AgentFold: Long-Horizon Web Agents with Proactive Context Management
-
ArXiv URL: http://arxiv.org/abs/2510.24699v1
-
Author: Zhengwei Tao; Yong Jiang; Pengjun Xie; Rui Ye; Huifeng Yin; Jingren Zhou; Kuan Li; Siheng Chen; Zhongwang Zhang; Fei Huang; and 15 others
-
Publisher: Alibaba Group; Tongyi Lab
TL;DR
This paper proposes a new web agent called AgentFold. By mimicking the way humans actively manage their mental scratchpad, it proactively “folds” and integrates context when carrying out long-horizon tasks, thereby avoiding the loss of key information while keeping the context concise, and achieving state-of-the-art performance with a relatively small model size.
Key Definitions
This paper follows the basic concepts of existing agents and introduces the following core definitions to build its method:
- Context Folding: The core mechanism of AgentFold, referring to the agent’s active summarization and compression of historical information during task execution. It includes two operation modes:
- Granular Condensation: Compresses the full record of the most recent interaction into a concise summary block to preserve fine-grained information.
- Deep Consolidation: Merges the most recent interaction with a series of previous summary blocks to form a higher-level, coarser-grained summary, suitable for summarizing the final conclusion after a subtask is completed.
-
Multi-scale State Summaries: The agent’s long-term memory, an ordered sequence composed of multiple summary blocks. Each summary block \(s_{x,y}\) records the interaction summary from step \(x\) to step \(y\), with variable granularity, allowing historical information to be preserved at different scales.
-
Latest Interaction: The agent’s high-fidelity working memory, which records the most recent interaction in full and without loss, including the agent’s brief reasoning (explanation), the tool calls executed, and the observations returned by the environment.
- Fold-Generator: An automated data collection pipeline developed specifically in this paper for training AgentFold. Since existing datasets cannot meet the training requirements, this pipeline uses a powerful large language model and a series of rejection-sampling mechanisms to generate training trajectories containing high-quality context management operations.
Related Work
Current web agent research is mainly built on the ReAct paradigm, i.e., interacting with the environment in a “reasoning-action-observation” loop. However, this pattern faces a key bottleneck in long-horizon tasks: the trade-off dilemma of context management strategies.
- Current Status and Bottlenecks:
- Append-Only Strategy: Methods represented by ReAct retain all historical interactions in the context in full. While this ensures information completeness, as the task grows longer, the context is quickly filled with noise from the raw web data, making it difficult for the agent to identify key signals and make suboptimal decisions.
- Full-History Summarization Strategy: Some newer methods summarize the entire history at every step to keep the context clean. However, this mechanical compression strategy carries a huge risk: key details may be lost too early and irreversibly in any single summary, leading to “catastrophic forgetting.”
- Problem This Paper Aims to Solve: This paper aims to resolve the sharp contradiction between “retaining redundant noise” and “risking information loss.” The goal is to design an agent that can actively manage its cognitive workspace (context) like a human, so that in long-horizon tasks it can keep the context focused, concise, and efficient while avoiding the accidental loss of key information.
Method
Overview
AgentFold mimics human cognitive processes, and its core design lies in defining the agent’s context as a dynamic cognitive workspace, while endowing the agent with the ability to actively manage and shape this workspace as part of its core reasoning capability.
AgentFold’s workspace mainly consists of three parts: the fixed user question, the organized Multi-scale State Summaries (as long-term memory), and the high-fidelity Latest Interaction (as immediate working memory). At each iteration, the agent’s reasoning produces a multi-part response, including a folding directive for managing historical summaries, an explanation of its thought process, and the next action. The folding directive immediately updates long-term memory, while the observation produced by the action, together with the action itself, forms the “latest interaction” for the next cycle. This loop turns context management from a passive byproduct into an active, learnable core step, resolving the contradiction between preserving details and preventing context bloat.
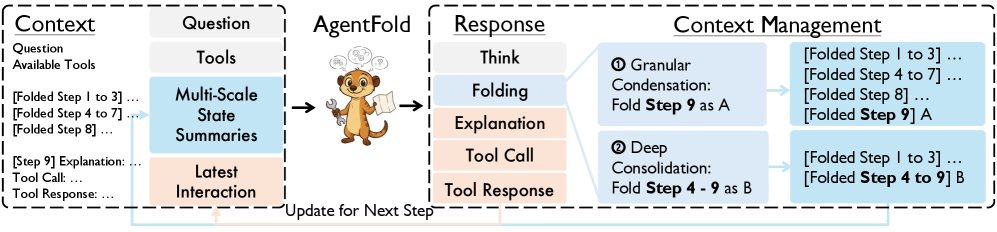 An overview of AgentFold at an intermediate step. The two key parts of AgentFold’s context are: Multi-scale State Summaries (multiple folded blocks recording prior information) and Latest Interaction (the full record of the most recent step). AgentFold responds with four blocks: thought, fold, explanation, and tool call (which brings an additional tool response). The folding directive has two operation modes: granular condensation (preserving useful information and folding a single step) and deep consolidation (folding multiple steps into a coarse summary when those steps complete a subtask and the intermediate details are no longer important for further task solving).
