An Empirical Study of SFT-DPO Interaction and Parameterization in Small Language Models
DPO Delivers Little Gain, LoRA Gets Overtaken? Stanford Reveals the “Optimal Solution” for Small-Model Fine-Tuning

At present, Direct Preference Optimization (DPO) and Low-Rank Adaptation (LoRA) have almost become the “standard moves” for large-model alignment and fine-tuning. We seem to take it for granted that first doing supervised fine-tuning with SFT, then aligning preferences with DPO, while using LoRA to save resources, is a golden combo.
ArXiv URL:http://arxiv.org/abs/2603.20100v1
But what if your model is not that “large,” and your data is not that “much”? Does this combo still work?
A recent empirical study from Stanford University puts a big question mark on this seemingly obvious workflow. The researchers systematically “dissected” the interactions among SFT, DPO, full fine-tuning, and LoRA on a small model like GPT-2 (124 million parameters).
The conclusion may overturn your assumptions: for small models, the gains from DPO may be negligible, while LoRA is even comprehensively outperformed by Full Fine-Tuning (FFT) in terms of performance, with its training-speed advantage disappearing as well!
Research Background: When DPO and LoRA Meet Small Models
Before diving deeper, let’s quickly review a few key concepts:
-
SFT (Supervised Fine-Tuning): supervised fine-tuning using labeled data to teach the model to imitate correct answers. This is the foundation of fine-tuning.
-
DPO (Direct Preference Optimization): a simpler alignment method than RLHF. It directly uses preference data (for example, answer A is better than answer B) to teach the model to generate more preferred content.
-
FFT (Full Fine-Tuning): full fine-tuning, meaning all model parameters are updated. It delivers the best results, but also consumes the most resources.
-
LoRA (Low-Rank Adaptation): a representative parameter-efficient fine-tuning (PEFT) method. It introduces a small number of trainable “low-rank matrices” to simulate parameter updates, freezing most of the original parameters and greatly reducing memory usage.
Although these techniques are widely used on large models, their performance and interactions on small models and with medium-sized datasets have long lacked systematic study. This paper aims to fill that gap.
Experimental Design: Two Tasks, Multi-Dimensional Comparison
To reach reliable conclusions, the researchers designed rigorous comparative experiments.
-
Base model: GPT-2 (124M), a classic decoder-only architecture model.
-
Two tasks:
-
Paraphrase detection (classification task): determine whether two Quora questions express the same meaning.
-
Shakespeare sonnet continuation (generation task): given the opening of a poem, generate the following content.
-
Core comparison dimensions:
-
Training strategy: SFT-only vs. DPO-only vs. SFT combined with DPO.
-
Parameterization strategy: FFT vs. LoRA.
By cross-validating these strategies across different tasks, the study aims to answer two core questions:
-
On small models, which is better, FFT or LoRA?
-
How do SFT and DPO interact? When should DPO be introduced?
Key Finding 1: Parameters Rule, and Full Fine-Tuning (FFT) Wins Across the Board
In model fine-tuning, we often choose LoRA for efficiency. However, the first surprising finding of this study is: at the GPT-2 scale, the choice of parameterization strategy has a greater impact than whether a DPO stage is added, and FFT is the clear winner.
The researchers compared FFT with LoRA at different ranks ($r=4, 8, 16$) on the paraphrase detection task. The results showed:
-
Better performance: FFT consistently outperformed all LoRA configurations in accuracy and F1 score. Even the best-performing LoRA ($r=8$) still lagged noticeably behind FFT.
-
Faster training: More surprisingly, LoRA did not shorten training time on the H100 GPU. The researchers pointed out that for a small model like GPT-2, the training bottleneck is compute-bound rather than memory-bound. The memory savings from LoRA cannot be translated into an actual training-speed advantage.
