A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly
-
ArXiv URL: http://arxiv.org/abs/2312.02003v3
-
Author: Yue Zhang; Eric Sun; Yifan Yao; Yuanfang Cai; Kaidi Xu; Jinhao Duan
-
Publisher: Drexel University
A Survey of Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly
Introduction
Large Language Model (LLM) is a language model with massive parameters that understands and processes human language through pretraining tasks such as masked language modeling and autoregressive prediction. A powerful LLM should have four key characteristics: deep understanding of natural language context, the ability to generate human-like text, context awareness, especially in knowledge-intensive domains, and strong instruction-following ability.
LLMs have also attracted widespread attention in the security community. For example, GPT-3 discovered 213 security vulnerabilities in a codebase. These early efforts prompted this paper to explore three core research questions about LLM security and privacy:
- RQ1 (Good): How can LLMs positively impact security and privacy across different domains?
- RQ2 (Bad): What potential risks and threats arise from using LLMs in cybersecurity?
- RQ3 (Ugly): What vulnerabilities and weaknesses do LLMs themselves have, and how can these threats be defended against?
To answer these questions, this paper reviews 281 related papers and categorizes them into three groups: “good” (beneficial applications), “bad” (offensive applications), and “ugly” (LLM vulnerabilities and defenses).
Findings of this paper:
- Good (§4): LLMs have the greatest positive impact on the security community, especially in code security and data security and privacy. Across the full lifecycle of code (secure coding, testing, detection, and repair), LLM applications generally outperform traditional methods.
- Bad (§5): LLMs can also be used for attacks, especially at the user level, such as generating misinformation and carrying out social engineering. This is due to their human-like reasoning ability.
- Ugly (§6): LLM vulnerabilities are divided into AI-model-inherent vulnerabilities (such as data poisoning) and non-AI-model-inherent vulnerabilities (such as prompt injection). Defense strategies can be implemented at the model architecture, training, and inference stages. Research on attacks such as model extraction and parameter extraction remains very limited, while emerging defense techniques such as security instruction fine-tuning require further exploration.
Contributions of this paper: This paper is the first to provide a comprehensive summary of the role of LLMs in security and privacy, covering their positive impact, potential risks, inherent vulnerabilities, and defense mechanisms. The paper finds that LLMs contribute more to the security field than they harm it, and points out that user-level attacks are currently the most significant threat.
Background
Large Language Models (LLM)
LLMs are the evolution of language models, whose scale increased significantly after the emergence of the Transformer architecture. These models are trained on massive datasets to understand and generate text that closely mimics human language. A qualified LLM should have four key characteristics:
- Deep understanding of natural language: able to extract information from it and perform tasks such as translation.
- Human-like text generation: able to complete sentences, write paragraphs, and even articles.
- Context awareness: possess domain expertise, i.e., the “knowledge-intensive” property.
- Strong problem-solving ability: able to use textual information for information retrieval and question answering.
Comparison of Popular LLMs
The table below shows a variety of language models from different vendors, illustrating the rapid development of this field. Newer models such as GPT-4 continue to emerge. Although most models are not open source, the open-sourcing of models such as BERT and LLaMA has promoted community development. In general, the more parameters a model has, the stronger its capabilities, but the higher its computational requirements. “Tunability” refers to whether the model can be fine-tuned for specific tasks.
| Model | Date | Provider | Open Source | Parameters | Tunable |
|---|---|---|---|---|---|
| gpt-4 | 2023.03 | OpenAI | ✗ | 1.7T | ✗ |
| gpt-3.5-turbo | 2021.09 | OpenAI | ✗ | 175B | ✗ |
| gpt-3 | 2020.06 | OpenAI | ✗ | 175B | ✗ |
| cohere-medium | 2022.07 | Cohere | ✗ | 6B | ✓ |
| cohere-large | 2022.07 | Cohere | ✗ | 13B | ✓ |
| cohere-xlarge | 2022.06 | Cohere | ✗ | 52B | ✓ |
| BERT | 2018.08 | ✓ | 340M | ✓ | |
| T5 | 2019 | ✓ | 11B | ✓ | |
| PaLM | 2022.04 | ✓ | 540B | ✓ | |
| LLaMA | 2023.02 | Meta AI | ✓ | 65B | ✓ |
| CTRL | 2019 | Salesforce | ✓ | 1.6B | ✓ |
| Dolly 2.0 | 2023.04 | Databricks | ✓ | 12B | ✓ |
Overview
Scope
This paper aims to provide a comprehensive literature review of security and privacy research in the context of LLMs, identify the current state of the art, and pinpoint knowledge gaps. The focus of this paper is strictly limited to security and privacy issues.
