BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data
-
ArXiv URL: http://arxiv.org/abs/2510.10159v1
-
Authors: Ziyin Zhang; Yurii Paniv; Negar Foroutan; Nikitas Theodoropoulos; Pouya Sadeghi; Leshem Choshen; Akari Haga; Linyang He; Faiz Ghifari Haznitrama; Bastian Bunzeck; and 20 others
-
Affiliations: Aix Marseille University; Bielefeld University; City University of Hong Kong; Columbia University; EPFL; Independent Researcher; KAIST; MIT; MIT-IBM Watson AI Lab; Nara Institute of Science and Technology; Shanghai Jiao Tong University; SomosNLP; Ukrainian Catholic University; University of California San Diego; University of Cambridge; University of Cape Town; University of Colorado Boulder; University of Groningen; University of Tehran; University of Texas at Austin; University of the Basque Country
TL;DR
This paper introduces BabyBabelLM, a multilingual benchmark covering 45 languages and simulating the human language acquisition environment, aiming to advance cross-lingual research on language models in terms of data efficiency and cognitive plausibility.
Key Definitions
This paper introduces or adopts the following key concepts:
- BabyBabelLM: The core contribution of this paper, a multilingual benchmark that includes: (1) carefully curated, developmentally plausible training datasets across 45 languages; (2) an evaluation suite covering both formal competence and functional competence; (3) monolingual, bilingual, and multilingual baseline models trained on these data.
- Developmental Plausibility: The core guiding principle for dataset construction, meaning that pretraining data should as closely as possible simulate the language input children actually encounter during language acquisition. This includes prioritizing child-directed speech (CDS), educational materials, children’s books, and the deliberate exclusion of synthetic data.
- Language Tiers: To enable fair comparison across languages with uneven data resources, the paper divides the 45 languages into three tiers based on dataset size (cross-lingually calibrated token counts): Tier 1 (about 100 million equivalent English words), Tier 2 (10 million), and Tier 3 (1 million).
- Formal Competence and Functional Competence: The two dimensions of the evaluation suite. Formal competence refers to mastery of language rules and patterns (e.g., grammar); functional competence refers to the ability to understand and use language in real-world contexts (e.g., reasoning, common sense).
Related Work
The mainstream trend in current language model research is to pursue scale, which has led to two key problems: first, data efficiency is neglected, making model training expensive; second, the gap between how models learn and how humans acquire language is growing wider, as humans can master their native language with fewer than 100 million words, whereas large models require trillions of words.
In response, research such as the BabyLM Challenge has begun to focus on data efficiency and cognitive plausibility, but most of this work is limited to English. Although there have been scattered studies for languages such as French, German, and Japanese, they lack unified, comparable standards and datasets.
The core problem this paper aims to address is: there is currently no standardized, multilingual, developmentally plausible training and evaluation framework. By building BabyBabelLM, this paper provides key infrastructure for studying how data-efficient language models that learn more like humans can acquire language across different types of languages.
Method
The core contribution of this paper is the creation of the BabyBabelLM benchmark, whose construction process and components are as follows.
Dataset Construction
Innovations
The innovation of this method lies in its systematic, principled, and scalable construction of a multilingual, developmentally plausible dataset. Unlike previous fragmented studies, it:
- Adheres to the principle of developmental plausibility: It strictly filters data sources, prioritizing child-directed speech (CDS), educational materials, and children’s books, while explicitly excluding synthetic data that may distort language distributions (such as TinyStories), in order to more faithfully simulate children’s language environment.
- Achieves cross-lingual comparability: By introducing “Language Tiers” and a language-adjusted byte estimation method, it addresses differences in data availability and text encoding efficiency across languages, making cross-lingual model performance comparisons more fair.
- Adopts a community-driven model: It assigns researchers familiar with each language as leads and establishes an open-source contribution workflow, designing BabyBabelLM as a “living resource” that can continuously absorb new data and languages, ensuring its long-term value and quality.
Dataset Composition
- Data Categories: To simulate the diverse language input children receive, the dataset includes the following types:
- Transcription: Mainly from the CHILDES database, consisting of child-directed speech (CDS), characterized by short sentences, simple structure, and high repetition. It also includes some adult-to-adult conversations.
- Education: Materials from textbooks and exams, providing more direct instructional content.
- Books, Wiki, News: Children’s books, children’s Wikipedia, and similar sources, providing longer, more complex sentences and richer vocabulary.
- Subtitles: Subtitles from films and TV shows suitable for children, serving as an approximation of natural spoken language.
- Padding: Filtered corpora such as OpenSubtitles are used as padding to bring each language up to the standard for its tier.
- Language Coverage and Tiers:
- Covers 45 languages across multiple language families, including Indo-European, Semitic, and Bantu, ensuring linguistic diversity.
- The languages are divided into three tiers based on data volume (Tier 1/2/3), corresponding to about 100 million/10 million/1 million equivalent English words, enabling fair cross-lingual comparison.
