A Survey on Efficient Large Language Model Training: From Data-centric Perspectives
-
ArXiv URL: http://arxiv.org/abs/2510.25817v1
-
Authors: Jingyang Yuan; Rong-Cheng Tu; Yiqiao Jin; Wei Ju; Yifan Wang; Xiao Luo; Ming Zhang; Nan Yin; Zhiping Xiao; Bohan Wu; and 11 others
-
Publishing Institutions: Georgia Institute of Technology; HKUST; Nanyang Technological University; Peking University; University of California; University of International Business and Economics; University of Washington
Introduction
Post-training of Large Language Models (LLMs) has become a critical stage for unlocking their domain adaptation capabilities and task generalization potential. This stage effectively enhances the model’s abilities in long-context reasoning, human alignment, instruction fine-tuning, and domain-specific adaptation.
However, in the post-training stage of LLMs, data, as the core driving force behind model evolution, is facing a severe “data challenge”: the cost of manually annotating high-quality data is rising rapidly, while the marginal gains from simply scaling up data are diminishing. In addition, static datasets inherently limit the model’s ability to adapt to ever-changing real-world knowledge. The linear dependence between data volume and model performance fundamentally stems from the inefficient use of data in traditional post-training paradigms.
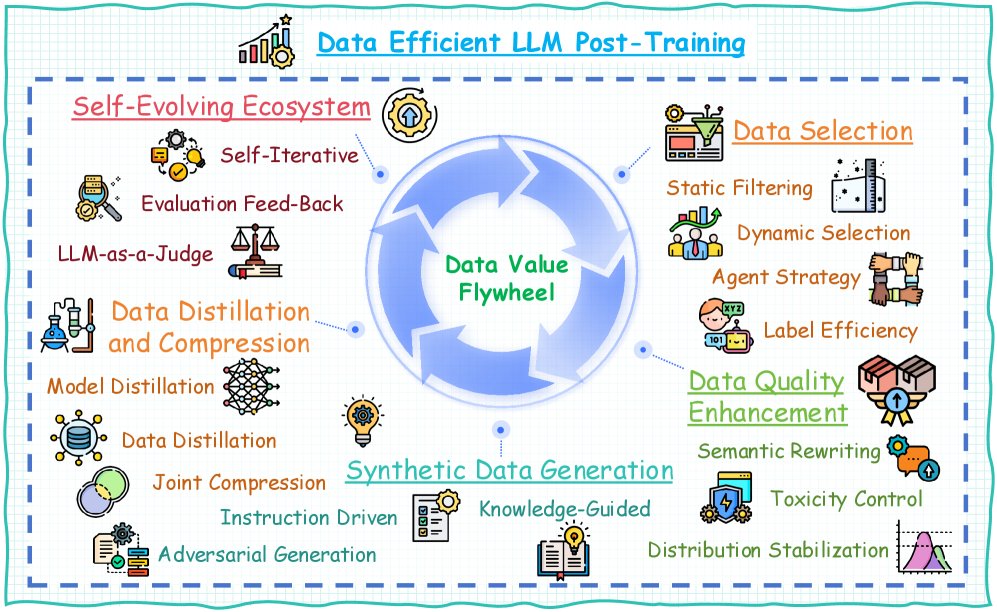
Researchers have explored various methods to fully tap into the data potential in LLM post-training, but the field still lacks a comprehensive survey. This article presents the first systematic survey of data-efficient LLM post-training from a data-centric perspective. Specifically, it proposes the concept of a “data flywheel” (as shown in the figure), which consists of five key components: data selection, data quality enhancement, synthetic data generation, data distillation and compression, and a self-evolving data ecosystem. Based on this framework, this article categorizes existing work, summarizes the key components, and points out future research directions.
Differences from prior surveys: Although existing surveys have examined certain aspects of LLM post-training, such as data selection, synthetic data generation, model self-feedback, self-evolution, trustworthiness, and time efficiency, these studies mainly focus on individual components rather than an overall perspective. This survey systematically examines these methods through the lens of data efficiency, filling the gap and providing key insights for maximizing data value extraction.
Taxonomy
This section divides data-efficient LLM post-training methods into five core categories:
- Data Selection: ❶ Static Filtering: offline selection based on intrinsic data properties; ❷ Dynamic Selection: adaptive weighting based on model uncertainty; ❸ Agent Strategy: multi-model voting for reliable selection; ❹ Labeling Efficiency: combining active learning and semi-supervised strategies to cover samples at low cost.