Research Questions
This paper is organized around the following three core research questions:
- Good (§4): How can LLMs make positive contributions to security and privacy?
- Bad (§5): How can LLMs be used for malicious purposes, and what cyberattacks may they facilitate?
- Ugly (§6): What vulnerabilities do LLMs themselves have, and how do they threaten security and privacy?
This paper collected 281 related papers, including 83 in the “good” category, 54 in the “bad” category, and 144 in the “ugly” category. As shown in the figure below, most papers were published in 2023, indicating a rapid rise in research interest in this field.
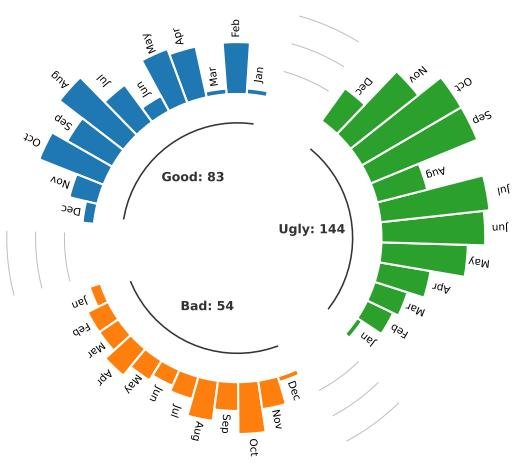
Finding I: In security-related applications, most researchers tend to use LLMs to enhance security, such as vulnerability detection, rather than as attack tools. Overall, LLMs contribute more positively than negatively to the security community.
Positive Impacts (Good)
This section discusses beneficial applications of LLMs in code security and data security and privacy.
Applications of LLMs in Code Security
With their strong language understanding and contextual analysis capabilities, LLMs can play a key role throughout the entire lifecycle of code security, including secure coding, test case generation, vulnerability/malicious code detection, and code repair.
| Lifecycle | Task | Coding (C) | Test Case Generation (TCG) | Vulnerability Detection | Malicious Code Detection | Repair | LLM | Domain | Advantages over SOTA |
|---|---|---|---|---|---|---|---|---|---|
| RE | Sandoval et al. [234] | ○ | Codex | - | Negligible risk | ||||
| RE | SVEN [98] | ○ | CodeGen | - | Faster/safer | ||||
| RE | SALLM [254] | ○ | ChatGPT et al. | - | – | ||||
| RE | Madhav et al. [197] | ○ | ChatGPT | Hardware | – | ||||
| RE | Zhang et al. [343] | + | ChatGPT | Supply chain | More effective cases | ||||
| RE | Libro [136] | + | LLaMA | - | ↑ Coverage | ||||
| RE | TitanFuzz [56] | + | Codex | DL libraries | ↑ Coverage | ||||
| RE | FuzzGPT [57] | + | ChatGPT | DL libraries | ↑ Coverage | ||||
| RE | Fuzz4All [313] | + | ChatGPT | Languages | High-quality tests | ||||
| RE | WhiteFox [321] | + | GPT4 | Compiler | 4x faster | ||||
| RE | Zhang et al. [337] | + | ChatGPT | API | ↑ Coverage, but high FP/FN | ||||
| RE | CHATAFL [190] | + | ChatGPT | Protocols | Low FP/FN, but FP/FN high | ||||
| RE | Henrik [105] | + | N/A | - | Not better than SOTA | ||||
| RE | Apiiro [74] | + | ChatGPT | - | Cost-effective | ||||
| RE | Noever [201] | + | ChatGPT | - | – | ||||
| RE | Bakhshandeh et al. [15] | + | ChatGPT | - | – | ||||
| RE | Moumita et al. [218] | + | ChatGPT | - | – | ||||
| RE | Cheshkov et al. [41] | + | GPT | - | Reduces manual effort | ||||
| RE | LATTE [174] | + | Codex | - | ↑ Accuracy/speed | ||||
| RE | DefectHunter [296] | + | ChatGPT | Blockchain | Fixes more vulnerabilities | ||||
| RE | Chen et al. [37] | + | ChatGPT | Blockchain | CI pipeline | ||||
| RE | Hu et al. [110] | + | LLaMa | Web applications | – | ||||
| RE | KARTAL [233] | + | Codex | Libraries | – | ||||
| RE | VulLibGen [38] | + | Codex | Hardware | Zero-shot | ||||
| RE | Ahmad et al. [3] | + | Codex et al. | APR | ↑ Accuracy | ||||
| RE | InferFix [125] | + | ChatGPT | APR | ↑ Accuracy | ||||
| RE | Pearce et al. [211] | + | + | ChatGPT et al. | APR | ↑ Accuracy | |||
| RE | Fu et al. [83] | + | ChatGPT | APR | – | ||||
| RE | Sobania et al. [257] | + | + | ||||||
| RE | Jiang et al. [123] | + |
- Secure Coding: Studies show that, with the assistance of LLMs (such as OpenAI Codex), the code written by developers does not introduce more security risks. Methods like SVEN guide LLMs to generate safer code through continuous prompting, significantly improving success rates.
