A Concise Review of Hallucinations in LLMs and their Mitigation
Ending AI Hallucinations: A Comprehensive Analysis of the Root Causes of Large Models “Talking Nonsense” and How to Address Them

Have you ever been stunned by AI’s dead-serious nonsense? When it generates an article that looks perfect at first glance but gets key facts completely wrong; or when it answers a question by confidently inventing a concept that does not exist. This phenomenon is one of the biggest challenges facing current large language models (LLM) — hallucination (Hallucination).
ArXiv URL:http://arxiv.org/abs/2512.02527v1
It hangs over the halo of artificial intelligence like a shadow, seriously undermining model reliability. So where do AI hallucinations come from, and how should we deal with them? Today, let’s follow a recent survey paper and get to the bottom of it.
What Is AI Hallucination?
Simply put, AI hallucination refers to a model generating content that seems reasonable and fluent, but is actually factually incorrect, logically inconsistent, or entirely fabricated.
Researchers broadly divide hallucinations into two categories:
-
Factual Hallucination: This is the most common type, where the model provides false or incorrect information. For example, it might say, “Einstein won the Nobel Prize in Physics in 2001.”
-
Logical Hallucination: This refers to content generated by the model that is internally contradictory or logically incoherent. For example, in one passage it may say A is greater than B, and later say B is greater than A.
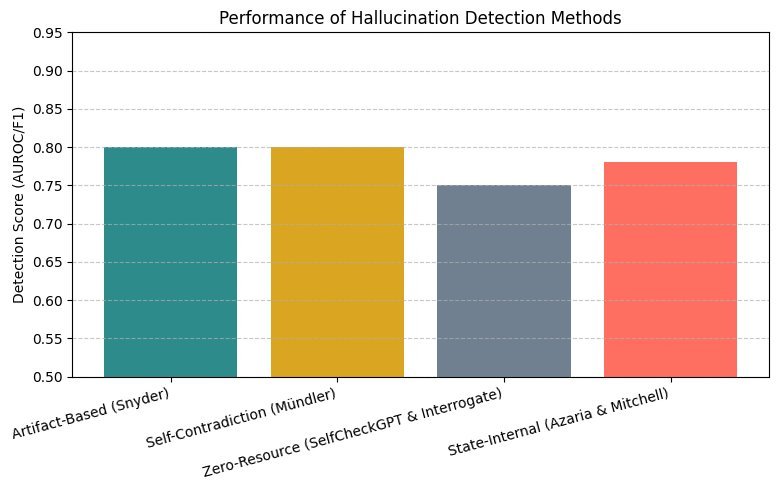
These hallucinations not only mislead users, but also create huge risks in high-stakes domains such as healthcare and finance. Imagine if an AI model used for medical diagnosis hallucinates — the consequences would be disastrous.
Why Do LLMs Produce Hallucinations?
Hallucinations are not something AI does “on purpose”; rather, they are the result of the combined effects of its underlying mechanisms and training data. The main root causes are as follows:
-
The “original sin” of training data: LLMs learn from the vast internet, which contains a large amount of incorrect, outdated, and even contradictory information. During training, the model inevitably absorbs this “noise” as well.
-
Limitations of the model architecture: Generative models like the GPT series are fundamentally designed to predict the next most likely token. They care more about fluency and relevance than factual accuracy. As a result, they may “make up” facts just to produce a smooth sentence.
-
The static nature of knowledge: Once a model is trained, its internal knowledge is fixed. It cannot perceive new knowledge or facts that change after the training cutoff date, which leads to outdated information.
-
Ambiguity in instructions: When a user’s question (Prompt) is vague or ambiguous, the model can only guess and infer in order to provide an answer, greatly increasing the risk of hallucination.
Interestingly, different models also vary in their tendency to hallucinate. For example, GPT-series models excel at generating fluent, coherent text, but are also more likely to “freestyle” and produce factual hallucinations. In contrast, BERT models trained with bidirectional objectives have lower hallucination rates on specific tasks, but their ability to generate new content is relatively limited.
Fighting Hallucinations: What Weapons Do We Have?
To tame this “hallucination beast,” researchers have developed a series of sophisticated strategies. These methods can be summarized into four major categories, forming a multi-layered defense system.
