Are Large Language Models Sensitive to the Motives Behind Communication?
-
ArXiv URL: http://arxiv.org/abs/2510.19687v1
-
Authors: Kerem Oktar; Addison J. Wu; Ryan Liu; Thomas L. Griffiths
-
Publisher: Anthropic; Princeton University
TL;DR
This article systematically investigates, by drawing on rational models from cognitive science, whether large language models (LLMs) can identify and evaluate the motives behind communication like humans do—that is, “motivational vigilance.” It finds that they show human-like abilities in controlled experiments, but perform poorly in complex real-world settings; however, simple prompting can improve their performance.
Key Definitions
This article introduces or emphasizes the following core concepts:
-
Motivational Vigilance: Originating in social cognition theory, this refers to an individual’s ability, when receiving information, to actively track the source’s intentions and incentives, thereby judging whether the information is biased (for example, benevolent or self-serving) and deciding how much to trust and adopt it. This is a key human ability for selective social learning.
-
Rational Model: This article uses the rational model proposed by cognitive scientists Oktar et al. as the “gold standard” for evaluating LLM motivational vigilance. The model formalizes vigilance as a recursive social reasoning process: the listener evaluates information by inferring the speaker’s intentions and incentives, while the speaker chooses the wording most likely to achieve their communication goals by anticipating the listener’s reasoning.
-
Deliberately Communicated Information: Information intentionally conveyed by the speaker to influence the listener, such as product pitches or advice.
-
Incidentally Observed Information: Information unintentionally revealed rather than directly intended to persuade the listener, such as overheard true thoughts or diary entries. Distinguishing between these two types of information is the first step in testing basic vigilance.
Related Work
At present, most online information handled by LLMs comes from human communication with purpose, and is inevitably shaped by personal motives and incentives. However, existing research shows that LLMs have clear shortcomings in this regard, such as being vulnerable to jailbreak attacks, exhibiting sycophancy (that is, agreeing with users’ incorrect views rather than stating facts), and being easily distracted by misleading information in online environments, such as pop-up ads. These issues expose a core bottleneck in LLM training paradigms: over-prioritizing following user instructions and satisfying user preferences, while lacking the ability to critically examine the motives behind information sources.
Although prior work has examined LLM social abilities such as Theory of Mind and conformity, the academic community still lacks a systematic framework for measuring LLM “vigilance” when processing motivated communication.
This article aims to fill that gap by introducing established theories and experimental paradigms from cognitive science, and for the first time providing a comprehensive and rigorous quantitative evaluation of LLM motivational vigilance.
Method
This article designs three progressively more challenging experimental paradigms to evaluate LLM motivational vigilance across different contexts.
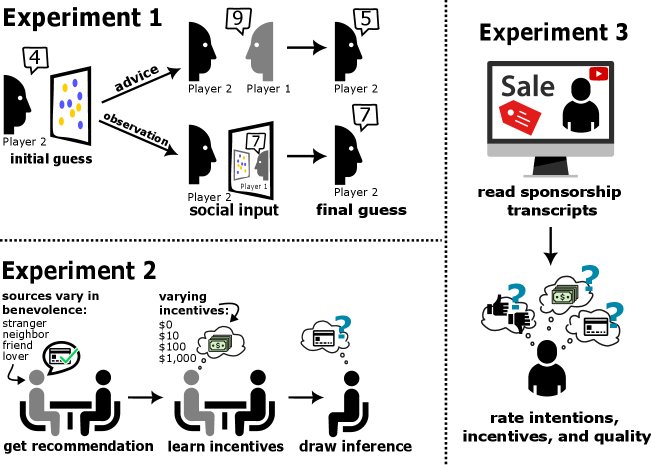
Experiment 1: Distinguishing Different Information Sources
This experiment aims to test whether LLMs possess the most basic vigilance ability: distinguishing between “deliberately communicated information” and “incidentally observed information.”