- Test Case Generating: LLMs are used to generate security test cases. In scenarios such as supply chain attacks, fuzzing of deep learning libraries, and protocol fuzzing, the coverage and efficiency of the generated test cases exceed those of existing tools. For example, Fuzz4All improves average coverage across multiple languages by 36.8%.
- Vulnerable Code Detecting: LLMs such as GPT-4 perform well in detecting software vulnerabilities, finding far more vulnerabilities than traditional static analysis tools. However, some studies also point out that LLMs can produce relatively high false positive rates in certain scenarios. In specific domains such as smart contracts and Web applications, LLMs also demonstrate strong vulnerability detection capabilities.
- Malicious Code Detecting: Using the natural language processing capabilities of LLMs to detect malware is an emerging direction. Tools such as Apiiro identify malicious packages by representing code as vectors.
- Vulnerable/Buggy Code Fixing: LLMs show strong capabilities in program repair tasks. Even LLMs that have not been specifically trained for vulnerability repair can fix insecure code. ChatGPT performs comparably to standard program repair methods in fixing bugs, and frameworks such as ChatRepair further improve its code repair ability.
Finding II: Most studies (17 out of 25) believe that LLM-based methods outperform traditional methods in code security, with advantages such as higher code coverage, higher detection accuracy, and lower cost. The most commonly criticized issue with LLM methods is their tendency to produce relatively high false negatives and false positives when detecting vulnerabilities.
Applications of LLMs in Data Security and Privacy
LLMs have also contributed to data security, mainly in terms of data integrity, confidentiality, reliability, and traceability.
| Work | Features | Model | Domain | Advantage over SOTA |
|---|---|---|---|---|
| … | I C R T | |||
| Fang [294] | ○+○+ | ChatGPT | ransomware | - |
| Liu et al. [187] | ○+○+ | ChatGPT | ransomware | - |
| Amine et al. [73] | ○○○+ | ChatGPT | semantics | comparable to SOTA |
| HuntGPT [8] | ○○○+ | ChatGPT | network | more effective |
| Chris et al. [71] | ○○○+ | ChatGPT | logs | reduces manual effort |
| AnomalyGPT [91] | ○○○+ | ChatGPT | video | reduces manual effort |
| LogGPT [221] | ○○○+ | ChatGPT | logs | reduces manual effort |
| Arpita et al. [286] | +○++ | BERT etc. | - | - |
| Takashi et al. [142] | ++○+ | ChatGPT | phishing | high accuracy |
| Fredrik et al. [102] | ++○+ | ChatGPT etc. | phishing | effective |
| IPSDM [119] | ++○+ | BERT | phishing | - |
| Kwon et al. [149] | +○++ | ChatGPT | - | friendly to non-experts |
| Scanlon et al. [237] | +++○ | ChatGPT | forensics | more effective |
| Sladić et al. [255] | +++○ | ChatGPT | honeypot | more realistic |
| WASA [297] | ++○○ | - | watermarking | more effective |
| REMARK [340] | ++○○ | - | watermarking | more effective |
| SWEET [154] | ++○○ | - | watermarking | more effective |
- Data Integrity (I): Ensures that data is not tampered with throughout its lifecycle. LLMs have been used to theoretically propose defense strategies against ransomware, such as real-time analysis and automatic policy generation. In anomaly detection, LLMs can identify suspicious behaviors that may compromise data integrity, with little human intervention.
- Data Confidentiality (C): Prevents unauthorized access to sensitive information. LLMs can be used for data anonymization by replacing personally identifiable information (PII) with generic tokens to protect user privacy. In addition, ChatGPT has been used to help non-experts implement encryption algorithms, thereby protecting data confidentiality.
- Data Reliability (R): Ensures data accuracy. LLMs have shown high precision and recall in detecting phishing websites and phishing emails, with performance even surpassing humans.