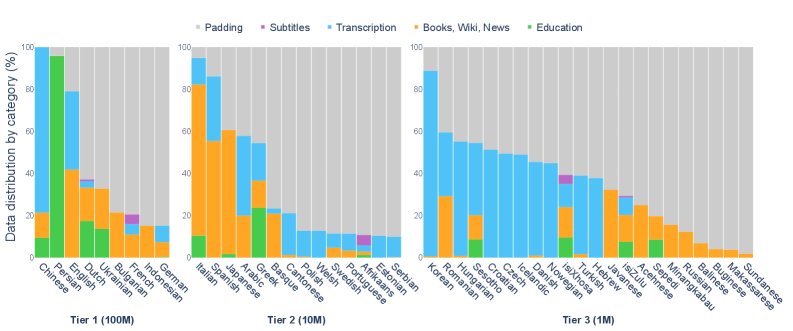
- Data Preprocessing: This includes language-specific initial processing and a unified standardization pipeline (such as Unicode normalization and whitespace/punctuation normalization), along with language and script verification using GlotLID v3 to ensure data quality.
Evaluation Suite
The paper builds a multilingual evaluation suite designed to assess models’ formal competence and functional competence.
- Formal Competence Evaluation: High-quality minimal-pair benchmarks (such as MultiBLiMP and CLAMS) are used to test how well models master grammatical rules such as subject-verb agreement.
- Functional Competence Evaluation: Multiple-choice and question-answering tasks are used to assess models’ factual knowledge (such as Global-MMLU), commonsense reasoning (such as HellaSwag and XCOPA), and reading comprehension (such as Belebele).
- Evaluation Method: Zero-shot prompts are used for minimal-pair tasks; for classification and question-answering tasks, because the baseline models are relatively small, evaluation is performed after fine-tuning.
Baseline Models
To provide a starting point for subsequent research, this paper trained a series of baseline models:
- Monolingual models: A GPT-2 architecture model with 17.1M parameters was trained separately for each of the 45 languages.
- Bilingual models: English data was added to the datasets of Tier 1 languages for training.
- Multilingual models: A 111M-parameter model trained on data from all 45 languages.
Experimental Conclusions
This paper evaluated the trained baseline models, with the main conclusions as follows:
- The models perform well on formal abilities: The monolingual models achieved good results on linguistic benchmarks such as MultiBLiMP, especially for Tier 1 languages with sufficient data, where accuracy often exceeded 80%. This shows that even small models can master core grammatical knowledge after exposure to developmentally plausible data. Performance is strongly correlated with data volume, and the models for Tier 2 and Tier 3 languages performed relatively worse.
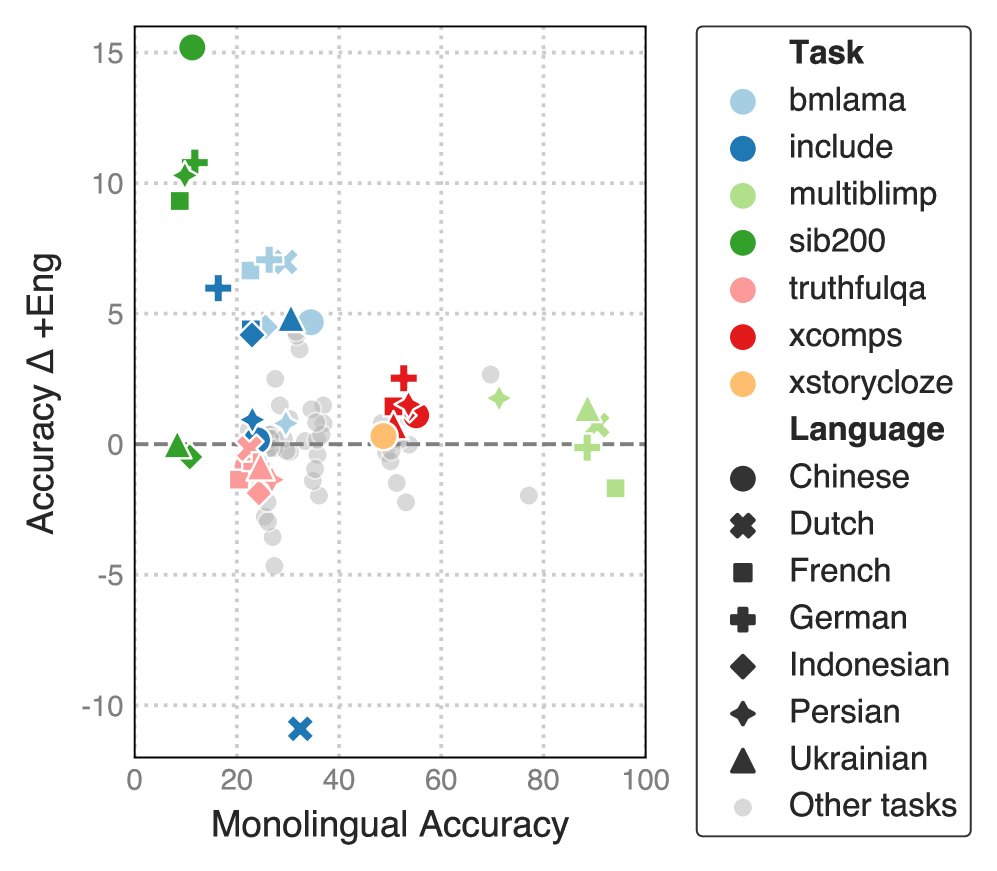
- The models have limited functional abilities: On functional tasks that require complex reasoning and world knowledge, such as XCOPA and ARC, the models performed close to random guessing. This suggests that, with only limited developmentally plausible data, these small models struggle to acquire advanced reasoning abilities.