- Data Quality Enhancement: ❶ Semantic Rewriting: enhancing expression diversity through meaning-preserving transformations and generating variants while keeping the original intent; ❷ Toxicity Control: correcting harmful content; ❸ Distribution Stabilization: adjusting data characteristics to improve robustness.
- Synthetic Data Generation: ❶ Instruction-driven: model-generated instruction-response pairs; ❷ Knowledge-guided: generation combined with structured knowledge; ❸ Adversarial Generation: producing challenging samples.
- Data Distillation and Compression: ❶ Model Distillation: transferring the output distribution of large models to smaller models while preserving key knowledge; ❷ Data Distillation: extracting high-information-density samples to build compact datasets equivalent to the full data; ❸ Joint Compression: combining model architecture compression with data selection strategies to achieve end-to-end efficiency optimization.
- Self-Evolving Data Ecosystems: ❶ Self-Iterative Optimization: using the current model to generate new data; ❷ Dynamic Evaluation Feedback: real-time monitoring and adjustment; ❸ LLM-as-a-Judge: feedback-driven data optimization.
The table below compares the performance of these five categories across key dimensions, where more “+” signs indicate higher requirements or better performance.
| Method Category | Data Efficiency | Computational Demand | Model Capability Dependence | Quality Requirement | Domain Adaptability |
|---|---|---|---|---|---|
| Data Selection | +++ | ++ | + | +++ | ++ |
| Data Quality Enhancement | ++ | ++ | ++ | ++ | ++ |
| Synthetic Data Generation | ++ | +++ | +++ | + | +++ |
| Data Distillation and Compression | +++ | ++ | +++ | ++ | ++ |
| Self-Evolving Data Ecosystems | ++ | +++ | +++ | + | +++ |
These five dimensions complement one another: selection filters high-quality data, enhancement improves data utility, generation expands data coverage, distillation condenses knowledge, and self-evolution enables continuous improvement. Together, they pursue the goal of maximizing model performance with minimal data requirements.
Data Selection
Data selection is crucial for improving the efficiency of LLM post-training by identifying high-value data subsets. As shown in the figure below, this article divides existing methods into four dimensions: (1) static filtering based on intrinsic data properties, (2) dynamic selection that adapts during training, (3) Agent strategies using collaborative mechanisms, and (4) labeling efficiency achieved through human-machine collaboration.
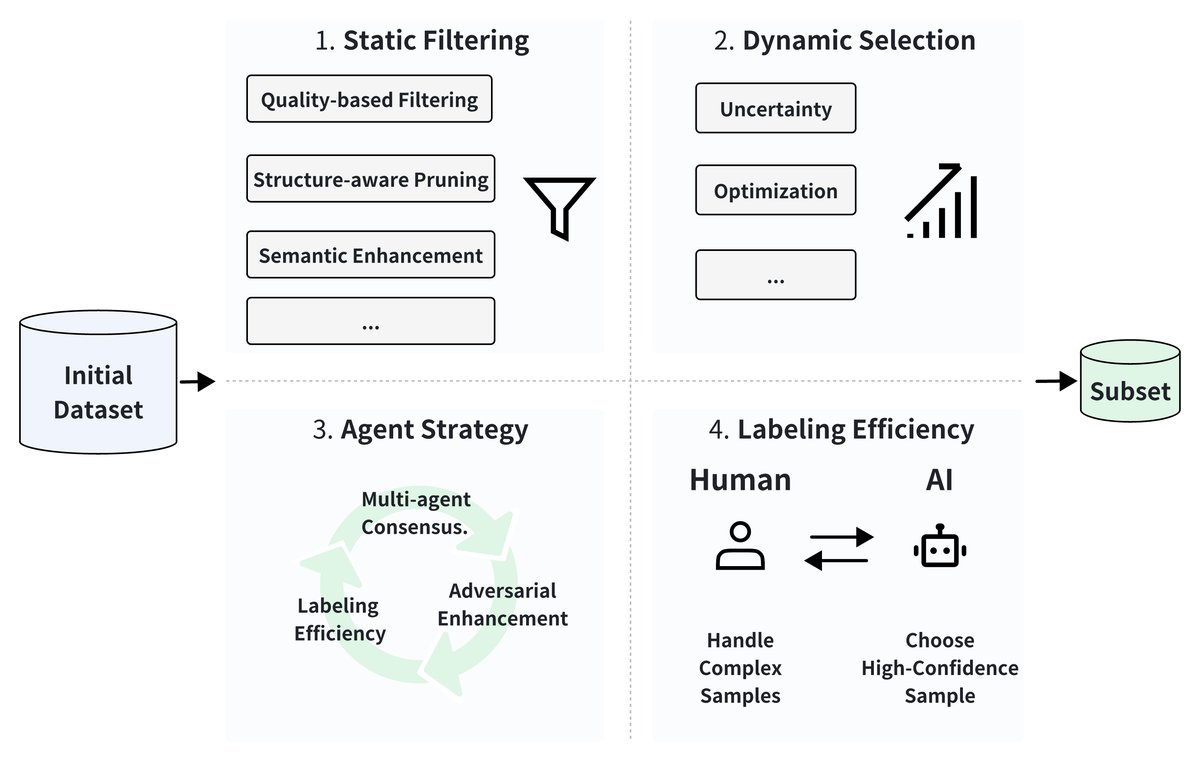
Static Filtering
Static filtering identifies samples with high information density and representativeness by evaluating intrinsic data properties offline.
