AI Progress Should Be Measured by Capability-Per-Resource, Not Scale Alone: A Framework for Gradient-Guided Resource Allocation in LLMs
-
ArXiv URL: http://arxiv.org/abs/2511.01077v1
-
Authors: Yulun Wu; David McCoy
-
Publishing Institutions: Capital One; University of California, Berkeley
TL;DR
This article argues for measuring AI progress by “capability-per-resource” rather than scale alone, and proposes a theoretical framework for gradient-guided resource allocation. By identifying and prioritizing high-impact parameters and data, it can significantly improve efficiency throughout the lifecycle of large language models (LLMs).
Key Definitions
- Capability-Per-Resource: The core evaluation metric proposed in this article, measuring the performance gain brought by each unit of resource input (such as GPU hours or energy consumption), i.e., $\Delta\Psi/\Delta\Gamma$. This metric aims to shift the goal of AI development from pursuing absolute performance to pursuing resource efficiency.
- Gradient Blueprints: Metadata released together with model weights that records statistics such as gradient norms of each submodule under representative tasks. Its purpose is to reveal to downstream users which model components are most “influential” for specific tasks, thereby guiding efficient parameter selection and fine-tuning.
- Scaling Fundamentalism: A term used in this article to describe a dominant trend in current AI research: the belief that capability gains can be achieved simply by continuously increasing model size and compute investment, often while ignoring resource efficiency and sustainability.
- Partial-Update Advantage: A theoretical concept proposed in this article, referring to the fact that under realistic conditions where gradients follow a heavy-tailed distribution, updating only a small subset of high-impact parameters is strictly more efficient in terms of “capability-per-resource” than fully fine-tuning all parameters.
Related Work
In the current AI field, especially in the development of large language models, “scaling fundamentalism” dominates. Research follows scaling laws such as “Chinchilla,” pursuing larger models and more data. This has brought tremendous success, but it has also led to high environmental costs and a resource divide, creating a “compute oligarchy” in which a small number of well-resourced institutions develop foundation models while the broader research community adapts under resource constraints.
To address resource limitations, researchers have developed a variety of efficiency-improving techniques. Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA, QLoRA, and Adapters reduce memory and compute overhead by updating only a small fraction of parameters. Model compression techniques such as pruning and attention-head removal reduce redundant parts of the model after training. Research on data efficiency includes importance sampling and curriculum learning.
The specific problem this article aims to solve is: although the above efficiency-improving methods exist, they are mostly treated as “stopgap measures” or “engineering tricks” when resources are scarce, lacking a unified theoretical framework to explain why they work. In addition, research on parameter efficiency and data efficiency is often conducted independently, and there is a lack of a mechanism to systematically transfer insights from foundation model developers (who have resources) to downstream model adapters (who are resource-constrained). The goal of this article is to build such a theoretical framework, elevate selective updating from a “trick” to a “principle,” and propose “Gradient Blueprints” as a practical tool to achieve this.
Method
This article proposes a resource-aware framework for LLM development and evaluation, with the core idea of maximizing “capability-per-resource” ($\Delta\Psi/\Delta\Gamma$). The framework has two levels: a two-stage paradigm applicable to both foundation model developers and downstream adapters, and the theoretical basis supporting that paradigm.
Two-Stage Development Paradigm
The framework in this article is designed with different strategies for two major participants in the AI ecosystem:
-
Foundation Model Developers: During the pretraining stage, developers should adopt a “marginal-return pretraining” strategy. Specifically, they should continuously monitor the performance gain per unit of resource ($\Delta\Psi/\Delta\Gamma$), and stop training when this ratio remains below a preset threshold $\eta$ within a certain window. This strategy avoids wasting large amounts of compute during periods of diminishing returns. After training, developers should release not only the model weights, but also Gradient Blueprints.