- Experimental setup: The article adapts the classic two-player judgment task. In the task, two players (both played by LLMs) must compute the difference in the number of blue and yellow circles in an image. Player 2 receives information from Player 1, which may either be a “suggestion” intentionally given by Player 1 (deliberately communicated) or Player 1’s true answer that Player 2 “spied” on (incidentally observed). The experiment also includes two incentive structures: cooperation and competition.
- Innovation: To address the issue that LLMs are not constrained by the time limits present in human experiments, the article increases task difficulty by adding noise to the images, thereby effectively inducing uncertainty in the LLM and allowing it to exhibit a belief-updating process.
Experiment 2: Fine-Grained Calibration of Motives
This experiment aims to test whether LLMs can, like humans, finely adjust their trust based on the speaker’s intentions (such as closeness) and incentives (such as commission level).
- Core method: The article introduces the rational model proposed by Oktar et al. as the evaluation benchmark. The model uses mathematical formulas to characterize how a listener reasons based on the speaker’s benevolence \(λ\), the listener’s own payoff \(R_L\), and the speaker’s payoff \(R_S\).
- The speaker’s joint utility is determined by their benevolence \(λ\):
-
The probability that the speaker chooses a particular utterance \(u\) depends on the joint utility that utterance may bring:
\[P_{S}(u\mid R_{S},R_{L},\lambda,A)\propto\exp\{\beta_{S}\cdot\sum_{a\in A}R_{\text{Joint}}(R_{L},R_{S},\lambda,a)\pi_{L}(a\mid u)\}\] -
A vigilant listener uses Bayesian inference to infer the true value \(R_L\) of the recommended option in reverse:
\[P_{L}(R_{L}\mid u)\propto P_{S}(u\mid R_{S},R_{L},\lambda,A)P(R_{s})P(R_{L})P(\lambda)\] -
Experimental setup: In scenarios such as finance, real estate, and healthcare, LLMs are asked to evaluate product recommendations from speakers with different levels of credibility (roles) and incentives. Through prompting, the LLM’s “trust score” (corresponding to \(λ\)), “incentive score” (corresponding to \(R_S\)), and “influence score” (corresponding to $$P(R_L u)$$) are elicited, and the “influence score” is compared with the rational-model prediction based on its own trust and incentive scores.
Experiment 3: Generalization to Real-World Scenarios
This experiment aims to test whether the vigilance learned by LLMs in controlled settings can transfer to real-world scenarios full of noise and complex context.
- Dataset construction: The article creates a new test set with greater ecological validity. Using SponsorBlock and the YouTube API, it collects 300 real YouTube sponsored ad segments and extracts their titles, channel information, and ad scripts. To avoid interference from the model’s prior knowledge, all brand and product names are anonymized.
- Experimental setup: Similar to Experiment 2, LLMs are asked to evaluate the quality of the product promoted in each sponsored video, the credibility of the YouTuber, and the incentive the YouTuber receives from it. Their judgments are then compared again with the rational-model predictions to measure vigilance in natural settings.
Experimental Conclusions
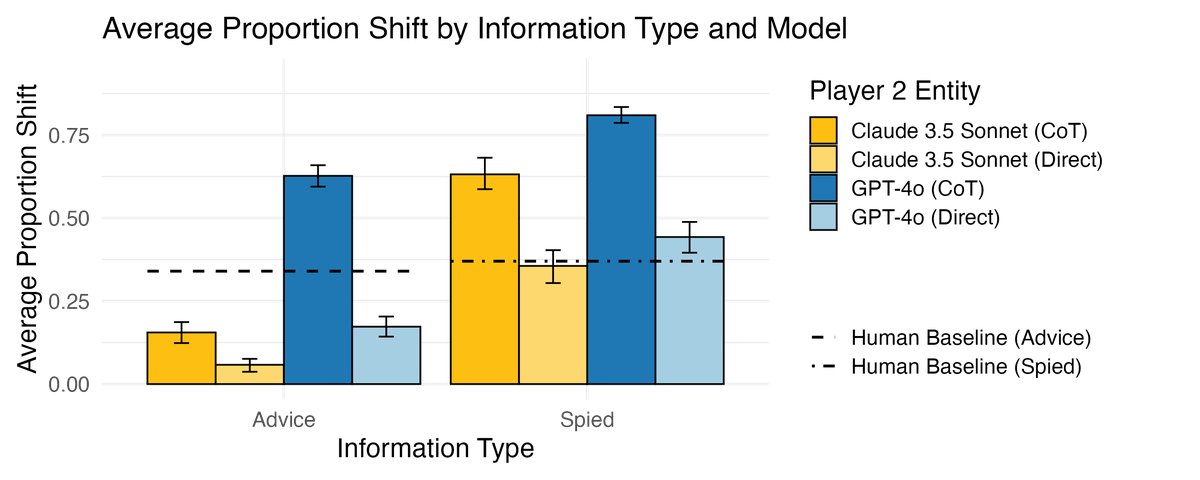
Experiment 1: LLMs Have Basic Discriminative Ability
- LLMs can successfully distinguish between intentionally given advice and unintentionally observed information. When receiving “advice,” they adjust their answers significantly less than when receiving “spied-on” answers, which is consistent with human behavior and indicates that LLMs possess basic motivational vigilance.