- Quality-based filtering: Alpagasus achieved comparable performance using only 17% of the original data through complexity-based filtering (instruction length, diversity, and perplexity). MoDS adopts multi-dimensional metrics and density peak clustering, while other work uses KL-divergence-driven selection to align domain distributions. Information-theoretic methods leverage entropy measures (such as negative log-likelihood and inverse term frequency) to identify redundant samples.
- Semantic enhancement: LIFT improves instruction quality through automatic revision. InsTag proposes fine-grained instruction tagging to analyze diversity and complexity in supervised fine-tuning datasets, showing that model capability grows as the data becomes more diverse and more complex.
Dynamic Selection
Dynamic methods adaptively adjust data weights by evaluating each sample’s importance to the model.
- Uncertainty-driven selection: Active Instruction Tuning prioritizes high-uncertainty tasks by predicting entropy. Self-Guided Data Selection uses Instruction Following Difficulty (IFD) to measure loss variance and removes easy-to-learn samples.
- Optimization-based selection: Sample-efficient alignment uses Thompson sampling to maximize each sample’s contribution in preference alignment tasks. P3 integrates strategy-driven difficulty assessment, pace-adaptive selection, and diversity promotion through a Determinantal Point Process.
Agent Strategies
Agent-based methods leverage collaborative mechanisms for reliable data selection.
- Multi-Agent Consensus: Multi-Agent methods such as CLUES implement a multi-model voting mechanism based on training dynamics and gradient similarity metrics.
- Adversarial Enhancement: DATA ADVISOR uses red-team intelligent agents for safety filtering, while Automated Data Curation optimizes data through a generator-discriminator framework.
Labeling Efficiency
These methods effectively optimize the labeling process through iterative human-machine collaboration.
- Human-AI collaboration: Methods such as LLMaAA use LLMs as annotators, combined with uncertainty sampling. CoAnnotating achieves an uncertainty-based division of labor between humans and AI.
- Automated generation: SELF-INSTRUCT enables the model to autonomously generate instruction data.
- Workflow optimization: Recent work has established scalable and efficient annotation workflows through adaptive experimental design and systematic curation systems.
Discussion
Current data selection methods face challenges in aligning static metrics with dynamic model needs, managing the computational complexity of the optimization process, and achieving cross-domain generalization. Future research directions point to meta-learning-based selection frameworks, causal inference for sample analysis, and efficiency-aware optimization that takes hardware constraints into account.
Data Quality Enhancement
As shown in the figure below, improving data quality is crucial for maximizing the effectiveness of LLM post-training. Through semantic refinement, toxicity control, and distribution stabilization, researchers aim to improve the informativeness, safety, and robustness of training data. This article categorizes existing methods into three directions.
