A Survey of Weight Space Learning: Understanding, Representation, and Generation
Model as Data! NVIDIA Leads the Way, Interpreting the New Frontiers of AI from Three Dimensions: Weight Space Learning

In today’s AI world, it feels as if we are living in a “Model Zoo” made up of massive pre-trained models. From the GPT series to Stable Diffusion, countless powerful models have been created and shared.
ArXiv URL:http://arxiv.org/abs/2603.10090v1
We usually regard the weights of these models as the end point of training. But have you ever wondered what would happen if we flipped that perspective?
What if these hundreds of millions of parameters themselves were a new kind of data, rich in information?
Recently, a survey jointly released by NVIDIA, the University of California, San Diego, and other top institutions has, for the first time, laid out a complete blueprint for this emerging field. It proposes a disruptive concept: Weight Space Learning (WSL), which advocates studying model weights themselves as a learnable, structured domain.
This survey systematically reviews the current state of the field and divides it into three core dimensions, opening the door to a new world of “model as data.”
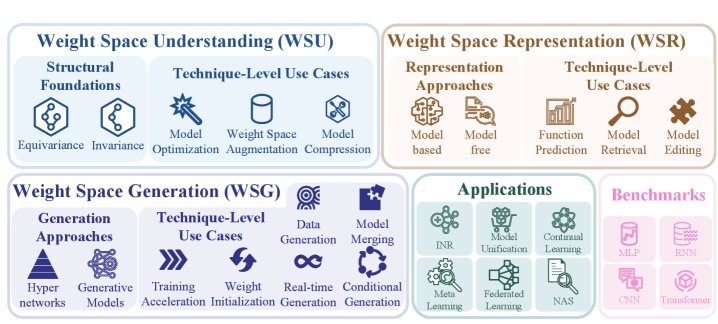
Figure 1: Overview of the Weight Space Learning (WSL) survey
What Is Weight Space Learning (WSL)?
Simply put, WSL no longer focuses only on data, features, or model architectures, but instead turns the lens of machine learning directly onto the model parameters (weights) themselves.
It tries to answer a fundamental question:
Can we learn directly from tens of thousands of trained models, so as to analyze, compare, and even generate entirely new models?
This survey summarizes this emerging paradigm into three interconnected dimensions:
-
Weight Space Understanding (WSU): studying the intrinsic geometric structure and symmetries of weight space.
-
Weight Space Representation (WSR): learning compact, meaningful “embedding” representations for model weights.
-
Weight Space Generation (WSG): directly synthesizing new network weights through auxiliary models.
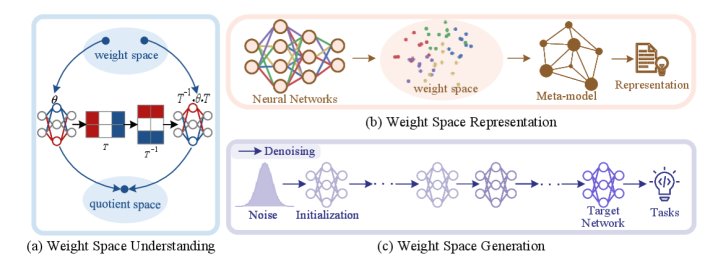
Figure 2: Conceptual diagram of the three core dimensions of WSL
Next, let’s take a closer look at these three fascinating dimensions one by one.
Weight Space Understanding (WSU): Decoding the “Grammar” of Model Parameters
WSU aims to reveal the inherent “physical laws” of neural network weight space. It finds that weight space is not a random mess, but is full of subtle structure, the most important of which is symmetry.
This is mainly reflected in two aspects:
1. Functional Invariance
Imagine expressing the same meaning in two different ways. A similar phenomenon exists in weight space as well.
Due to redundancy in network structure, many different weight configurations ($\theta$) can actually produce exactly the same model function ($f$).
\[f(\rho_{in}(\theta);x)=f(\theta;x)\]The most typical example is neuron permutation invariance: in a fully connected layer, swapping the positions of any two neurons and their corresponding connection weights leaves the network’s final output unchanged.
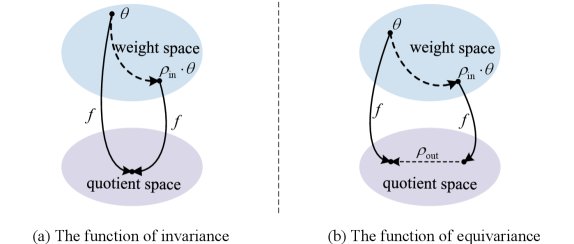
Figure 4: Illustration of weight space symmetry
Understanding this invariance allows us to identify and remove redundant parameters in a model, providing a theoretical basis for model compression. At the same time, it also explains why optimizers can always find broad “valleys” of optimal solutions on the loss landscape, because the optimum is not a single point, but a manifold formed by equivalent weights.