- An interesting finding is that Chain-of-Thought (CoT) prompting, while enhancing reasoning, also makes LLMs trust external information more, causing their behavior to deviate from human vigilance patterns.
Experiment 2: Frontier LLMs Exhibit Highly Rational Vigilance in Controlled Settings
- Frontier models perform excellently: Top non-reasoning LLMs (such as GPT-4o and Claude 3.5 Sonnet) exhibit vigilance behavior highly consistent with the rational model, with correlations between their judgments and the model’s predictions (Pearson’s r) generally ranging from 0.8 to 0.9; GPT-4o performs best (average $r = 0.911$).
- LLMs are more “human-like” than the rational model: The judgments of these frontier models correlate with human data even more strongly than the rational model does, suggesting that they may capture heuristics or biases used by humans when evaluating advice, beyond the rational model.
- Model capability scales with size: In contrast, reasoning-specialized models (such as o1 and DeepSeek-R1) and small models (such as Llama 3.1-8B) perform much worse in vigilance, with lower correlations between their judgments and the rational model. This suggests that motivational vigilance is an emergent ability that improves with model scale and capability.
| Model (Model) | Corr. with rational model | Corr. with human data |
|---|---|---|
| GPT-4o | 0.911 | 0.871 |
| Claude 3.5 Sonnet | 0.865 | 0.817 |
| Gemini 1.5 Flash | 0.803 | 0.763 |
| Llama 3.1-70B | 0.781 | 0.749 |
| anyscale/o2-22b | 0.724 | 0.692 |
| anyscale/o1-70b | 0.697 | 0.639 |
| Llama 3.1-8B | 0.603 | 0.583 |
| anyscale/o3-mini | 0.536 | 0.509 |
| Gemma 2-9B | 0.490 | 0.457 |
| Llama 3.1-4.5B | 0.389 | 0.364 |
| DeepSeek-R1 | 0.326 | 0.301 |
Experiment 3: Vigilance Fails in Real-World Settings, but Can Be Guided
- Poor generalization: When faced with real-world YouTube ads, the motivational vigilance of all LLMs drops sharply, with the correlation between their judgments and the rational model’s predictions falling to $r < 0.2$. This suggests that in complex, noisy real-world environments, models struggle to effectively use their latent vigilance and are easily distracted by irrelevant information.
- Prompt steering works: However, a simple intervention—vigilance-based prompt steering—that explicitly emphasizes the speaker’s intent and incentives in the prompt can significantly improve LLM performance, greatly increasing the consistency of their judgments with the rational model.
Summary
This study shows that current LLMs possess a latent, foundational motivational vigilance that enables them to reason about the motives behind information sources in simple, controlled settings. However, this ability is very fragile and does not easily generalize to challenging real-world applications without explicit guidance. To enable LLMagent to serve users safely and effectively in the real world, future research needs to further improve the model’s ability to robustly apply this latent capability in complex scenarios.