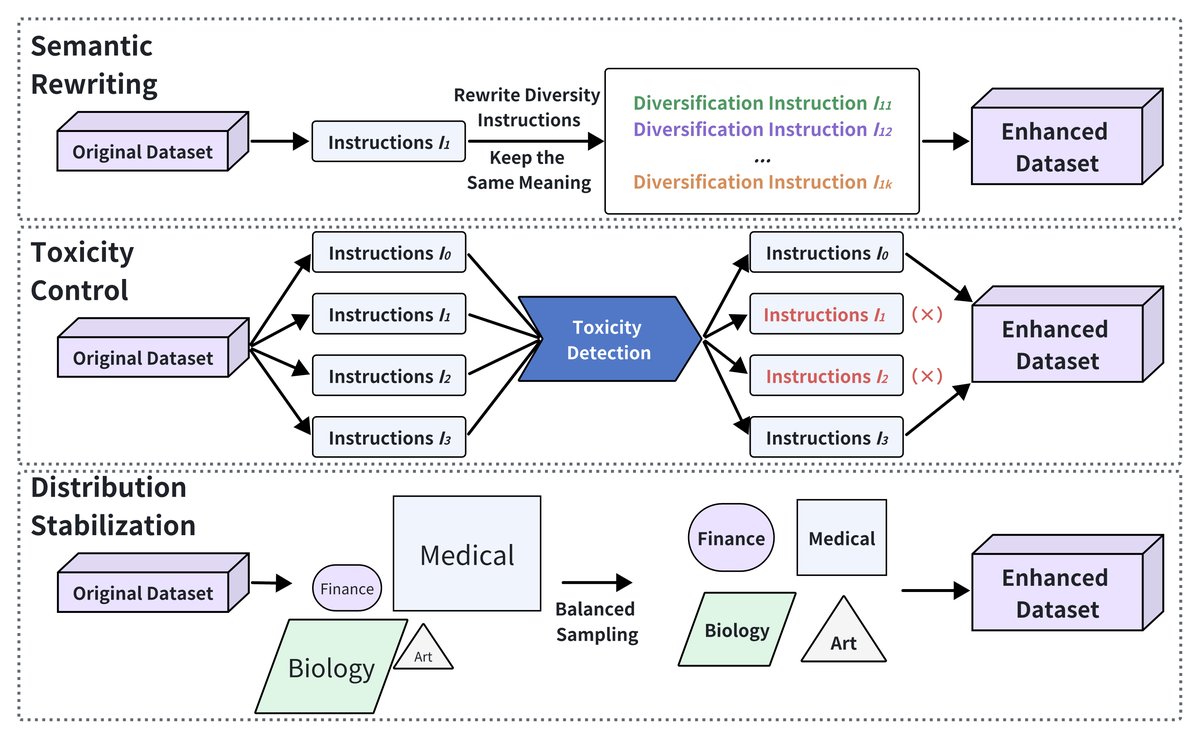
Semantic Rewriting
Semantic rewriting focuses on increasing data diversity through controlled transformations while preserving the original meaning.
- Instruction refinement: CoachLM automatically revises complex instructions to reduce ambiguity, while other work uses structured prompt chains to generate paraphrases and enhance the model’s cross-task generalization ability.
- Domain-specific augmentation: Methods such as PGA-SciRE inject structured knowledge into scientific relation extraction tasks, enabling the model to adapt to specialized tasks.
- Automated augmentation: AutoLabel seamlessly integrates human feedback for high-quality rewriting. LANCE enables LLMs to autonomously generate, clean, review, and annotate data, acting as a continuously self-evolving data engineer.
Toxicity Control
Mitigating harmful content is a key part of data quality enhancement.
- Detection frameworks: Some methods effectively distill toxicity knowledge into compact detectors, or strategically leverage generative prompts for zero-shot toxicity classification.
- Adversarial benchmarks: Frameworks such as TOXIGEN and ToxiCraft generate adversarial datasets to stress-test models. Studies have found that smaller models often exhibit lower toxicity rates.
- Human-AI collaboration: Research shows that human intervention, especially through counterfactual data augmentation, can significantly improve the quality of toxicity detection.
Distribution Stabilization
Stabilizing data distributions ensures that models generalize well across different tasks and domains.
- Imbalance mitigation: Methods such as Synthetic Oversampling and Diversify and Conquer effectively address class imbalance through adaptive synthetic sample generation.
- Noise reduction: Multi-News+ significantly reduces annotation errors through automatic label correction. RobustFT introduces a comprehensive framework that handles noisy response data through multi-expert collaborative noise detection and context-enhanced relabeling strategies.
- Domain adaptation: RADA addresses tasks in low-resource domains by retrieving relevant instances from other datasets and generating context-enhanced samples via LLM prompts. Advanced methods such as Dynosaur and Optima leverage curriculum learning and multi-source coordination.
