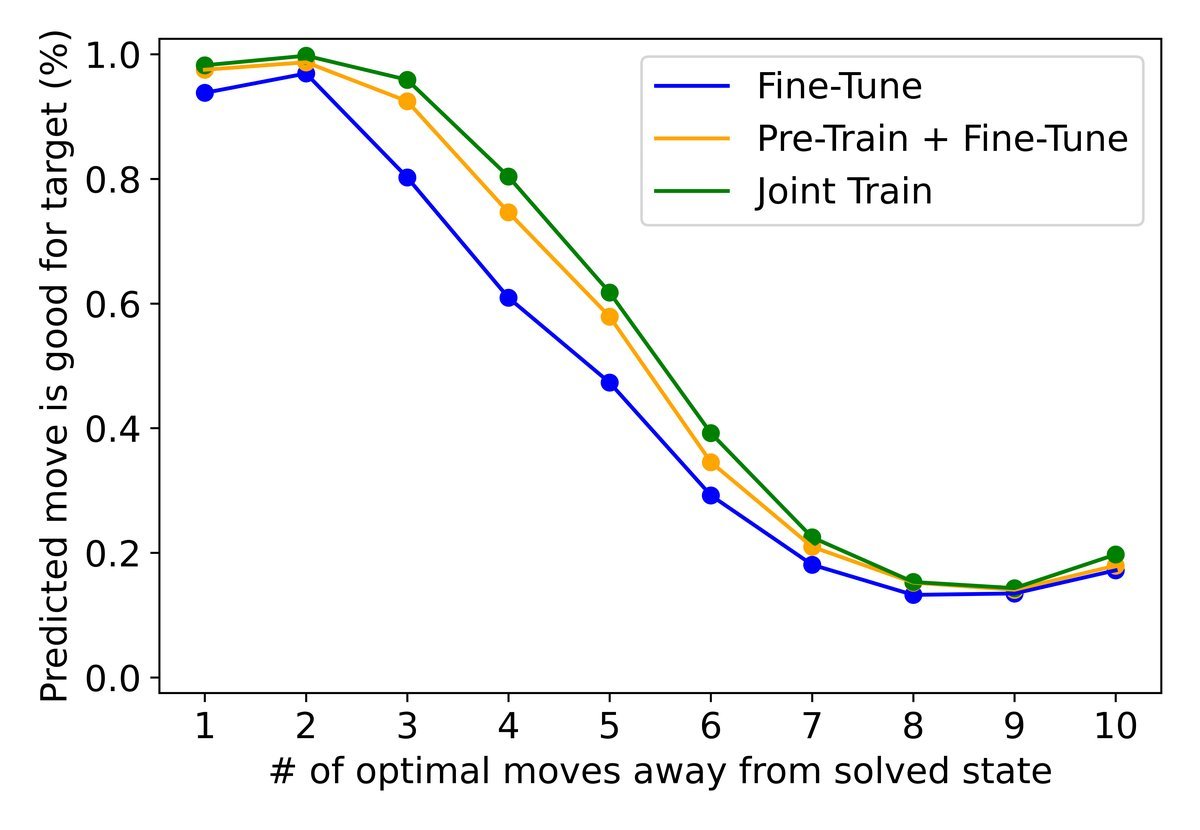
The experimental results (as shown in the upper-left figure) indicate that models trained with an explicit world model had a higher intervention success rate. This shows that their decisions rely more on the clearly constructed internal world model rather than on vague statistical associations.
A Better World Model, Stronger Downstream Performance
Now we come to the most critical question: how much does a clearer world model help the model’s final performance?
The research team added a post-training stage with reinforcement learning (Post-training with GRPO) to all three training strategies above. GRPO further optimizes the model’s policy through multiple rollouts and rewards (reward = 1 for solving the cube, otherwise 0).
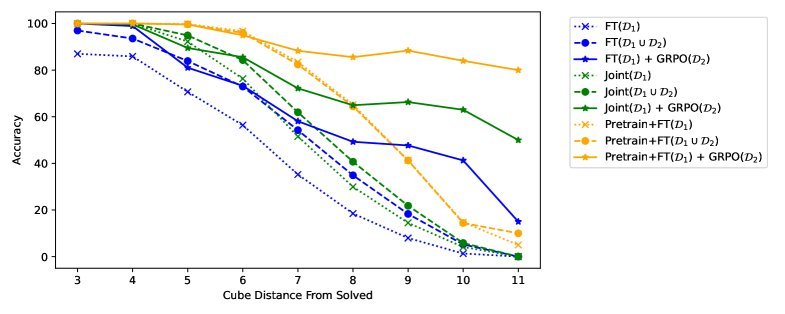
The figure above shows the final showdown and reveals an astonishing finding:
-
The solid lines represent performance after fine-tuning only, while the dashed lines represent performance after reinforcement learning (GRPO).
-
At every stage, models trained with an explicit world model (blue and green lines) outperform the standard method (red line) across the board.
-
The biggest highlight is this: models with a better world model (blue and green dashed lines) gain far more from reinforcement learning. Especially on the hardest cubes that require 11 moves to solve, the policy with a pre-trained world model improves from about 50% accuracy to 70% compared with the standard policy, achieving a 40% relative performance gain!
This shows that a solid, clear world model provides an excellent starting point for subsequent reinforcement learning, enabling the model to explore and learn more efficiently and ultimately reach higher performance.
Conclusion
Through a simple yet elegant Rubik’s Cube experiment, this study clearly demonstrates the key role of the “world model” in the formation of AI capabilities.
It tells us that rather than letting a model “grow wildly” on massive amounts of data, it is better to first teach it the “basic laws” of the world. This paradigm of “understand the rules first, then learn the strategy” not only builds more robust and interpretable internal representations, but also greatly unleashes the potential of downstream training methods such as reinforcement learning.
Although the experiment is currently limited to the Rubik’s Cube task, the principle it reveals—a better world model can lead to better downstream training performance—undoubtedly points to a promising path for building more powerful and reliable AI systems in the future.