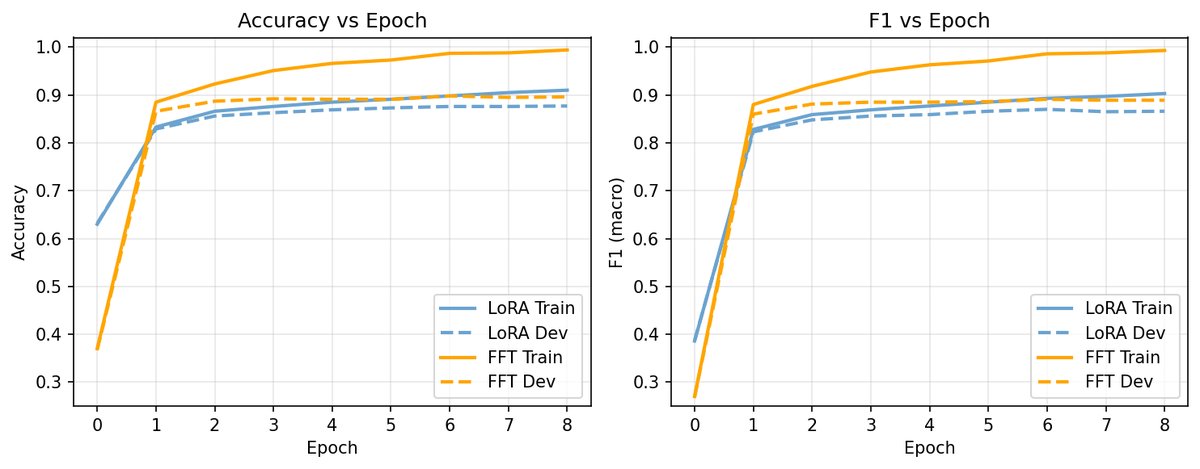
The figure above clearly shows FFT (blue solid line) leading throughout in development-set accuracy over LoRA with different ranks (dashed lines).
This finding reminds us: LoRA’s efficiency advantage is not absolute; it depends heavily on model scale and hardware conditions. For small models, the “efficiency” gained by sacrificing performance may not exist at all.
Key Finding 2: DPO Has Limited Marginal Benefit
As a star technique for aligning models, how does DPO perform? The answer is: on top of a strong SFT foundation, the improvement brought by DPO is very limited, and may even be negligible.
The researchers explored different SFT-to-DPO “handoff” timings, including SFT-only, DPO-only, and switching to DPO after early (the 3rd epoch) and late (the 9th epoch) stages of SFT training.
-
Tiny gains: On a model that has been sufficiently trained with SFT, further DPO brings only very small performance improvements, and sometimes none at all.
-
A surprise from DPO-only: Interestingly, on the paraphrase detection task, training directly with DPO-only from scratch could match SFT-only performance. The researchers analyzed that this is because the preference construction for this task (correct label vs. incorrect label) is highly similar to the supervised signal in SFT, allowing DPO to learn the decision boundary directly.
-
Even weaker with sparse data: On the extremely data-scarce sonnet continuation task (only 131 training poems), DPO could hardly bring any meaningful improvement over SFT. This suggests that when both model capacity and data scale are limited, DPO struggles to play its role as a “fine adjustment” method.
In short, DPO is not a cure-all. It is more like a “dessert after the meal” for a model that has already been “fed” enough knowledge through SFT, and for small models, this dessert may be neither tasty nor necessary.
Practical Implications: Best Practices for Small-Model Fine-Tuning
Based on the findings of this study, we can distill several highly practical recommendations for fine-tuning small models (such as GPT-2-scale models):
-
Prioritize full fine-tuning (FFT): if compute resources allow, do not hesitate—go straight to FFT. On small models, it is the most reliable lever for achieving the best performance. Do not assume that LoRA is necessarily faster or equally effective.
-
SFT is the foundation; build it solidly: rather than getting tangled up in complex DPO workflows, focus your energy on building a high-quality dataset and carrying out sufficient SFT training. A strong SFT base is the fundamental guarantee of performance.
-
Carefully assess whether DPO is necessary: introducing DPO requires case-by-case analysis. If your SFT model is already performing well, DPO may only bring negligible gains. Before adding it, ask yourself whether you really need that “1% improvement.”
-
Data scale matters more than training epochs: the study also found that training for fewer epochs on more diverse data works far better than repeatedly training on a small dataset. Data diversity is key to improving generalization.
Conclusion
This empirical study from Stanford reveals the “plain truth” of fine-tuning in small-model and limited-data settings: rather than chasing techniques like DPO and LoRA that shine in the “large-model world,” it is better to return to the basics and do full-parameter supervised fine-tuning (FFT-SFT) solidly.
This does not mean that DPO and PEFT have no value; rather, it emphasizes that technology choices must be made “according to local conditions.” For practitioners with limited resources and small model sizes, instead of pouring precious compute into advanced techniques with uncertain returns, it is better to concentrate firepower and push the most basic and core SFT to the limit.
Next time you fine-tune a small model, you might want to set aside your attachment to DPO and LoRA for a moment and try the simplest, most direct FFT first—the result may pleasantly surprise you.