Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents
-
ArXiv URL: http://arxiv.org/abs/2510.24702v1
-
Authors: Tianbao Xie; Tao Yu; Zhihao Yuan; Xiang Yue; Graham Neubig; Xingyao Wang; Shuyan Zhou; Huan Sun; Tianyue Ou; Ziru Chen; and 19 others
-
Publishing Organizations: All Hands AI; Carnegie Mellon University; Duke University; Fujitsu; The Ohio State University; University of Hong Kong
TL;DR
This paper proposes a lightweight representation language called the Agent Data Protocol (ADP), which addresses data fragmentation by unifying training data for agents from different sources and with different formats into a standard schema, thereby enabling large-scale, diverse, and efficient supervised fine-tuning of large language model agents.
Key Definitions
The core contribution of this paper is a protocol and architecture for unifying agent data. The key definitions are as follows:
-
Agent Data Protocol (ADP): A lightweight representation language and data schema designed to serve as an “intermediate language” between heterogeneous agent datasets and downstream unified training pipelines. It solves data format inconsistency by providing a standardized structure for representing agent interaction trajectories.
-
Trajectory: The basic unit in ADP for representing a complete agent interaction. A \(Trajectory\) object contains the core sequence of the interaction, namely a series of alternating \(Action\) and \(Observation\) entries.
- Action: Represents the decisions and behaviors an agent makes in the environment. ADP divides it into three categories:
- API Action: Used to represent function calls to tools or APIs, such as web browsing \(click(element_id)\).
- Code Action: Used to represent code generation and execution, supporting multiple programming languages.
- Message Action: Used to represent natural language communication between the agent and the user.
- Observation: Represents the perceptual information and feedback the agent receives from the environment (or the user). ADP divides it into two categories:
- Text Observation: Captures textual information from user instructions or environment feedback, such as code execution results.
- Web Observation: Specifically used to represent the state and content of web pages, including HTML, accessibility trees, URLs, and more.
Related Work
At present, agent research based on large language models (LLMs) relies on high-quality training data that must capture the complexity of multi-step reasoning, tool use, and environment interaction. Data collection methods are diverse, including manual creation, synthetic generation, and recording agent deployment trajectories. These methods have produced a large number of datasets covering tasks such as coding, software engineering, tool use, and web browsing.
However, despite the abundance of data sources, supervised fine-tuning (SFT) for large language model agents remains rare in academic research. The key bottleneck is data fragmentation:
- Inconsistent formats: Most existing agent training datasets use custom representation formats, action spaces, and observation structures, making them incompatible with one another.
- High integration cost: If researchers want to combine multiple datasets for training, they need to write dataset-specific data conversion scripts for each dataset and each agent framework, which is extremely labor-intensive and hard to maintain.
- Lack of systematic analysis: The chaos in data formats makes cross-dataset quantitative analysis and comparison exceptionally difficult, hindering a deep understanding of data quality and coverage.
This paper aims to solve the above problems of data fragmentation and lack of standardization by proposing a unified data protocol that breaks down the barriers between different datasets and training frameworks.
Method
To address data fragmentation, this paper proposes the Agent Data Protocol (ADP), a standard schema designed to unify heterogeneous agent training data.
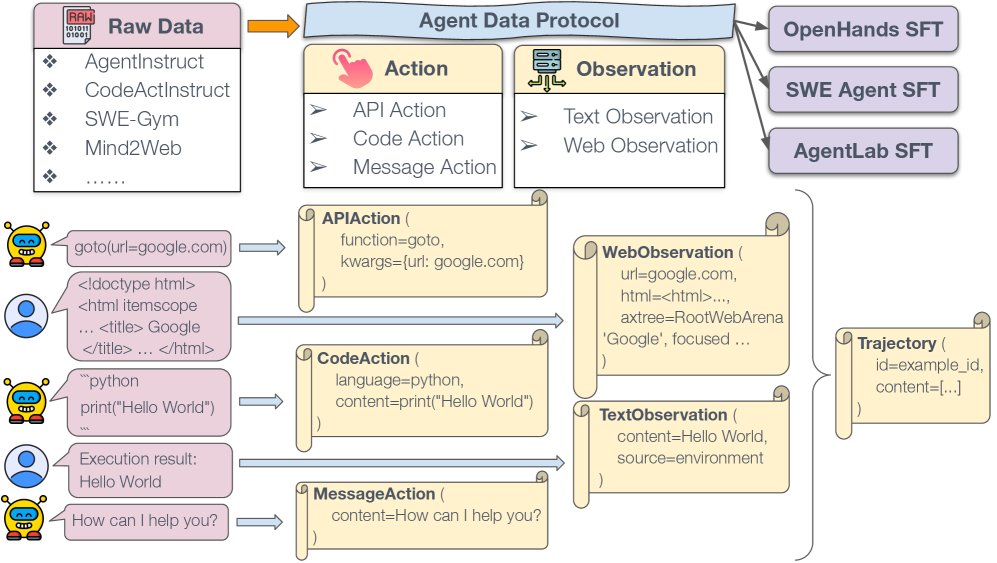 ADP overview. Raw data from different sources such as AgentInstruct, CodeActInstruct, SWE-Gym, and Mind2Web are converted into the standardized ADP format. ADP unifies the data into \(Trajectory\) objects, which include two core components: actions (API actions, code actions, message actions) and observations (text observations, web observations). This standardized representation enables seamless integration with various agent SFT pipelines.