- Monolingual models outperform multilingual models: On formal ability tasks (MultiBLiMP), the specially trained monolingual models usually outperformed the multilingual model trained on all languages, possibly because multilingual training diluted the model’s learning depth for any single language.
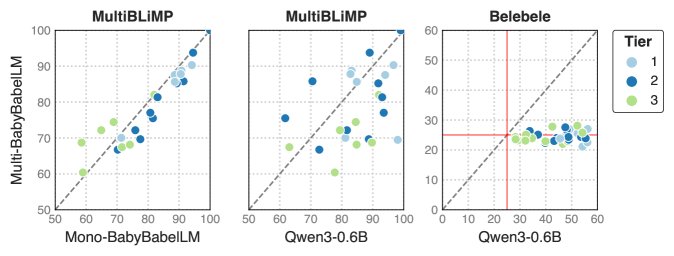
- Bilingual training has mixed effects: Adding English data to monolingual data for bilingual training had mixed effects on model performance. It improved some tasks and languages, but harmed others.
- Baseline models as a starting point: The experimental results show that the baseline models built in this paper have limited performance on their own, especially compared with larger models such as Qwen3-0.6B, but they successfully validate the benchmark and provide a solid starting point and reference baseline for future data-efficient, cognitively inspired model research on BabyBabelLM.
The table below shows the average accuracy of the monolingual models across tasks.
| Formal Capability | Functional Capability (After Fine-tuning) | Functional Capability (Zero-shot) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tier | Language Language | Multi BLiMP | Linguistic-Probes | Belebele | XNLI | MMLU | SIB-200 | ARC-c | XCOPA | TQA | XStory Cloze | Hella Swag | Wino grande | XCOMPS | |||
| … | Random | 50.0 | 50.0 | 25.0 | 33.3 | 25.0 | 25.0 | 25.0 | 50.0 | 50.0 | 50.0 | 25.0 | 50.0 | 50.0 | |||
| 1 | Bulgarian | ||||||||||||||||
| 1 | Chinese | ||||||||||||||||
| 1 | Dutch | ||||||||||||||||
| 1 | English | ||||||||||||||||
| 1 | French | ||||||||||||||||
| 1 | German | ||||||||||||||||
| 1 | Indonesian | ||||||||||||||||
| 1 | Persian | ||||||||||||||||
| 1 | Ukrainian | ||||||||||||||||
| 2 | Afrikaans | ||||||||||||||||
| 2 | Arabic | ||||||||||||||||
| 2 | Basque | ||||||||||||||||
| 2 | Estonian | ||||||||||||||||
| 2 | Greek | ||||||||||||||||
| 2 | Hebrew | ||||||||||||||||
| 2 | Italian | ||||||||||||||||
| 2 | Japanese | ||||||||||||||||
| 2 | Polish | ||||||||||||||||
| 2 | Portuguese | ||||||||||||||||
| 2 | Serbian | ||||||||||||||||
| 2 | Spanish | ||||||||||||||||
| 2 | Swedish | ||||||||||||||||
| 2 | Welsh | ||||||||||||||||
| 2 | Yue Chinese | ||||||||||||||||
| 3 | Achinese | ||||||||||||||||
| 3 | Balinese | ||||||||||||||||
| 3 | Buginese | ||||||||||||||||
| 3 | Croatian | ||||||||||||||||
| 3 | Czech | ||||||||||||||||
| 3 | Danish | ||||||||||||||||
| 3 | Hungarian | ||||||||||||||||
| 3 | Icelandic | ||||||||||||||||
| 3 | Javanese | ||||||||||||||||
| 3 | Korean | ||||||||||||||||
| 3 | Makasar | ||||||||||||||||
| 3 | Minangkabau | ||||||||||||||||
| 3 | Norwegian | ||||||||||||||||
| 3 | Sepedi | ||||||||||||||||
| 3 | Romanian | ||||||||||||||||
| 3 | Russian | ||||||||||||||||
| 3 | Sesotho | ||||||||||||||||
| 3 | Sundanese | ||||||||||||||||
| 3 | Turkish | ||||||||||||||||
| 3 | isiXhosa | ||||||||||||||||
| 3 | isiZulu |