An overview of AgentFold at an intermediate step. The two key parts of AgentFold’s context are: Multi-scale State Summaries (multiple folded blocks recording prior information) and Latest Interaction (the full record of the most recent step). AgentFold responds with four blocks: thought, fold, explanation, and tool call (which brings an additional tool response). The folding directive has two operation modes: granular condensation (preserving useful information and folding a single step) and deep consolidation (folding multiple steps into a coarse summary when those steps complete a subtask and the intermediate details are no longer important for further task solving).
AgentFold’s Context: Multi-scale State Summaries and Latest Interaction
AgentFold’s context is carefully designed as a dynamic cognitive workspace with four parts to support strategic long-term planning and precise immediate action.
- Question: As the anchor of the task, it continuously reminds the agent of the final goal.
- Available Tools: Defines the agent’s action capabilities in the environment, listing the names, descriptions, and parameters of all tools.
- Multi-scale State Summaries: The agent’s curated long-term memory. It preserves historical steps at different granularities; key findings can be retained as independent fine-grained summaries, while less important intermediate steps can be integrated into coarser abstract blocks.
- Latest Interaction: As high-fidelity working memory, it provides the full record of the most recent interaction, including explanations, tool calls, and observations.
At step \(t\), the context \(C_t\) provided to the agent is a triplet:
\[C_{t}=(Q,T,S_{t-2},I_{t-1})\]where \($Q\)$ and \($T\)$ are the invariant user question and tool list. \($S\_{t-2}\)$ is the Multi-scale State Summaries, a dynamically updated sequence of compressed summaries of past steps, represented as \($S\_{t-2}=(s\_{x\_1,y\_1}, s\_{x\_2,y\_2}, \ldots, s\_{x\_m,y\_m})\)$, where each \($s\_{x,y}\)$ is a text summary of the continuous interactions from step \($x\)$ to step \($y\)$. \($I\_{t-1}\)$ is the Latest Interaction, namely the full interaction record of step \($t-1\)$, \($I\_{t-1}=(e\_{t-1}, a\_{t-1}, o\_{t-1})\)$.
This structured design offers the best of both worlds: the Latest Interaction provides the lossless raw details needed for short-term decisions, while the Multi-scale State Summaries provide a noise-free, abstracted task overview, enabling the agent to perform coherent long-term reasoning and directly alleviating the trade-off faced by modern web agents between context completeness and conciseness.
AgentFold’s Response: Thought, Fold, Explanation, Action
At each step, AgentFold generates a structured multi-part text response \($R\_t\)$, which can be parsed as a quadruple:
\[R_{t}=\text{AgentFold}(C_{t};\theta)\rightarrow(th_{t},f_{t},e_{t},a_{t})\]-
Thinking (Thinking, \($th\_t\)$): A detailed chain-of-thought monologue in which the intelligent agent analyzes the context and weighs options for context folding and subsequent actions.
- Folding (Folding, \($f\_t\)$): Explicit instructions used by the intelligent agent to shape its long-term memory, expressed in JSON format \($f\_t = \{\text{"range": [k, t-1], "summary": "}\sigma\_t\text{"}\}\)$. \($k\)$ is the starting step ID for folding, and \($\sigma\_t\)$ is the replacement summary generated by the intelligent agent. This instruction supports two operation modes:
- Granular Condensation (Granular Condensation) (\($k = t-1\)$): folds only the most recent interaction, turning it into a new, fine-grained summary block. This is used for incremental steps and preserves the highest resolution of the historical trajectory.
- Deep Consolidation (Deep Consolidation) (\($k < t-1\)$): merges the most recent interaction with a series of previous summaries into a coarse-grained summary. When a subtask (for example, verifying a fact over multiple steps) is completed, this operation can abstract the entire process into a final conclusion, thereby clearing away the noise of intermediate steps.
-
Explanation (Explanation, \($e\_t\)$): A concise explanation distilled from the thinking process of the motivation behind the chosen action.
- Action (Action, \($a\_t\)$): The external action selected by the intelligent agent, which can be either a tool call or the final answer.