-
Model Adapters: Downstream users, under resource constraints, use the gradient blueprints for “influence-guided adaptation.” The blueprints reveal which model submodules (such as attention blocks or feed-forward networks in specific layers) contribute the most to gradients for relevant tasks. Adapters only need to selectively fine-tune these high-impact parameters (for example, just 10-20% of the total parameters) to achieve performance close to full fine-tuning at very low resource cost, greatly reducing memory and compute overhead.
This paradigm builds a bridge between developers and adapters through gradient blueprints, enabling the transfer of efficiency knowledge.
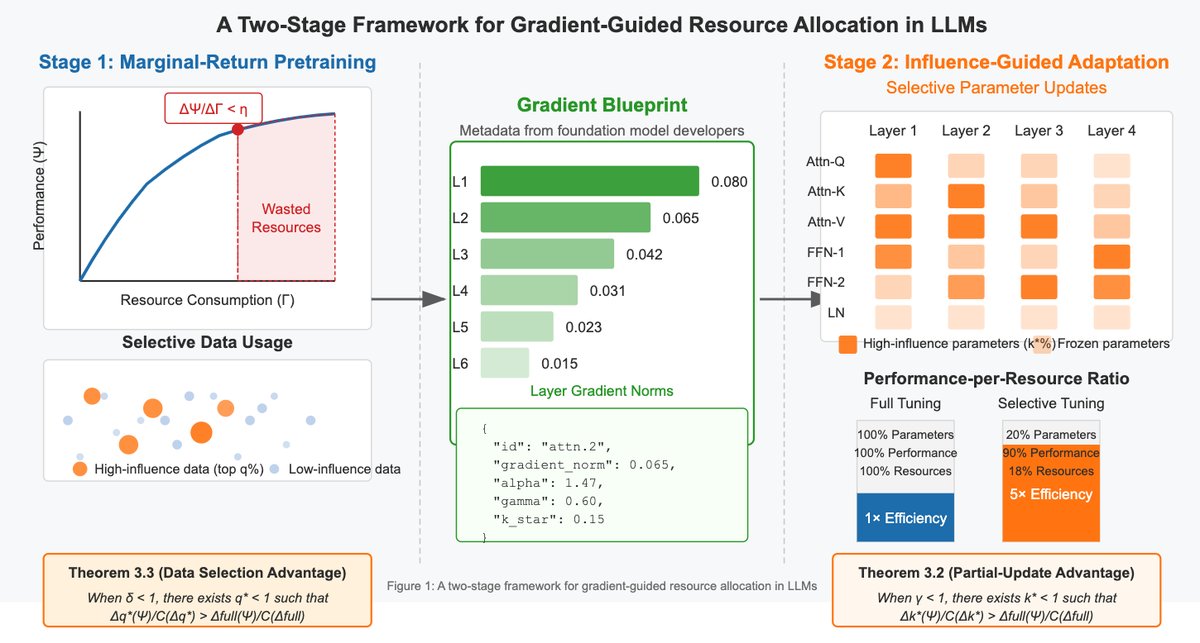
Theoretical Basis
The article provides a solid theoretical foundation for the above framework, proving that selective updating is not a compromise, but the optimal strategy under certain conditions.
Advantage of Partial Parameter Updates
Core idea: In models where the gradient distribution is heavy-tailed or power-law-like (which is common in Transformer), updating only a small subset of parameters is more efficient in terms of “capability-per-resource” than updating all parameters.
The gradient distributions of many LLMs follow a power-law decay, i.e., the $r$-th largest gradient norm $\ \mid \nabla_{\theta_{(r)}}\ \mid \approx Cr^{-\alpha}$ (where $\alpha>1$). This means that a small number of parameters account for the vast majority of gradient magnitude. Therefore, updating only this set of “high-impact” parameters (for example, the top $k\%$) may use only $k\%$ of the resources while achieving a performance gain far greater than $k\%$. The article theoretically proves that there exists an optimal update ratio $k^*$ such that the resource efficiency of partial updating is strictly higher than that of full updating:
\[\frac{\Delta_{k^{*}}(\Psi)}{\mathcal{C}(\Delta_{k^{*}})} > \frac{\Delta_{\mathrm{full}}(\Psi)}{\mathcal{C}(\Delta_{\mathrm{full}})}\]This conclusion elevates LoRA and other PEFT methods from engineering tricks to theoretically optimal resource allocation strategies.