Discussion
Semantic rewriting, toxicity control, and distribution stabilization are key strategies for improving the quality of LLM post-training data. Future work should integrate these methods into a unified framework to maximize data diversity and model performance while reducing costs.
Synthetic Data Generation
Generating synthetic training data is a powerful strategy for overcoming data scarcity and enhancing the robustness of LLM post-training. As shown in the figure below, synthetic data generation methods can be divided into three categories: instruction-driven generation, knowledge-guided generation, and adversarial generation.
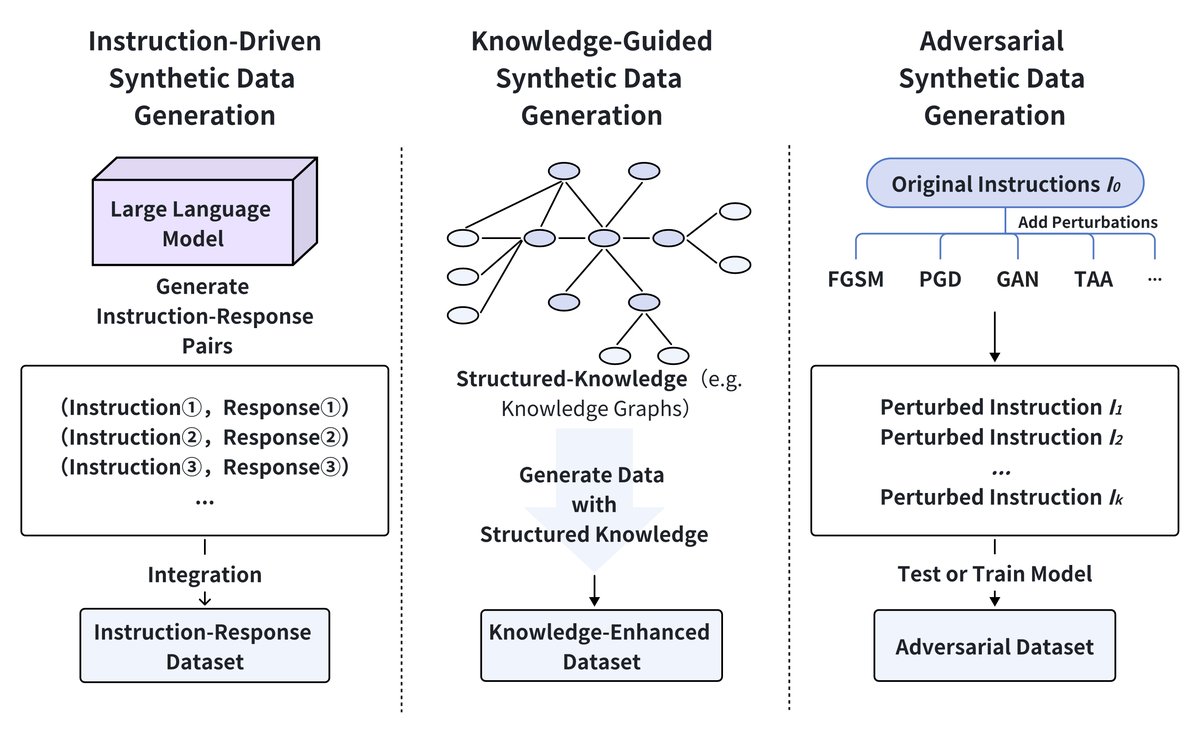
Instruction-Driven Synthetic Data Generation
Instruction-driven methods leverage LLMs’ ability to directly generate new samples from task prompts. For example, SynPO generates preference pairs for alignment tasks, Magpie enables template-free instruction generation, while other work synthesizes proof steps, significantly improving GPT-4’s proof capabilities.
Knowledge-Guided Synthetic Data Generation
Knowledge-guided methods integrate external knowledge to guide data generation.
- Theoretical frameworks: Some studies rigorously establish the reverse-bottleneck theory, linking data diversity to improved model generalization.
- Structured data synthesis: HARMONIC combines privacy-preserving tabular data generation. Other methods improve relation consistency through pattern-aware fine-tuning.
- Cost-effective strategies: Hybrid generation methods can reduce API costs by 70% while maintaining data utility. Source2Synth improves factual accuracy through knowledge graph alignment.
