A Survey on LLM Mid-training
-
ArXiv URL: http://arxiv.org/abs/2510.23081v1
-
Authors: Yang Bai; Xuemiao Zhang; Rongxiang Weng; Hongfei Yan; Rumei Li; Chen Zhang; Xunliang Cai; Jingang Wang
-
Publishing Organization: Meituan; Peking University
A Survey of Mid-Training in LLMs
Overview
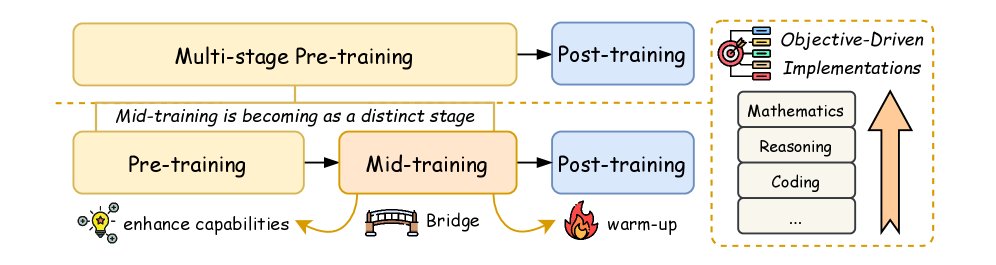
The development of contemporary large language models (LLMs) has evolved from a single pre-training paradigm into a complex multi-stage optimization framework. Pre-training lays the foundation for model capabilities by exposing the model to large-scale, diverse corpora, while subsequent optimization stages systematically enhance specific abilities. Mid-training serves as a key bridge connecting pre-training and post-training, and its importance has become increasingly prominent.
Mid-training is characterized by the use of moderate computational resources and large-scale data with clear objectives. It exposes the model to domain-specific data in a curriculum-guided manner, forwarding specialized capabilities; at the same time, by retaining a certain proportion of general data, it preserves foundational general abilities. Empirical evidence shows that, compared with pre-training, mid-training can deliver more significant performance gains with less data and computation.
This article formally defines mid-training as a distinct stage of model development that retains the next-token prediction objective of pre-training, but systematically improves specific skills through carefully curated data mixtures, typically including high-quality domain data and instruction data. This differs from continued pre-training, which usually does not consider optimizer state or distribution preservation and may lead to a loss of general capabilities. Mid-training, by contrast, is a deliberate design stage with transitional intent.
Mid-training coordinates three major capability areas:
- Core cognitive skills: such as mathematics and reasoning.
- Task execution: such as instruction following, coding, and Agent behavior.
- Scalability: such as long-context processing and multilingual capabilities.
The figure below shows where mid-training sits in the overall landscape of LLM development.
Data Curation
The data used in mid-training is typically a mixture of general high-quality corpora and specially formatted data, such as QA pairs, instruction data, and domain data in mathematics and code. This section will examine the end-to-end workflow of data curation in detail, including data collection, synthesis, selection, decontamination, and mixing; as shown in the figure below, the order of these steps can be adjusted as needed.
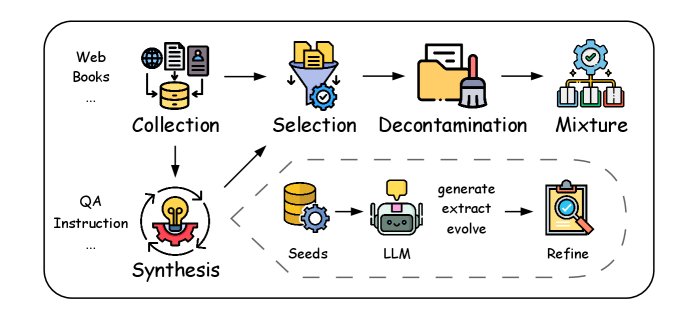
Data Collection
The data sources for mid-training are similar to those for pre-training, including web-crawled corpora, digitized books, and human-annotated materials. Commonly used web-crawling tools include Trafilatura, and widely used datasets include CommonCrawl, Wikipedia, C4, and Pile. In addition, mid-training also collects specially formatted data, such as QA pair datasets like Stack Exchange QA, RedStone, and MegaMath. All collected data undergoes initial cleaning and quality filtering to ensure integrity and reliability.
Data Synthesis
Data synthesis improves the information density and overall quality of data by reconstructing, transforming, or generating scarce data types, such as Agent data, effectively addressing issues like data scarcity and insufficient diversity. Given the scale of mid-training data, the mainstream synthesis methods are currently all LLM-driven and can be divided into three categories:
- Distillation: Use powerful LLMs to directly generate data through carefully designed prompts, or distill smaller synthesis models. This method depends heavily on the capabilities of the LLM and is often followed by strict quality filtering. Specific techniques include:
- Style rewriting: Transform low-quality, noisy corpora into more information-dense expressions.