2. Functional Equivariance
If invariance means “changed, but not completely changed,” then equivariance means “changed in a rule-based way.”
It refers to the fact that a structured transformation applied to the weights will cause the model’s function to undergo a predictable, corresponding change.
\[f(\rho_{in}(\theta);x)=\rho_{out}(f(\theta;x))\]This property reveals the intrinsic connections among model families. By leveraging equivariance, we can design meta-models capable of model editing or inference across architectures, providing a “geometric map” for navigating the model universe.
Weight Space Representation (WSR): Giving Every Model a “Digital ID”
After understanding the intrinsic structure of weights, we naturally ask: can a complete neural network be compressed into a low-dimensional vector, like issuing each model a “digital ID”?
That is the goal of Weight Space Representation (WSR). It learns a mapping function $\phi$ that maps high-dimensional weights $\theta$ to a compact embedding vector $z$.
\[z=\phi(\theta)\]With this embedding vector $z$, we can directly predict model performance, retrieve functionally similar models, and even edit models without accessing the original training data.
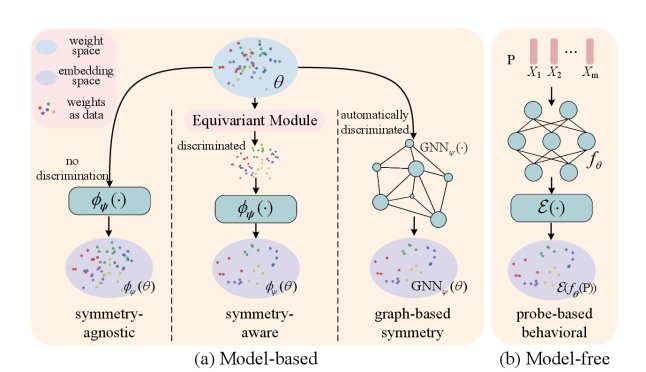
Figure 5: Main methods of Weight Space Representation (WSR)
There are two main categories of methods for implementing WSR:
1. Model-based methods
These methods take the weight tensor directly as input and learn its representation through an encoder model. Their development reflects a progressively deeper understanding of weight symmetry:
-
Symmetry-agnostic: early methods simply “flattened” weights into a vector, ignoring structural information.
-
Symmetry-aware: later work began designing special network structures, such as Deep Sets for processing sets, to manually encode prior knowledge like neuron permutation invariance.
-
Graph-based methods: the latest trend is to treat the neural network itself as a computation graph, then use graph neural networks (GNNs) to automatically learn its structural symmetries, achieving stronger generalization.
2. Model-free methods
These methods take a different path: instead of looking directly at the model’s weights, they characterize the model by observing its behavior.
Specifically, they feed the model a set of carefully designed “probes” and record its output responses to build a behavioral signature.
\[z=\mathcal{E}\big(\{f\_{\theta}(x\_{i})\}\_{x\_{i}\in\mathcal{P}}\big)\]The advantage of this approach is that it naturally bypasses all weight-related symmetry issues and is architecture-agnostic, making it possible to analyze even “black-box” models whose weights are inaccessible.
Weight Space Generation (WSG): From “Understanding” to Creating New Models
The most exciting direction in WSL is undoubtedly Weight Space Generation (WSG). It not only aims to understand and represent models, but also to directly generate new model weights “out of thin air.”
That may sound like science fiction, but there are already concrete technical paths:
-
Hypernetworks: train a small network (a hypernetwork) to generate the weights of another large network (the main network). This has shown great potential in neural architecture search (NAS) and model personalization.
-
Generative models: inspired by the success of image generation, researchers have begun using diffusion models or GANs to learn the weight distribution of the entire model zoo, and then sample from it to generate new, usable models.
WSG paints a future for us: we may no longer need to start from scratch and spend massive resources training every model; instead, we may be able to efficiently “synthesize” models that meet specific needs, just as we generate images.
Applications and Future of WSL
Weight Space Learning is not just a theoretical exploration; it has already opened new doors for many practical applications:
-
Model retrieval: quickly finding the pre-trained model best suited for a specific task in a vast model marketplace.
-
Continual learning and federated learning: effectively alleviating catastrophic forgetting through model fusion or editing in weight space, or aggregating knowledge while preserving data privacy.
-
Data-free model analysis: predicting performance, robustness, and even fairness using only model weights, without the original data.
This survey systematically organizes the frontier of “Weight Space Learning.” It marks an important paradigm shift: expanding the focus of AI research from “learning data” to “learning the learner (the model) itself.”
Of course, WSL is still in its early stages, and it faces many challenges, especially in scaling to giant models with trillions of parameters. But it undoubtedly provides us with a brand-new and powerful cognitive toolkit for exploring and mastering the increasingly complex universe of AI models.
Interested readers can visit the resource repository maintained by the survey to access more related papers and code:
https://github.com/Zehong-Wang/Awesome-Weight-Space-Learning