Adversarial Generation
Adversarial generation methods systematically probe model vulnerabilities to enhance robustness. For example, one work uses agent-based simulation to generate edge cases, reducing error rates on dialectal variations by 19%; another introduces contrastive unlearning to address data defects; ToxiCraft generates subtle harmful content, revealing significant gaps in commercial safety filters.
Discussion
Each method has its trade-offs: instruction-driven methods scale quickly but risk semantic drift; knowledge-guided methods preserve fidelity through structured constraints; adversarial generation enhances robustness by exposing vulnerabilities. Future work should combine the strengths of these methods while continuing to focus on optimizing generation costs and developing theoretical foundations.
Data Distillation and Compression
Data distillation and compression techniques improve the efficiency of LLM post-training by reducing data complexity while preserving performance. As shown in the figure below, this includes three complementary approaches: model distillation for knowledge transfer, data distillation for dataset compression, and joint compression for unified optimization.
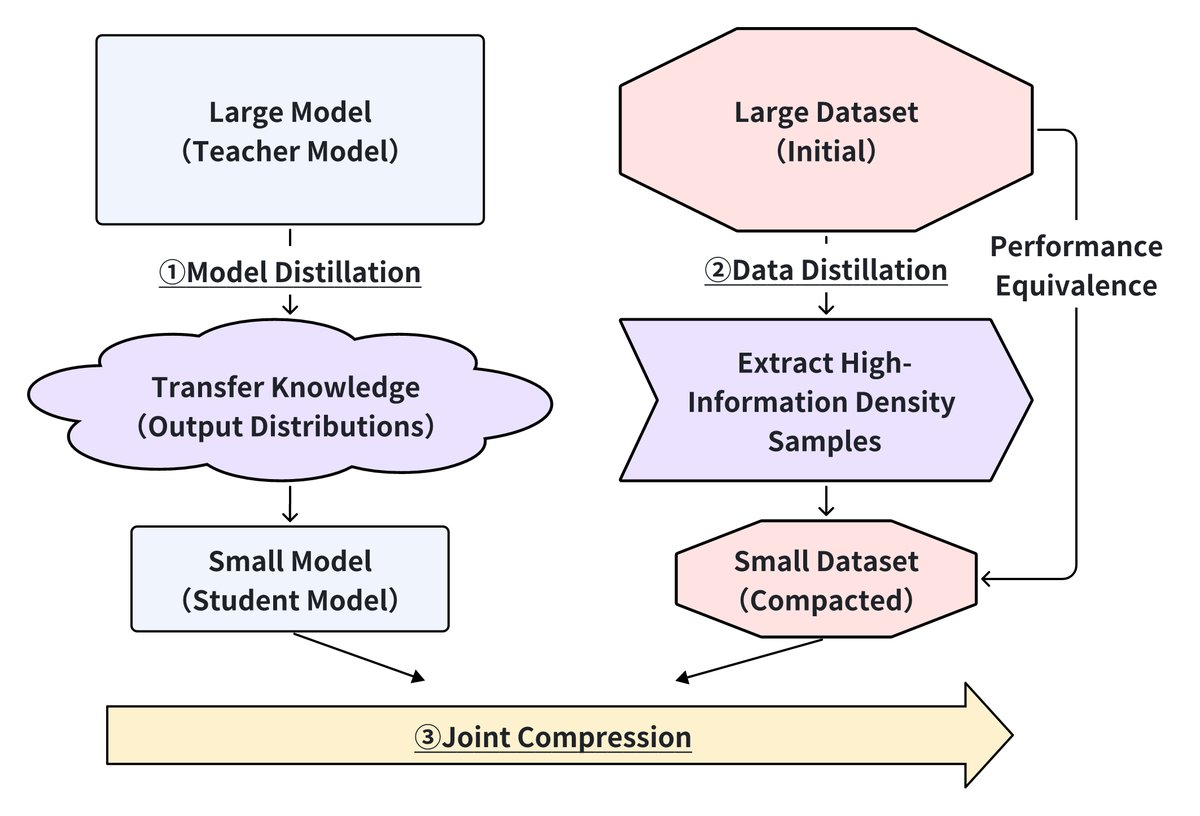
Model Distillation
Model distillation transfers knowledge from large teacher models to smaller student models while preserving performance. Recent advances include Impossible Distillation, which can create high-quality student models from low-quality teacher models; and Cross-Tokenizer Distillation, which enables knowledge transfer across different architectures through universal logit distillation. For edge deployment, XAI-driven distillation and BitDistiller produce interpretable models and achieve sub-4-bit precision, respectively.