- Diffusion synthesis in specific formats: Design specific prompts to generate massive QA pairs or instruction data from corpora.
- Translation for low-resource languages and multimodal synthesis.
-
Extraction: Use LLMs to directly extract natural QA pairs or other formatted data from collected corpora, followed by further refinement. For example, WebInstruct obtains high-quality QA pairs from web content through a “recall-extract-refine” pipeline.
- Evolution: Generate enhanced versions of questions and solutions through a designed iterative loop, especially suitable for mathematics. For example, MathGenie augments solution strategies from seed data and then back-translates them into new math problems, thereby creating diverse and reliable synthetic data.
Data Selection
Data selection is the process of filtering high-quality or domain-specific samples from raw data during mid-training, with finer granularity than in pre-training. There are two main methods:
- Targeted sampling: Adjust the data distribution by downsampling less relevant domains or upsampling domain-specific content.
- Rater-based filtering: Use specialized scoring models (Rater) to evaluate data quality. Common raters include FastText classifiers, FineWeb-Edu classifiers, and QuRater evaluation models.
The current bottleneck is how to efficiently filter pre-training data into a high-quality general dataset, which usually requires the coordinated combination of multiple raters for careful selection.
Data Decontamination
Data decontamination is a key preprocessing step for foundation models, aiming to remove meaningless, sensitive, or benchmark-related content from training corpora to reduce data leakage risks and ensure fair evaluation. The main challenge is balancing data removal with model performance retention, because existing methods all suffer from false positives (over-filtering that degrades generalization) and false negatives (incomplete decontamination that inflates benchmark scores).
The most mainstream implementation method at present is N-gram matching, because it is simple and scalable. However, it cannot capture semantic equivalence under lexical variation. Embedding-based methods (such as cosine similarity) are more semantically sensitive, but computationally expensive. Hybrid methods (such as N-gram combined with longest common subsequence) show improved results, but lack universality.
Data Mixing
Mid-training enhances specific capabilities by strategically mixing different forms of data. The data composition is usually a blend of high-quality general corpora and special-format data, with the proportions tailored to specific goals.
High-quality general corpora are usually selected from pre-training data and are used to maintain the model’s foundational language robustness and reduce the risk of distribution shift.
Special-format data mainly includes:
- QA data: Characterized by being knowledge-intensive or reasoning-driven, it is good at building explicit knowledge representations and enhancing few-shot adaptability. Different types of QA data can target different capabilities; for example, short CoT QA strengthens factual knowledge, while long CoT QA cultivates iterative reasoning ability.
- Instruction data: Structurally similar to the instruction fine-tuning data used in the post-training stage. Studies show that adding a small amount of instruction data (e.g., 1%) during mid-training can significantly reduce the amount of instruction fine-tuning required in the SFT stage and improve RL performance.
- Long-context data: Usually sourced from books, Wikipedia, and high-quality papers, and enhanced through upsampling or synthesis to improve the model’s ability to handle long sequences.
The main ways to determine the optimal mixing ratio are:
- Empirical allocation: For example, Llama-3 assigns a 30% weight to the new dataset.
- Proxy experiment inference: OLMo 2 uses microanneals (reduced annealing runs on small data subsets) to infer the effects of large-scale mixtures from small-scale trials. RegMix treats ratio optimization as a regression task, predicting the performance of unknown mixtures by training many small models on various mixing configurations. These methods rely on the stability hypothesis, namely that the performance ranking of data-mixing ratios remains consistent across different model scales and token counts.
Training Strategy
The training strategy for mid-training mainly focuses on learning rate (LR) scheduling, while other hyperparameter settings also have a significant impact on the results.
Learning Rate Scheduling
Learning rate scheduling is crucial to training stability, efficiency, and final performance. A typical learning rate schedule includes a warm-up phase and a decay phase. The warm-up phase usually uses linear warm-up, which improves training stability. The decay phase can use strategies such as linear, cosine, or exponential decay.
It is worth noting that the decay phase is often divided into a slow-decay period and a fast-decay period, and high-quality data is usually introduced during the fast-decay period. In addition, multi-stage schedulers such as Warmup-Stable-Decay (WSD) introduce a stable high-learning-rate training stage that helps the model explore the parameter space, thereby improving optimization efficiency and generalization performance, and have become a widely adopted practice today.