Approximating Influence with Simple Gradients
Core idea: Expensive second-order influence calculations (such as the Hessian matrix) can be effectively approximated by simple first-order gradient norms $\ \mid \nabla_{\theta_i}\ \mid $.
The most accurate way to determine which parameters are “high-impact” is to compute second-order derivatives, but this is extremely costly in LLMs. The article proves that, under the Fisher information matrix approximation, the true influence of parameters on performance is approximately proportional to their first-order gradient norms. Therefore, by computing and ranking gradient norms, one can efficiently and accurately identify the most important parameters. This provides theoretical justification for releasing gradient norm statistics through gradient blueprints.
Data Selection and Cross-Influence
Core idea: Efficiency gains can be achieved along both the parameter and data dimensions, and combining the two can produce a multiplicative effect.
Like parameters, different training data points also contribute very unevenly to model updates (i.e., data influence is also heavy-tailed). By identifying and prioritizing those “high-impact” data samples that produce the largest gradient updates, training efficiency can be further improved.
The article further proposes the concept of cross-influence, defined as the tensor $T_{i,j}=\left \mid \frac{\partial L(z_j;\theta)}{\partial\theta_i}\right \mid $, which describes the specific influence of data sample $z_j$ on parameter $\theta_i$. When high-impact parameters and high-impact data are selected for updating at the same time, the improvement in resource efficiency is multiplicative. For example, if keeping 20% of the parameters can achieve 80% of the performance, and keeping 30% of the data can achieve 90% of the performance, then combining the two may use only $20\% \times 30\% = 6\%$ of the resources to reach $80\% \times 90\% = 72\%$ of the performance, achieving more than a 10x improvement in capability-per-resource efficiency.
Experimental Conclusions
This paper is a position and theoretical framework paper, and its main contribution lies in proposing a brand-new evaluation and development paradigm, along with a mathematical foundation for it. Therefore, the paper’s conclusions mainly come from theoretical analysis rather than large-scale empirical experiments. The specific case studies mentioned at the end of the paper, such as biomedical adaptation, were not fully presented.
The core conclusions of the paper are as follows:
-
Theoretical validity: The paper theoretically proves that, under the condition that gradients follow a heavy-tailed distribution (which is common in Transformer), partial updates are strictly superior to full updates in terms of the “unit resource capability” metric. This provides a solid mathematical explanation for the success of PEFT and similar methods, and reframes them from a “compromise under hardware constraints” into a “theoretically superior resource allocation strategy.”
-
Method feasibility: By proving that simple first-order gradient norms can serve as an effective proxy for parameter influence, this paper provides theoretical support for the practical tool of “gradient blueprints.” Developers do not need to perform complex second-order computations; they only need to record and publish easily accessible gradient statistics to provide highly valuable guidance for downstream users.
-
Multiplicative effect of efficiency: This paper reveals redundancy in LLM training along both the parameter and data dimensions. By coordinating parameter selection and data selection, it is possible to achieve a multiplicative improvement in efficiency, potentially reducing resource requirements by several orders of magnitude.
In the end, the paper concludes that the AI field should move away from “scale-only” thinking and toward an evaluation system centered on “unit resource capability.” By adopting the gradient-guided resource allocation framework and practical tools such as “gradient blueprints” proposed in this paper, the AI community can drive technological progress while building a more sustainable, fair, and efficient future, enabling more researchers with limited resources to participate in the development and innovation of frontier AI.