Data Distillation
Data distillation focuses on selecting high-information-density samples to create compact yet representative datasets. Studies show that LLM-generated labels can effectively train classifiers comparable to human annotations. LLMLingua-2 achieves prompt compression through token-level distillation. Domain-specific applications include Self-Data Distillation for model fine-tuning and multi-teacher distillation for medical data integration.
Joint Compression
Joint compression combines model compression with data selection to optimize overall efficiency. Some work jointly optimizes structured pruning and label smoothing, compressing LLaMA-7B to 2.8B parameters with minimal performance loss. Efficient Edge Distillation achieves adaptive width scaling on edge devices through supernet training. In recommender systems, Prompt Distillation aims to align ID-based and text-based representations to reduce inference time.
Discussion
These three methods offer complementary advantages for improving LLM efficiency: model distillation optimizes architecture, data distillation selects high-impact samples, and joint compression unifies model and data optimization. Future research should focus on integrating these methods, especially for edge AI and low-resource application scenarios.
Self-Evolving Data Ecosystems
Self-evolving data ecosystems strategically optimize LLM post-training through autonomous data generation, real-time feedback, and continuous learning. As shown in the figure below, this ecosystem forms a closed loop of generation, evaluation, and adaptive training. This article discusses its three key components: self-iterative optimization, dynamic evaluation feedback, and LLM as judge.
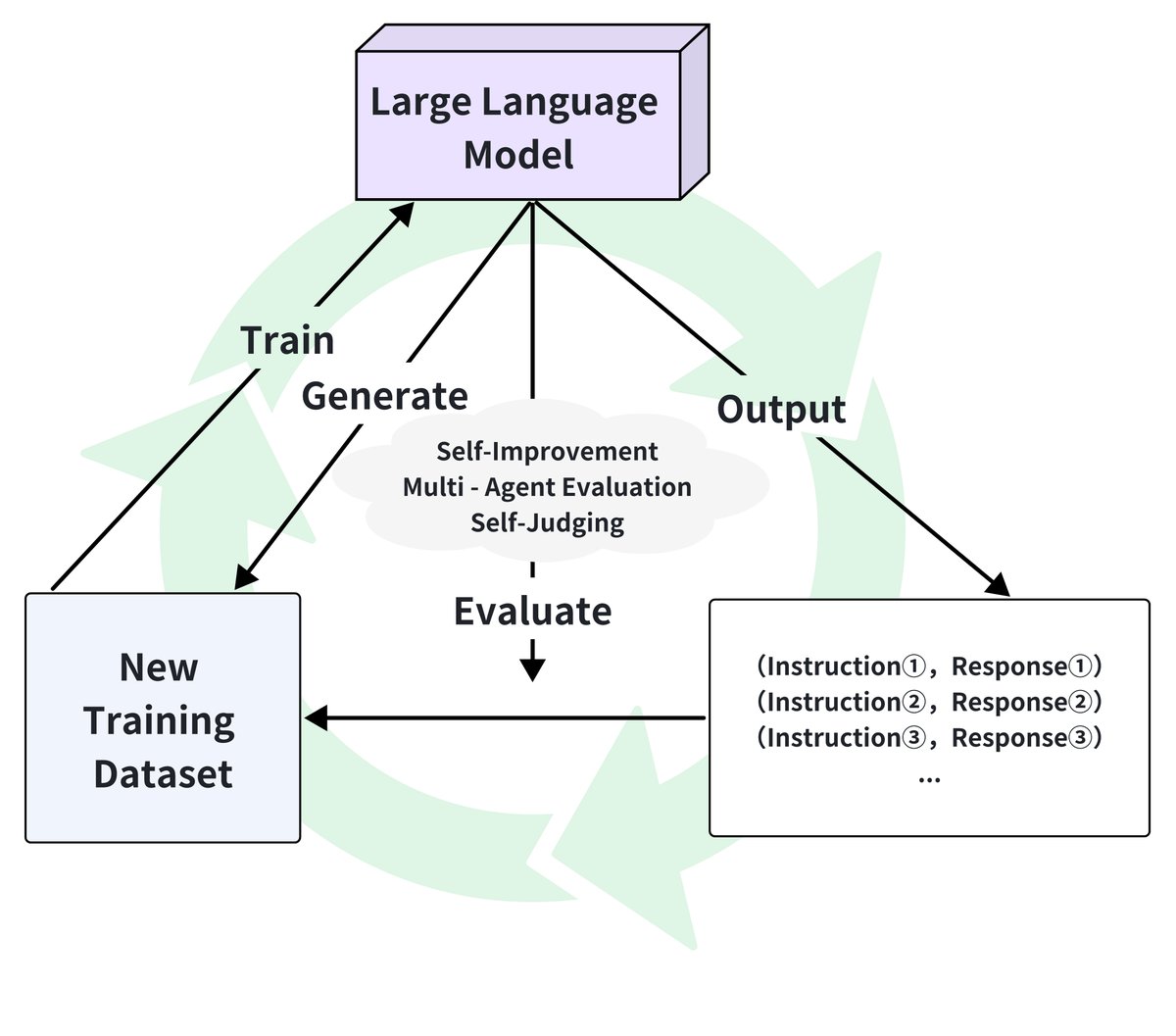
Self-Iterative Optimization
Self-iterative optimization enables LLMs to use their own outputs to generate new training data, thereby autonomously improving their capabilities.