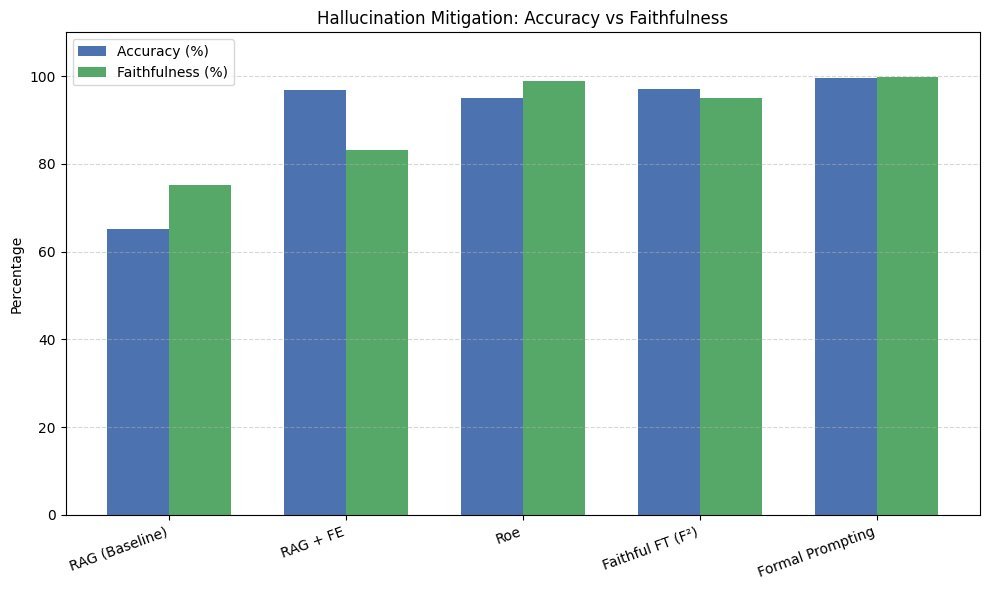
1. Optimizing Training and Fine-tuning
This approach starts from the model itself. By fine-tuning on high-quality, fact-checked datasets, we can “teach” the model to pay more attention to factual accuracy and thereby reduce hallucinations.
2. Introducing External Knowledge
Since the model’s internal knowledge is limited, why not teach it to “look things up”? This is the core idea behind Retrieval-Augmented Generation (RAG). When the model receives a question, it first retrieves relevant information from a reliable knowledge base (such as internal enterprise documents or authoritative databases), and then generates an answer based on that information. This greatly reduces the chance of the model fabricating facts out of thin air.
3. Reinforcement Learning and Feedback
Through Reinforcement Learning from Human Feedback (RLHF), we can teach the model to distinguish between “good answers” and “bad answers.” When the model produces hallucinations, human evaluators provide negative feedback, and through continuous trial, error, and adjustment, the model gradually learns to generate more truthful and reliable content.
4. Carefully Designed Prompts
This is the most direct and effective method on the user side. By designing clear, specific, and information-rich prompts, we can strongly guide the model in the right direction. For example, providing background information in the prompt, specifying the answer format, or asking the model to cite sources can all effectively suppress hallucinations.
These four methods complement one another and together build a strong defense against AI hallucinations.
How Do We Measure the Severity of Hallucinations?
To solve a problem, we first need to measure it. At present, academia is building more comprehensive hallucination evaluation frameworks. This is not just about checking whether facts are right or wrong; it also includes:
-
Consistency analysis: Evaluating whether the internal logic of the model’s generated content is self-consistent.
-
Factuality checks: Comparing the model’s output against trusted knowledge sources.
-
User experience evaluation: Using human evaluators to judge the credibility and usefulness of the generated content.
Through these multi-dimensional evaluations, we can more accurately understand a model’s ability to control hallucinations.
Practical Advice and Future Outlook
So, how should we choose and use LLMs in real-world applications?
The recommendation from the research is: specific task, specific analysis.
-
For scenarios such as general chat or creative writing, where factual accuracy is not critical, models like GPT-4 or PaLM are preferred because of their excellent fluency and creativity.
-
For applications such as information retrieval and knowledge question answering, which require high factual accuracy, models based on BERT or T5 architectures and combined with technologies like RAG may be more reliable.
In the future, research will focus on smarter hallucination detection and correction mechanisms, as well as the development of more transparent AI systems. For example, users could easily question and verify model answers, and even participate in correcting hallucinations.
Conclusion
AI hallucination is an unavoidable challenge on the path of large language model development. It is both a reflection of technical limitations and a necessary step on our way toward more reliable and trustworthy general artificial intelligence.
As this survey shows, academia and industry are “declaring war” on hallucinations from multiple angles, including models, data, algorithms, and applications. This battle is far from over, but every bit of progress brings us one step closer to a future where we can truly trust AI.