ADP overview. Raw data from different sources such as AgentInstruct, CodeActInstruct, SWE-Gym, and Mind2Web are converted into the standardized ADP format. ADP unifies the data into \(Trajectory\) objects, which include two core components: actions (API actions, code actions, message actions) and observations (text observations, web observations). This standardized representation enables seamless integration with various agent SFT pipelines.
Design Principles
ADP follows three core design principles:
- Simplicity: ADP adopts a simple and intuitive structure, eliminating the need for dataset-specific engineering and lowering the barrier to large-scale data utilization.
- Universality: ADP provides a unified representation method that can standardize existing agent datasets in various formats, solving the problem of fragmented data formats.
- Expressiveness: ADP is designed to accurately represent complex agent interaction trajectories without losing key information, allowing it to cover tasks across domains such as coding, browsing, and tool use.
Architecture
The core of ADP is to abstract the agent interaction process into a \(Trajectory\) object, which consists of an alternating sequence of Action and Observation entries.
- Actions are further divided into three types:
- \(APIAction\): Captures tool use, such as \(click("button_id")\).
- \(CodeAction\): Handles code generation and execution, such as running a piece of Python code.
- \(MessageAction\): Records natural language conversations with the user.
- Observations are further divided into two types:
- \(TextObservation\): Records textual feedback from the user or environment, such as code execution output.
- \(WebObservation\): Specifically for web tasks, capturing rich information such as page HTML, accessibility trees, and URLs.
This “action-observation” abstraction is the core insight of ADP. It captures the essence of agent interaction: taking actions in the environment and receiving feedback. By standardizing these basic units, ADP can integrate originally incompatible datasets while preserving the rich semantics of the original data.
Conversion Pipeline
To put ADP into practice, the paper designs a three-stage conversion pipeline:
- Raw Data to ADP (Raw→ADP): This stage converts various heterogeneous raw datasets into a unified ADP format. Developers only need to write one conversion script for each new dataset, mapping its specific actions and observations into ADP’s standard space.
- ADP to SFT Format (ADP→SFT): This stage converts standardized ADP trajectory data into the supervised fine-tuning (SFT) format required by a specific agent framework. Different agent frameworks, such as OpenHands and SWE-Agent, require different training data formats because of differences in architecture and tool interfaces. Developers only need to write an ADP-to-SFT conversion script for their own agent framework.
- Validation: Automated checks are used to ensure data correctness and consistency, such as verifying tool-call formats and dialogue structure, thereby ensuring high-quality training data.
Innovation
The most important innovation of ADP is the introduction of an “intermediate language,” which greatly reduces the engineering complexity of data integration.
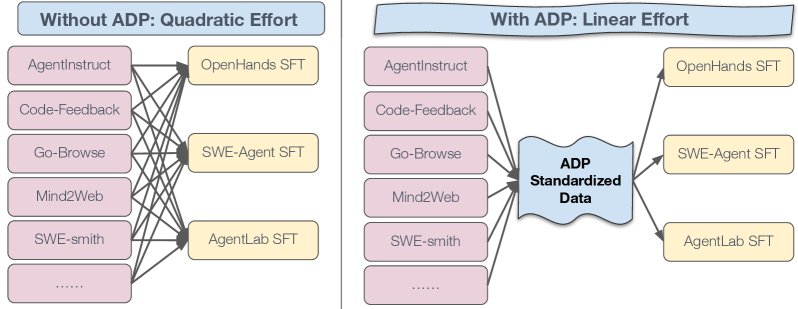
- Left figure (without ADP): Without ADP, for \(D\) datasets and \(A\) intelligent agent frameworks, researchers need to write \(D * A\) separate conversion scripts, making the engineering effort quadratic \(O(D×A)\).