This response structure tightly couples action planning with context management, forming a self-regulating loop: planning actions requires reviewing history, which provides signals for deciding what information to retain; organizing history, in turn, deepens understanding of the current state, enabling more effective action decisions.
Training AgentFold: Data Trajectory Collection
To train AgentFold, the paper developed Fold-Generator, a specialized data collection pipeline for generating training trajectories with complex context management operations. Given that even the most advanced LLMs struggle to reliably produce the structured multi-part responses required by AgentFold through simple prompt engineering, this pipeline adopts a rejection sampling mechanism that discards trajectories with formatting errors or excessive environmental errors to ensure data quality.
Ultimately, Fold-Generator produces a high-quality set of interaction pairs \($\{(C\_t, R\_t^\*)\}\_N\)$ for Supervised Fine-Tuning (SFT) of open-source LLMs. This training method internalizes the complex “generate-filter” strategy into the weights of the AgentFold model, transforming it from a fragile, prompt-dependent instruction into a robust, internalized skill and significantly improving inference efficiency.
Discussion
The design of AgentFold overcomes the limitations of the ReAct pattern, which leads to context saturation, and full-history summarization, which risks information loss. Its core advantage lies in the ability to flexibly adjust the folding strategy according to task requirements.
For example, if the probability that a key detail survives each round of full-history summarization is 99%, then after 100 steps the probability of complete retention is only \($0.99^{100} \approx 36.6\%\)$, and after 500 steps it drops sharply to \($0.99^{500} \approx 0.6\%\)$. AgentFold preserves such details in an independent summary block through Granular Condensation, sparing them from unnecessary repeated processing and thereby avoiding this compounded risk. At the same time, through Deep Consolidation, AgentFold can surgically remove the cumbersome process of completed subtasks, solving the inevitable context bloat problem in the ReAct pattern.
This design, which treats context management as a learnable core action, makes AgentFold an active curator of its own information workspace, achieving a significant improvement in robustness and efficiency for long-horizon complex tasks.
Experimental Conclusions
The experiments were trained on the Qwen3-30B-A3B-Instruct-2507 model and evaluated on four benchmarks: BrowseComp, BrowseComp-ZH (for information localization ability), WideSearch (for broad search ability), and GAIA (for general intelligent agent capability).
Results and Analysis
| Model | Parameters | BrowseComp | BrowseComp-ZH | WideSearch F1 | GAIA |
|---|---|---|---|---|---|
| Proprietary Agents | |||||
| OpenAI Deep Research | - | 42.1 | 42.0 | 56.6 | 21.0 |
| Claude-4-Opus | - | - | - | 61.1 | 51.5 |
| OpenAI-o3 | - | 36.7 | 42.0 | 66.8 | 64.9 |
| Claude-4-Sonnet | - | 35.8 | 38.0 | 66.8 | 49.6 |
| OpenAI-o4-mini | - | 37.1 | - | 60.1 | 43.1 |
| Open-Source Agents | |||||
| WebExplorer | 7B | 25.8 | 29.5 | 45.4 | 4.6 |
| DeepDive | 13B | 24.3 | - | - | 13.9 |
| WebDancer | 13B | 18.2 | 19.3 | 47.7 | 2.5 |
| DeepDiver-V2 | 22B | 31.8 | - | - | 19.0 |
| Kimi-K2-Instruct | 32B | 30.0 | - | 60.0 | 20.0 |
| MiroThinker-70B | 70B | 32.7 | 34.0 | 54.9 | 15.6 |
| GLM-4.5-355B-A32B | 355B | 33.3 | 36.0 | 62.7 | 45.4 |
| DeepSeek-V3.1-671B-A37B | 671B | 30.0 | 34.0 | 52.3 | 61.3 |
| AgentFold-30B-A3B (this paper) | 30B | 37.6 | 39.0 | 67.0 | 43.1 |
The results in the table above show that AgentFold-30B-A3B establishes a new SOTA for open-source agents and demonstrates strong competitiveness with top proprietary systems.
- Surpassing larger models: On the BrowseComp dataset, AgentFold (37.6%) significantly outperforms DeepSeek-V3.1-671B (30.0%), which is more than 20 times larger, proving that an advanced context management architecture can bridge a huge gap in model scale.
- Top-tier performance: On the WideSearch benchmark, AgentFold achieved the highest score of 67.0%, surpassing all proprietary agents, including OpenAI-o3 and Claude-4-Sonnet.