- Data Traceability (T): Tracks the source and history of data. In digital forensics, LLMs can be used to analyze logs, memory dumps, and other operating system artifacts. For intellectual property protection, digital watermarking techniques are used to embed imperceptible signals in LLM outputs to track content usage and prevent plagiarism and misuse.
Finding III: LLMs perform exceptionally well in data protection, often outperforming existing solutions while requiring less human intervention. Across various security applications, ChatGPT is the most widely used LLM model.
Negative Impacts (Evil)
This section examines the offensive applications of LLMs and classifies them into five categories based on their position in the system architecture.
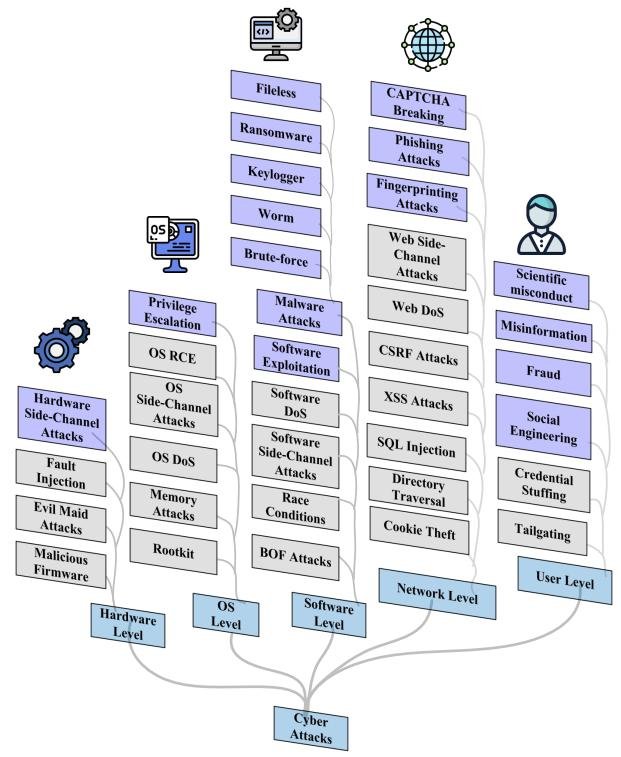
Summary of the Taxonomy
This paper divides LLM-based cyberattacks into five levels:
- Hardware-Level Attacks: Although LLMs cannot directly access hardware physically, they can analyze hardware-related side-channel information leakage to infer secret information such as keys.
- OS-Level Attacks: LLMs lack the low-level system access required to carry out OS-level attacks. However, they can be used to analyze information collected from the OS to assist attacks. Existing studies have shown how LLMs can analyze virtual machine states, identify vulnerabilities, and automatically execute attacks.
- Software-Level Attacks: The most common software-level attack is using LLMs to create malware. Studies show that LLMs are good at building malware modules from functional descriptions and can generate multiple malware variants that evade antivirus detection.
- Network-Level Attacks: LLMs are widely used to launch phishing attacks by generating highly personalized and convincing phishing emails to increase click-through rates. In addition, LLMs may also break CAPTCHA challenges used to distinguish humans from machines.
- User-Level Attacks: This is the most prevalent type of attack. LLMs can generate extremely convincing but false content and associate seemingly unrelated information, making them useful for a variety of malicious activities.
- Misinformation: False content generated by LLMs is harder to detect and may use more deceptive styles.
- Social Engineering: LLMs can infer users’ personal attributes, such as location and income, from seemingly harmless text, and can even directly extract personal information.
- Scientific Misconduct: LLMs can generate coherent original text and even complete academic papers, posing a major challenge for detecting academic misconduct.
- Fraud: Tools designed specifically for cybercrime, such as FraudGPT and WormGPT, have emerged. They lack safety guardrails and can be used to generate fraudulent emails and plan attacks.
Finding IV: User-level attacks are the most prevalent, mainly due to LLMs’ increasingly human-like reasoning abilities, which enable them to generate realistic conversations and content. At present, LLMs have limited access to OS and hardware capabilities, which constrains the prevalence of attacks at other levels.
Vulnerabilities and Defenses of LLMs (Ugly)
This section examines the vulnerabilities of LLMs themselves, the threats they face, and the corresponding defense measures.
Vulnerabilities and Threats of LLMs
This paper categorizes threats against LLMs into two types: AI model inherent vulnerabilities and non-AI model inherent vulnerabilities.
- AI Model Inherent Vulnerabilities: These vulnerabilities stem from the characteristics of machine learning models themselves.