- Right figure (with ADP): With ADP, each dataset only needs one Raw→ADP converter, and each intelligent agent framework only needs one ADP→SFT converter. The total engineering effort is reduced to linear \(O(D+A)\).
This shift allows new datasets to be used immediately by all community intelligent agent frameworks that support ADP, while new intelligent agent frameworks can also instantly leverage all data already converted into ADP format. This pattern amortizes the cost of data conversion and accelerates the research iteration speed of the entire community.
Experimental Conclusions
Through experiments on multiple benchmarks, this paper validates the effectiveness of ADP in improving intelligent agent model performance and simplifying the development workflow.
Cross-dataset Analysis
By converting 13 different datasets into ADP format, this paper conducted a unified quantitative analysis, revealing the characteristics of data from different task domains.
| Dataset | Average Turns | Action Distribution (API/Code/Message %) | Thought Coverage (%) |
|---|---|---|---|
| AgentInstruct | 8.2 | 64/10/26 | 100.0 |
| Code-Feedback | 4.0 | 0/58/42 | 82.8 |
| CodeActInstruct | 4.0 | 0/65/35 | 98.6 |
| Go-Browse | 3.9 | 70/0/30 | 100.0 |
| Mind2Web | 9.7 | 90/0/10 | 0.0 |
| Nebius SWE-Agent… | 16.2 | 67/27/6 | 100.0 |
| NNetNav | 8.2 | 80/0/20 | 99.9 |
| openhands-feedback | 10.1 | 89/0/11 | 99.9 |
| Orca AgentInstruct | 18.3 | 11/73/16 | 91.7 |
| SWE-Gym | 1.3 | 0/15/85 | 84.0 |
| SWE-smith | 19.7 | 61/25/14 | 42.0 |
| Synatra | 26.8 | 56/40/4 | 90.1 |
| WebArena | 1.0 | 100/0/0 | 99.9 |
The analysis shows:
- Large differences in interaction length: Software engineering (SWE) tasks have significantly longer interaction turns.