- Self-improvement methods: Methods such as Self-Rewarding, Self-Refine, and Self-Boosting enable models to improve autonomously through iterative self-optimization. Self-Play Fine-Tuning leverages competitive self-interaction and outperforms traditional methods such as DPO.
- Semi-supervised self-evolution: SemiEvol addresses post-training adaptation in scenarios with limited labeled seed data and large amounts of unlabeled domain data through a propagation-selection framework.
- Knowledge retention: MemoryLLM can preserve existing knowledge while integrating new data, enabling continuous model updates.
Dynamic Evaluation Feedback
The dynamic evaluation feedback system allows the model to make real-time adjustments based on its performance, dynamically optimizing its outputs.
- Multi-agent evaluation: The Benchmark Self-Evolving Framework and LLM-Evolve use multi-agent systems to dynamically evaluate and adjust LLM performance, ensuring continuous evolution across multiple benchmarks.
- Iterative refinement: Self-Refine and Self-Log use feedback loops for iterative refinement and log parsing, optimizing model outputs without external retraining.
- Improved decision-making: Meta-Rewarding and Self-Evolved Reward Learning leverage iterative feedback from their outputs to improve judgment ability, ensuring more accurate decisions in complex tasks.
LLM-as-a-Judge
The “LLM-as-a-Judge” system represents a paradigm shift from external evaluation to self-evaluation, in which the model evaluates its own or other models’ outputs.
- Self-improvement through judging: Self-Taught Evaluators train judging ability by generating synthetic comparison data without human data. JudgeLM, meanwhile, creates specialized evaluation models by fine-tuning on human preferences.
- Debiased evaluation systems: CalibraEval mitigates position bias by recalibrating prediction distributions. Crowd Score uses multiple AIs within a single model to simulate diverse human judgments, reducing individual bias through aggregation.
- Adversarial robustness testing: TOXIGEN and ToxiCraft create increasingly subtle harmful content to expose model blind spots. R-Judge specifically targets situational safety risks in interactive environments, rather than just the harmfulness of the content itself.
Discussion
The combination of self-iterative optimization, dynamic evaluation feedback, and LLM-as-a-Judge creates a powerful framework for autonomous LLM improvement. Although these methods show great potential in reducing human intervention, future work should focus on unifying them into a scalable framework and enabling them to generalize across different tasks.
Challenges and Future Directions
-
Domain-driven data synthesis and refinement Although general-purpose models are often used for data generation, domain-specific models can better capture specialized knowledge. Future work should explore using domain-specific pre-trained models to generate specialized data, combined with refinement techniques to optimize data quality while reducing annotation costs.
-
Scalability of large-scale data synthesis As LLM pretraining demands ever larger and higher-quality datasets, efficient large-scale data generation becomes crucial. Current data synthesis and augmentation methods face scalability bottlenecks. Future work should focus on developing parallel, cost-effective data generation frameworks to meet the needs of large-scale pretraining while maintaining a balance between data diversity and relevance.
-
Reliable quality evaluation metrics Current evaluation frameworks lack standardized metrics for measuring the quality of synthetic data. Future research needs to develop more comprehensive evaluation systems that consider not only grammar and fluency, but also factual accuracy, logical consistency, and stylistic diversity, to ensure that the generated data can truly improve model performance.