Comparison of different learning rate schedulers.
| Stage | Scheduler Type | Formula |
|---|---|---|
| Warm-up | Linear | \(\eta=\frac{s}{W}{\eta}_{\max},\quad 0\leq s\leq W\) |
| Stable | - | \(\eta=\eta,\quad 0\leq s\leq T\) |
| Decay | Linear | \(\eta={\eta}_{\max}-({\eta}_{\max}-{\eta}_{\min})\cdot\frac{s}{S},\quad 0\leq s\leq S\) |
| Cosine | \(\eta={\eta}_{\min}+\frac{1}{2}({\eta}_{\max}-{\eta}_{\min})(1+\cos(\pi\frac{s}{S})),\quad 0\leq s\leq S\) | |
| Exponential | \(\eta={\eta}_{\max}\cdot e^{-ks}\) | |
| Multi-stage | WSD | \(WSD(T;s)=\begin{cases}\frac{s}{W}\eta, & s<W \\ \eta, & W<s<T \\ f(s-T)\eta, & T<s<S \end{cases}\) |
Other Training Settings
The key hyperparameter configured together with the learning rate schedule is mainly batch size. Increasing the batch size reduces the variance of the stochastic gradient estimate, thereby allowing a higher learning rate during training. In the annealing stage, the batch size is usually constrained by the data scale and may be adjusted dynamically.
Model Architecture Optimization
Long Context Extension
Rotary Position Embedding (RoPE) has become the standard positional encoding method for LLMs. However, LLMs pretrained on a fixed context length suffer performance degradation when handling longer sequences, so RoPE-based long-context extension methods are needed.
RoPE encodes token position information through a rotation tensor. Given a hidden vector $h=[h_{0},h_{1},…,h_{d-1}]$ and a position index $m$, the RoPE operation is as follows:
\[f(h, m) = [..., h_{2i} \cos(m\theta_i) - h_{2i+1} \sin(m\theta_i), h_{2i} \sin(m\theta_i) + h_{2i+1} \cos(m\theta_i), ...]\]where $\theta_{j}=b^{-2j/d}, j\in{0,1,…,d/2-1}$.
Common RoPE extension variants include:
Position Interpolation (PI)
The PI method scales the position index $m$ down to $m/\alpha$, thereby interpolating the original position range into a longer context window.
NTK-aware Interpolation (NTK)
NTK argues that PI may cause high-frequency information loss by interpolating all dimensions equally. Therefore, NTK introduces a nonlinear interpolation strategy by adjusting the base frequency $b$.
Yet another RoPE extensioN (YaRN)
YaRN uses a ramp function to combine PI and NTK at different ratios across dimensions. In addition, it introduces a temperature factor $t=\sqrt{1+\ln(s)/d}$ to mitigate the attention distribution shift caused by long inputs.
YaRN currently represents the best balance between performance and efficiency in production systems.
Decay Scaling Laws
Unlike pretraining scaling laws, Decay Scaling Laws take into account the unique starting point of the decay stage, providing a tailored approach for predicting key variables that affect training efficiency. These laws mainly focus on predicting the following variables: model size, data ratio (general vs. specialized), and the number of training tokens. The law provides a structured framework for understanding the interactions among factors in the decay stage and their impact on model performance, but further research is still needed to refine it.
Evaluation
Model evaluation during intermediate training follows established standardized benchmarks, as shown in the table below. The evaluation framework covers multiple domains, including general, math, coding, intelligent agent, and long context, and is strategically aligned with the intermediate training objectives detailed below.
Benchmarks for intermediate training.
| Domain | Capability | Benchmarks |
|---|---|---|
| General | Knowledge | MMLU, TriviaQA, NaturalQuestions |
| Reasoning | ARC, HellaSwag, WinoGrande, BIG-Bench Hard | |
| Math | Reasoning | GSM8K, MATH |
| Coding | Code generation | HumanEval, MBPP |
| Code completion | HumanEval | |
| Code repair | HumanEval-Fix, Code-Fix | |
| Code reasoning | HumanEval-NL, Code-Reasoning | |
| Intelligent agent | Tool use | ToolBench, AgentBench |
| Long context | Reasoning | NarrativeQA, QuALITY, ScrollS |
Goal-Driven Implementation
Goal-driven implementation is the methodological cornerstone of intermediate training. These capability-enhancement objectives can be systematically divided into four interrelated domains: general capabilities, core cognitive capabilities, task execution capabilities, and extended capabilities. This section breaks down how these objectives are implemented and analyzes how mainstream models leverage customized data curation, training strategies, and architecture optimization to achieve them.
Intermediate training objectives mentioned in mainstream models.
| Model | Objectives |
|---|---|
| Phi-3.5 | General, multilingual, long context |
| Phi-4 | General, math, coding |
| Llama-3 | General, reasoning |
| OLMo 2 | General, coding |
| Yi-Lightning | General, coding |
| … | … |
General Capabilities
Maintaining and enhancing a model’s general understanding and generation capabilities during intermediate training is a key optimization direction. This requires carefully designed interventions to mitigate catastrophic forgetting while improving the model’s specific capabilities. As shown in the table above, all mainstream models have extensively studied how to preserve general performance while improving other objectives.
Empirical analysis shows that retaining a carefully curated subset of pretraining data is crucial. By optimizing the data composition and balancing the proportions, downstream task performance and generalization robustness can be significantly improved.