Context Efficiency Analysis
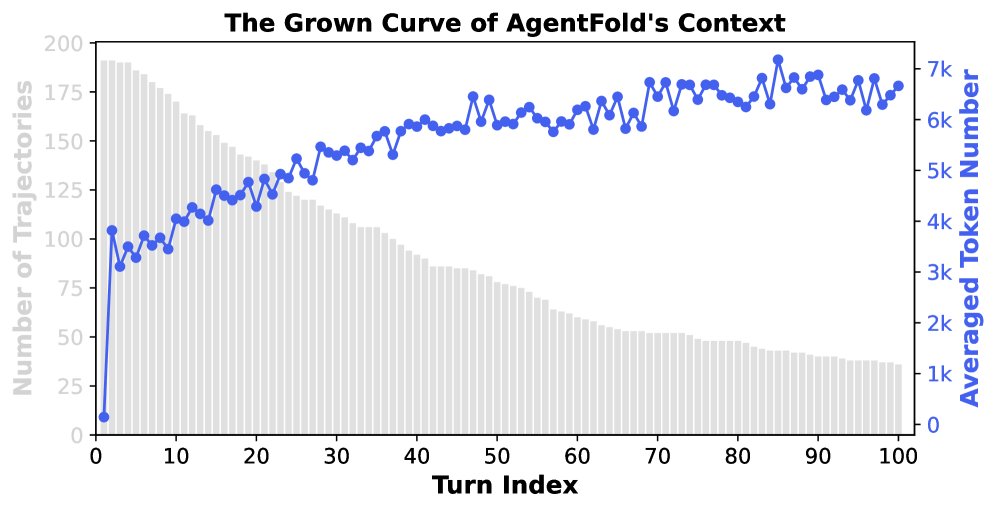
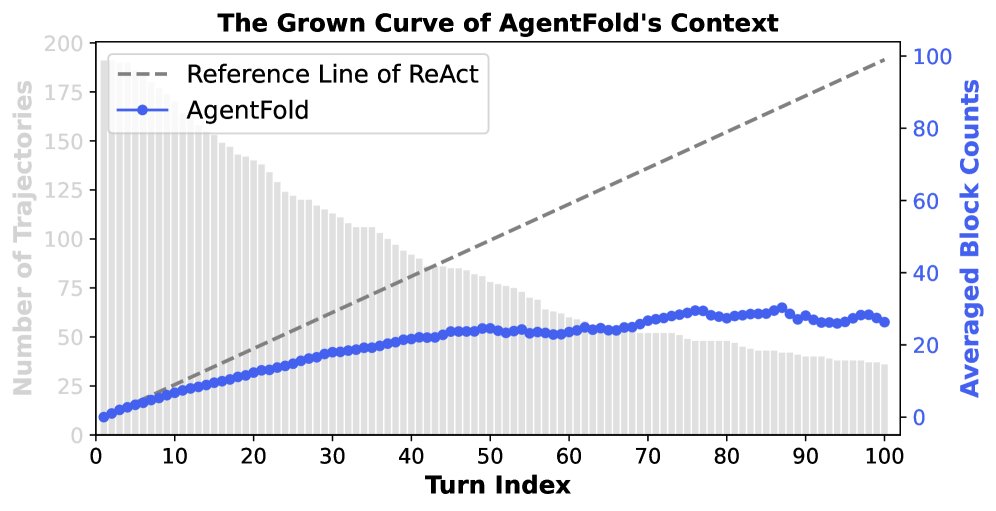
An analysis of trajectories on the BrowseComp benchmark further validates AgentFold’s context management efficiency.
- Extremely compact context (left figure): AgentFold’s context length grows at a very slow sublinear rate. After 100 rounds of interaction, the average token count increases from about 3.5k to 7k, far from reaching the model’s 128k context window limit. This proves the effectiveness of the “folding” operation in preventing context bloat. In the experiment, more than 20% of tasks were forcibly terminated upon reaching the 100-step limit, while the context at that point occupied only a tiny fraction, indicating that AgentFold has great potential for handling longer and more complex tasks.
- Simple structure (right figure): Compared with ReAct, whose number of context blocks grows linearly with the number of steps, AgentFold’s block count also grows sublinearly. This is thanks to the deep integration operation, which merges multiple historical steps into a single summary, keeping the context structurally concise and cognitively manageable.
Final Conclusion
The experimental results strongly demonstrate the effectiveness of the AgentFold paradigm. By introducing an active, intelligent context folding mechanism, AgentFold successfully solves the context management challenges in long-horizon tasks. It not only achieves SOTA performance on multiple key benchmarks, but more importantly, it shows that through elegant architectural design, smaller models can also match or even surpass models far larger than themselves, opening up a new path for the development of efficient and powerful AI intelligent agents.