- Action distribution is domain-dependent: Web browsing datasets rely heavily on API actions, while coding datasets are dominated by code actions.
- “Thinking” processes are common: Most datasets include the intelligent agent’s explanation of its behavior (Thought Coverage), which is crucial for training interpretable models.
ADP Data Significantly Improves Intelligent Agent Performance
The experimental results show that training on datasets unified with ADP can greatly improve model performance across multiple domains, with an average gain of about 20%.
| SOTA vs. This Paper’s 7-8B Models | SWE-Bench Verified | WebArena | AgentBench | GAIA |
|---|---|---|---|---|
| SOTA (other models) | Claude 3.5 Sonnet: 33.6 | GPT-4o: 18.6 | GPT-4o: 24.1 | GPT-4o: 30.1 |
| This paper’s ADP-trained models | Qwen2.5-7B (OH): 20.4 | Qwen2.5-7B (AL): 21.0 | Qwen3-8B (OH): 27.1 | Qwen2.5-7B (OH): 9.1 |
| SOTA vs. This Paper’s 13-14B Models | SWE-Bench Verified | WebArena | AgentBench | GAIA |
|---|---|---|---|---|
| SOTA (other models) | Claude 3.5 Sonnet: 33.6 | GPT-4o: 18.6 | GPT-4o: 24.1 | GPT-4o: 30.1 |
| This paper’s ADP-trained models | Qwen3-14B (SA): 34.4 | Qwen3-14B (AL): 22.2 | Qwen3-14B (OH): 20.8 | - |
| SOTA vs. This Paper’s 32B Models | SWE-Bench Verified | WebArena | AgentBench | GAIA |
|---|---|---|---|---|
| SOTA (other models) | Claude 3.5 Sonnet: 33.6 | GPT-4o: 18.6 | GPT-4o: 24.1 | GPT-4o: 30.1 |
| This paper’s ADP-trained models | Qwen3-32B (SA): 40.3 | Qwen3-32B (AL): 22.9 | Qwen3-32B (OH): 34.7 | - |
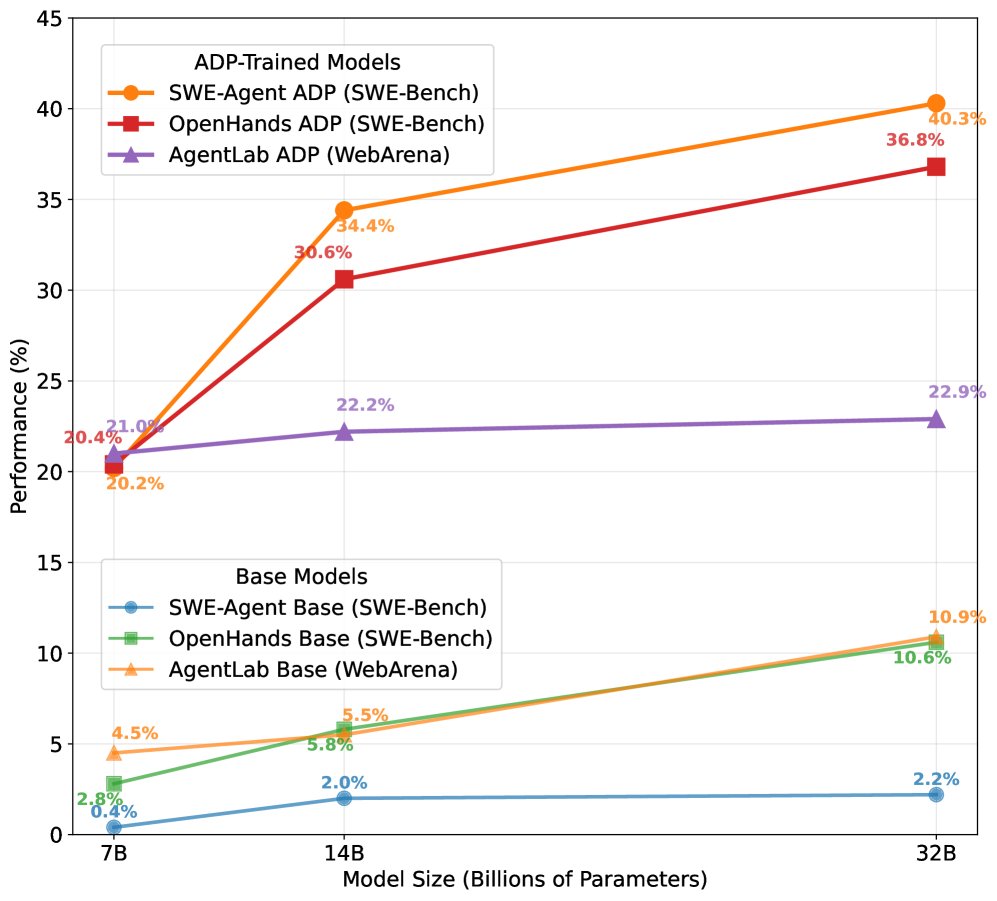
- On SWE-Bench (software engineering), 7B model performance jumped from 0.4% to 20.2%, and the 32B model reached 40.3%, surpassing Claude 3.5 Sonnet.
- On WebArena (web browsing) and AgentBench (general tools), models of all sizes achieved stable and significant performance gains.
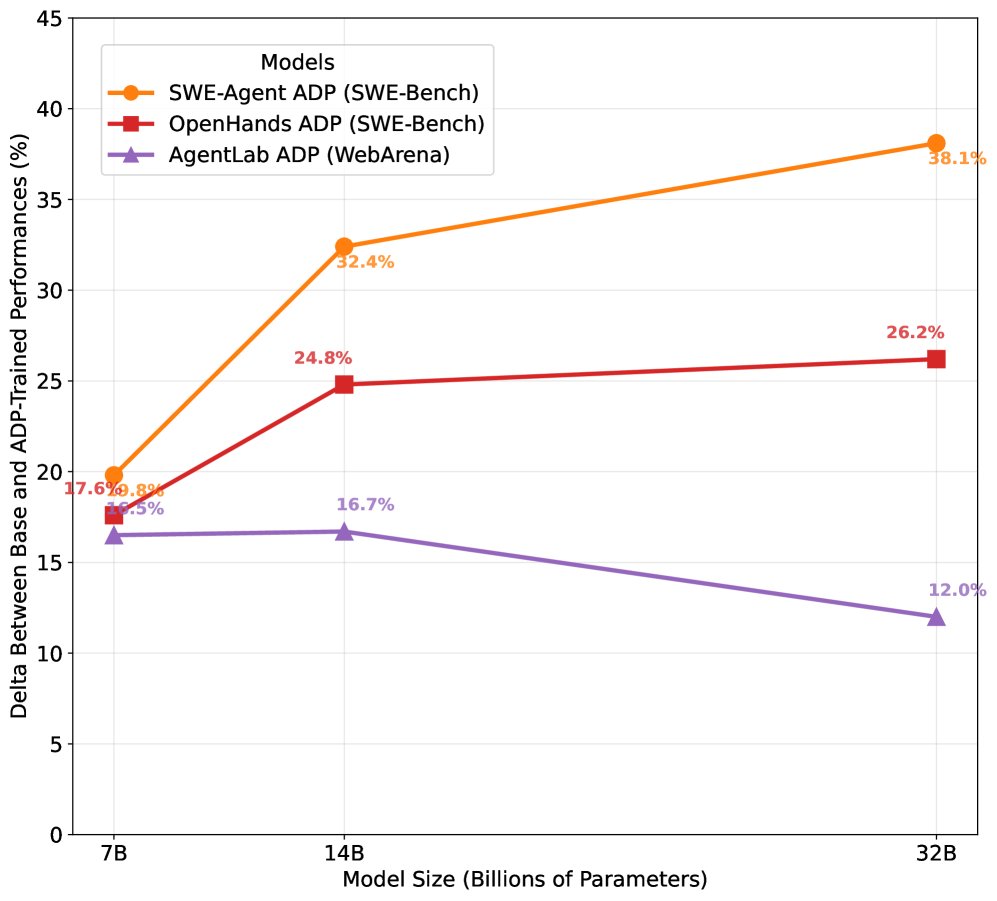
- As model scale increases (from 7B to 32B), the performance gains brought by ADP persist, demonstrating the method’s generality and scalability.
Diverse Data Brings Cross-task Transfer Ability
Experiments show that training with ADP datasets mixed from multiple domains performs better than using a single dataset from a specific domain.
| Benchmark | Intelligent Agent Framework | Training with Only Domain-specific Data | Training with Mixed ADP Data |
|---|---|---|---|
| SWE-Bench | SWE-Agent | 1.0% | 10.4% |
| SWE-Bench | OpenHands | 11.0% | 13.2% |
| WebArena | AgentLab | 16.0% | 18.7% |
| AgentBench | OpenHands | 21.5% | 24.5% |
| GAIA | AgentLab | 0.6% | 2.5% |
For example, on the SWE-Bench task, the model trained with mixed ADP data achieved 10.4% accuracy, far higher than the 1.0% achieved by training only on the SWE-smith dataset. This shows that data diversity promotes the model’s cross-task generalization ability.
ADP Simplifies Adaptation to New Intelligent Agent Frameworks
ADP reduces the engineering effort for data adaptation from \(O(D×A)\) to \(O(D+A)\). This article quantifies the improvement using lines of code (LOC):
- Raw→ADP: Converting 13 datasets into the ADP format requires about 4,892 lines of code in total.
- ADP→SFT: Converting ADP data into the formats of 3 different intelligent agent frameworks requires only about 77 lines of code per framework on average.
| Intelligent Agent Framework | Total LOC |
|---|---|
| OpenHands CodeActAgent | ~150 |
| SWE-Agent | ~50 |
| AgentLab | ~30 |
| Average | ~77 |
Without ADP, supporting 100 intelligent agent frameworks would require the community to invest about \(4892 * 100 = 489,200\) LOC in total. With ADP, the total effort is about \(4892 + 77 * 100 = 12,592\) LOC, reducing duplicate work by more than 97%. This greatly lowers the barrier for new intelligent agent frameworks to integrate into the existing data ecosystem.
Conclusion
By establishing a unified data “intermediate language,” ADP successfully integrates a fragmented intelligent agent data ecosystem into a scalable training pipeline. Experiments show that this approach not only significantly improves model performance across multiple domains such as coding, browsing, and tool use, but also enhances generalization by promoting data diversity, while substantially reducing community development and maintenance costs.
Future work includes extending ADP to multimodal data, unifying evaluation and environment setup, and continuing open-source collaboration to catalyze the next wave of development in intelligent agent training.